Använda Synapse Studio för att övervaka dina Apache Spark-pooler
Med Azure Synapse Analytics kan du använda Apache Spark för att köra notebook-filer, jobb och andra typer av program på Apache Spark-pooler på din arbetsyta.
Den här artikeln beskriver hur du övervakar dina Apache Spark-pooler så att du kan hålla ett öga på statusen för dina pooler, inklusive hur många virtuella kärnor som används av olika arbetsyteanvändare.
Åtkomst till Apache Spark-poollistan
Om du vill se listan över Apache Spark-pooler på din arbetsyta öppnar du först Synapse Studio och väljer din arbetsyta.
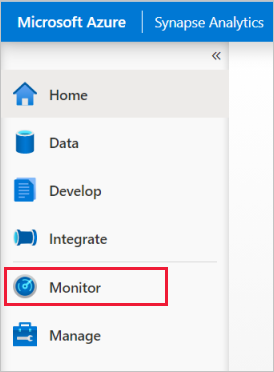
När du har öppnat arbetsytan väljer du avsnittet Övervaka till vänster.
Välj Apache Spark-pooler för att visa listan över Apache Spark-pooler.
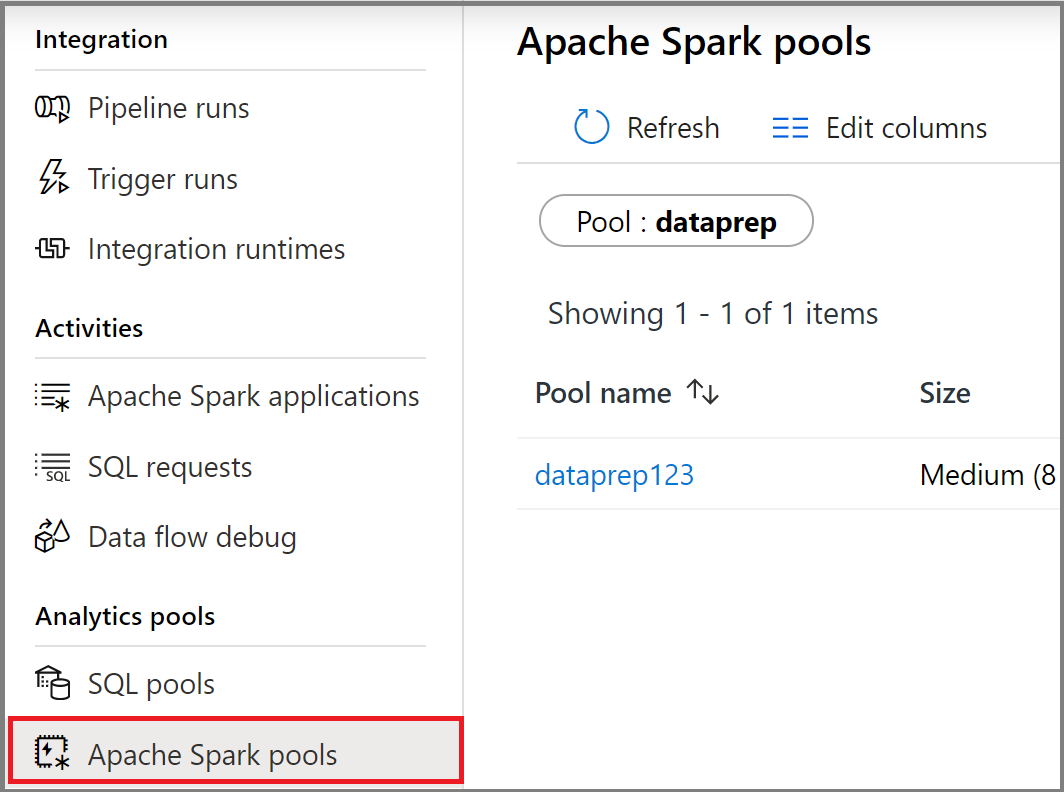
Filtrera dina Apache Spark-pooler
Du kan filtrera listan över Apache Spark-pooler till de som intresserar dig. Med filtren överst på skärmen kan du ange ett fält som du vill filtrera på.
Du kan till exempel filtrera vyn för att endast se De Apache Spark-pooler som innehåller namnet "dataprep":

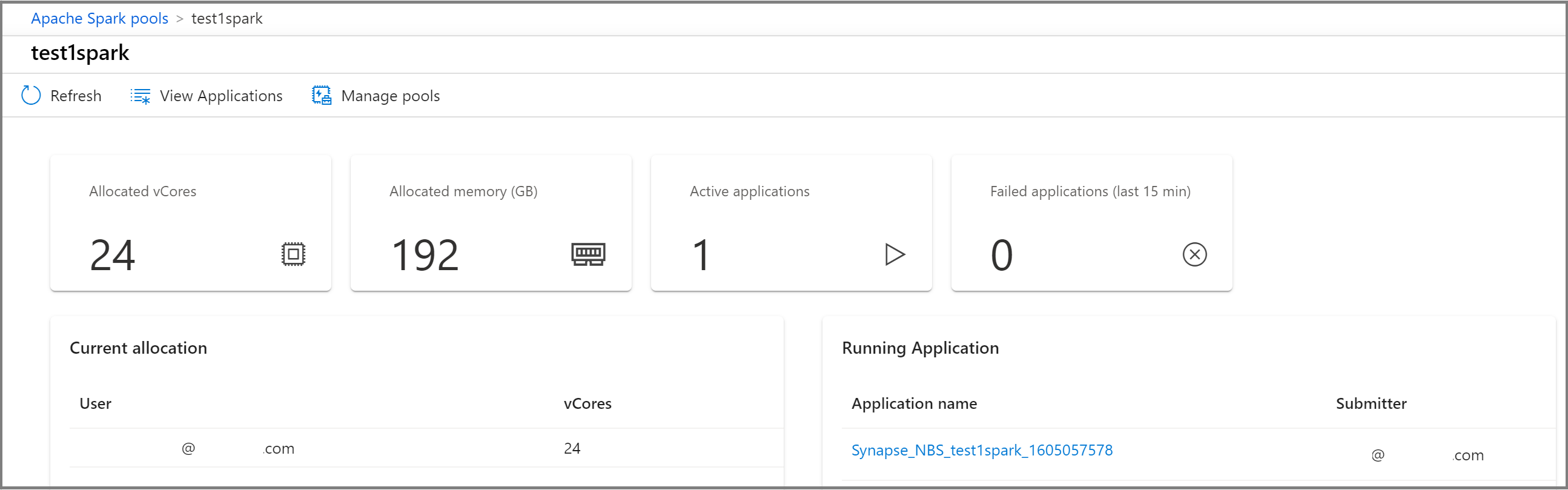
Visa information om en specifik Apache Spark-pool
Om du vill visa information om en av dina Apache Spark-pooler väljer du Apache Spark-poolen för att visa informationen.
Nästa steg
Mer information om hur du övervakar pipelinekörningar finns i artikeln Övervaka pipelinekörningar i Synapse Studio.
Mer information om övervakning av Apache Spark-program finns i artikeln Övervaka Apache Spark-program i Synapse Studio.