Säkerhet, åtkomst och åtgärder för Teradata-migreringar
Den här artikeln är del tre i en serie i sju delar som ger vägledning om hur du migrerar från Teradata till Azure Synapse Analytics. Fokus i den här artikeln är metodtips för säkerhetsåtkomståtgärder.
Säkerhetsfrågor
I den här artikeln beskrivs anslutningsmetoder för befintliga äldre Teradata-miljöer och hur de kan migreras till Azure Synapse Analytics med minimal risk och användarpåverkan.
Den här artikeln förutsätter att det finns ett krav på att migrera befintliga metoder för anslutning och användar-/roll-/behörighetsstruktur i befintligt mått. Om inte använder du Azure Portal för att skapa och hantera ett nytt säkerhetssystem.
Mer information om säkerhetsalternativen för Azure Synapse finns i Säkerhetsdokument.
Anslutning och autentisering
Alternativ för Teradata-auktorisering
Dricks
Autentisering i både Teradata och Azure Synapse kan vara "i databasen" eller via externa metoder.
Teradata stöder flera mekanismer för anslutning och auktorisering. Giltiga mekanismvärden är:
TD1, som väljer Teradata 1 som autentiseringsmekanism. Användarnamn och lösenord krävs.
TD2, som väljer Teradata 2 som autentiseringsmekanism. Användarnamn och lösenord krävs.
TDNEGO, som väljer en av autentiseringsmekanismerna automatiskt baserat på principen, utan användarengagemang.
LDAP, som väljer Lightweight Directory Access Protocol (LDAP) som autentiseringsmekanism. Programmet innehåller användarnamnet och lösenordet.
KRB5, som väljer Kerberos (KRB5) på Windows-klienter som arbetar med Windows-servrar. För att logga in med KRB5 måste användaren ange en domän, ett användarnamn och ett lösenord. Domänen anges genom att ange användarnamnet till
MyUserName@MyDomain.NTLM, som väljer NTLM på Windows-klienter som arbetar med Windows-servrar. Programmet innehåller användarnamnet och lösenordet.
Kerberos (KRB5), Kerberos Compatibility (KRB5C), NT LAN Manager (NTLM) och NT LAN Manager Compatibility (NTLMC) är endast för Windows.
Auktoriseringsalternativ för Azure Synapse
Azure Synapse stöder två grundläggande alternativ för anslutning och auktorisering:
SQL-autentisering: SQL-autentisering sker via en databasanslutning som innehåller en databasidentifierare, användar-ID och lösenord plus andra valfria parametrar. Detta motsvarar funktionellt Teradata TD1, TD2 och standardanslutningar.
Microsoft Entra-autentisering: Med Microsoft Entra-autentisering kan du centralt hantera identiteterna för databasanvändare och andra Microsoft-tjänster på en central plats. Central ID-hantering ger en enda plats för att hantera SQL Data Warehouse-användare och förenklar behörighetshantering. Microsoft Entra-ID kan också stödja anslutningar till LDAP- och Kerberos-tjänster, till exempel kan Microsoft Entra-ID användas för att ansluta till befintliga LDAP-kataloger om dessa ska finnas kvar efter migreringen av databasen.
Användare, roller och behörigheter
Översikt
Dricks
Planering på hög nivå är avgörande för ett lyckat migreringsprojekt.
Både Teradata och Azure Synapse implementerar databasåtkomstkontroll via en kombination av användare, roller och behörigheter. Båda använder SQL-standardinstruktioner CREATE USER och CREATE ROLE -instruktioner för att definiera användare och roller samt GRANT REVOKE instruktioner för att tilldela eller ta bort behörigheter till dessa användare och/eller roller.
Dricks
Automatisering av migreringsprocesser rekommenderas för att minska förfluten tid och omfång för fel.
Konceptuellt är de två databaserna liknande och det kan vara möjligt att automatisera migreringen av befintliga användar-ID:er, roller och behörigheter i viss utsträckning. Migrera sådana data genom att extrahera befintlig äldre användar- och rollinformation från Teradata-systemkatalogtabellerna och generera matchande motsvarighet CREATE USER och CREATE ROLE instruktioner som ska köras i Azure Synapse för att återskapa samma användar-/rollhierarki.
Efter dataextrahering använder du Teradata-systemkatalogtabeller för att generera motsvarande GRANT instruktioner för att tilldela behörigheter (där motsvarande finns). Följande diagram visar hur du använder befintliga metadata för att generera nödvändig SQL.
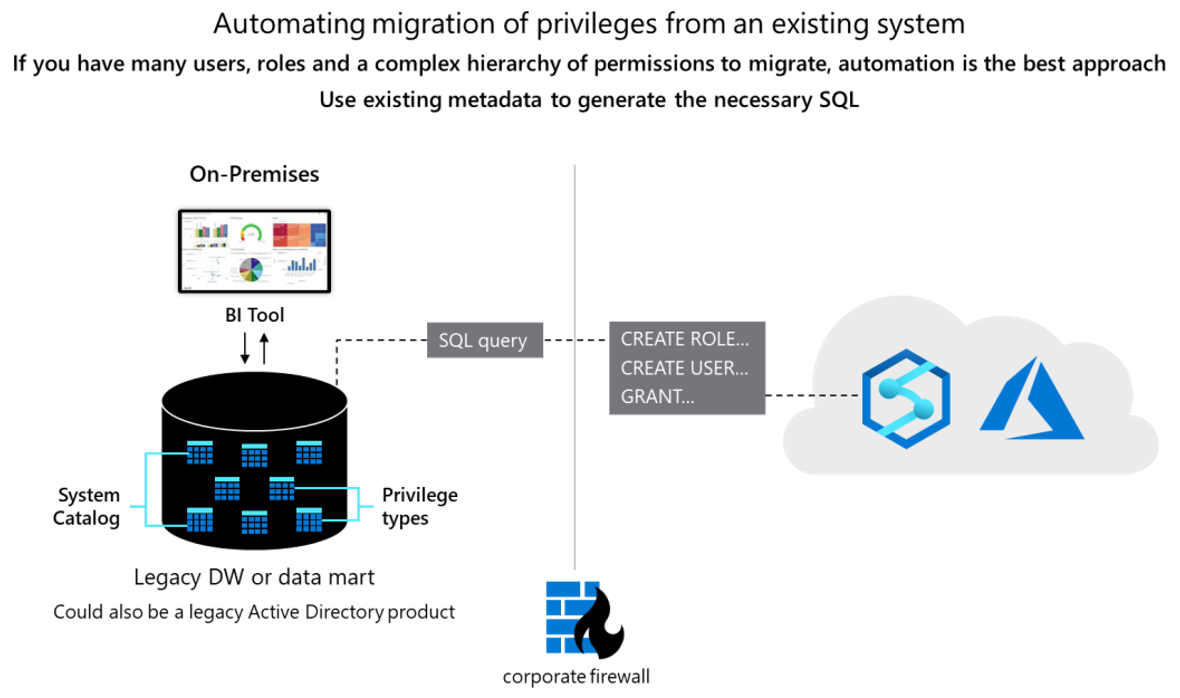
Användare och roller
Dricks
Migrering av ett informationslager kräver mer än bara tabeller, vyer och SQL-instruktioner.
Informationen om aktuella användare och roller i ett Teradata-system finns i systemkatalogtabellerna DBC.USERS (eller DBC.DATABASES) och DBC.ROLEMEMBERS. Fråga dessa tabeller (om användaren har SELECT åtkomst till dessa tabeller) för att hämta aktuella listor över användare och roller som definierats i systemet. Följande är exempel på frågor för att göra detta för enskilda användare:
/***SQL to find all users***/
SELECT
DatabaseName AS UserName
FROM DBC.Databases
WHERE dbkind = 'u';
/***SQL to find all roles***/
SELECT A.ROLENAME, A.GRANTEE, A.GRANTOR,
A.DefaultRole,
A.WithAdmin,
B.DATABASENAME,
B.TABLENAME,
B.COLUMNNAME,
B.GRANTORNAME,
B.AccessRight
FROM DBC.ROLEMEMBERS A
JOIN DBC.ALLROLERIGHTS B
ON A.ROLENAME = B.ROLENAME
GROUP BY 1,2,3,4,5,6,7
ORDER BY 2,1,6;
De här exemplen ändrar SELECT instruktioner för att skapa en resultatuppsättning, som är en serie CREATE USER med och CREATE ROLE -instruktioner, genom att inkludera lämplig text som en literal i -instruktionen SELECT .
Det finns inget sätt att hämta befintliga lösenord, så du måste implementera ett schema för att allokera nya initiala lösenord i Azure Synapse.
Behörigheter
Dricks
Det finns motsvarande Azure Synapse-behörigheter för grundläggande databasåtgärder som DML och DDL.
I ett Teradata-system tabellerar DBC.ALLRIGHTS systemet och DBC.ALLROLERIGHTS innehar åtkomsträttigheterna för användare och roller. Fråga dessa tabeller (om användaren har SELECT åtkomst till dessa tabeller) för att hämta aktuella listor över åtkomsträttigheter som definierats i systemet. Följande är exempel på frågor för enskilda användare:
/**SQL for AccessRights held by a USER***/
SELECT UserName, DatabaseName,TableName,ColumnName,
CASE WHEN Abbv.AccessRight IS NOT NULL THEN Abbv.Description ELSE
ALRTS.AccessRight
END AS AccessRight, GrantAuthority, GrantorName, AllnessFlag, CreatorName, CreateTimeStamp
FROM DBC.ALLRIGHTS ALRTS LEFT OUTER JOIN AccessRightsAbbv Abbv
ON ALRTS.AccessRight = Abbv.AccessRight
WHERE UserName='UserXYZ'
Order By 2,3,4,5;
/**SQL for AccessRights held by a ROLE***/
SELECT RoleName, DatabaseName,TableName,ColumnName,
CASE WHEN Abbv.AccessRight IS NOT NULL THEN Abbv.Description ELSE
ALRTS.AccessRight
END AS AccessRight, GrantorName, CreateTimeStamp
FROM DBC.ALLROLERIGHTS ALRTS LEFT OUTER JOIN AccessRightsAbbv
Abbv
ON ALRTS.AccessRight = Abbv.AccessRight
WHERE RoleName='BI_DEVELOPER'
Order By 2,3,4,5;
Ändra dessa exempelinstruktioner SELECT för att skapa en resultatuppsättning som är en serie GRANT instruktioner genom att inkludera lämplig text som en literal i -instruktionen SELECT .
Använd tabellen AccessRightsAbbv för att slå upp den fullständiga texten för åtkomsträttiga, eftersom kopplingsnyckeln är ett förkortat "typ"-fält. I följande tabell finns en lista över Teradata-åtkomsträttigheter och deras motsvarande i Azure Synapse.
| Teradata-behörighetsnamn | Teradata-typ | Motsvarande Azure Synapse |
|---|---|---|
| AVBRYT SESSION | AS | AVSLUTA DATABASANSLUTNING |
| ÄNDRA EXTERN PROCEDUR | AE | 4 |
| ALTER-FUNKTION | AF | ALTER-FUNKTION |
| ALTER-PROCEDUR | AP | ALTER-PROCEDUR |
| KONTROLLPUNKT | CP | KONTROLLPUNKT |
| SKAPA AUKTORISERING | CA | SKAPA INLOGGNING |
| SKAPA DATABAS | CD | SKAPA DATABAS |
| SKAPA EXTERN PROCEDUR | CE | 4 |
| CREATE FUNCTION | CF | CREATE FUNCTION |
| SKAPA GLOP | GC | 3 |
| SKAPA MAKRO | KB | SKAPA PROCEDUR 2 |
| SKAPA ÄGARPROCEDUR | OP | SKAPA PROCESS |
| SKAPA PROCEDUR | PC | SKAPA PROCESS |
| SKAPA PROFIL | CO | SKAPA INLOGGNING 1 |
| SKAPA ROLL | CR | SKAPA ROLL |
| DROP DATABASE | DD | DROP DATABASE |
| DROP FUNCTION | DF | DROP FUNCTION |
| SLÄPP GLOP | GD | 3 |
| SLÄPP MAKRO | DM | DROP-PROCEDUR 2 |
| DROP-PROCEDUR | PD | BORTTAGNINGSPROCEDUR |
| SLÄPP PROFIL | DO | SLÄPP INLOGGNING 1 |
| SLÄPP ROLL | DR | TA BORT ROLL |
| DROP TABLE | DT | DROP TABLE |
| SLÄPP UTLÖSARE | GD | 3 |
| SLÄPP ANVÄNDARE | DU | SLÄPP ANVÄNDARE |
| DROP VIEW | DV | DROP VIEW |
| SOPTIPP | DP | 4 |
| UTFÖRA | E | KÖR |
| KÖR FUNKTION | EF | KÖR |
| KÖR PROCEDUR | PE | KÖR |
| GLOP-MEDLEM | GM | 3 |
| INDEX | IX | CREATE INDEX |
| INSERT | I | INSERT |
| MONRESOURCE | MR | 5 |
| MONSESSION | MS | 5 |
| VILLKOR FÖR ÅSIDOSÄTTNING AV DUMPNING | OA | 4 |
| ÅSIDOSÄTTNINGSBEGRÄNSNING FÖR ÅTERSTÄLLNING | ELLER | 4 |
| REFERENSER | RF | REFERENSER |
| REPLCONTROL | RO | 5 |
| ÅTERSTÄLLA | RS | 4 |
| SELECT | R | SELECT |
| SETRESRATE | SR | 5 |
| SETSESSRATE | SS | 5 |
| VISA | SH | 3 |
| UPDATE | U | UPDATE |
AccessRightsAbbv tabellanteckningar:
Teradata
PROFILEär funktionellt likvärdigtLOGINmed i Azure Synapse.I följande tabell sammanfattas skillnaderna mellan makron och lagrade procedurer i Teradata. I Azure Synapse tillhandahåller procedurerna de funktioner som beskrivs i tabellen.
Makro Lagrad procedur Innehåller SQL Innehåller SQL Kan innehålla BTEQ-punktkommandon Innehåller omfattande SPL Kan ta emot parametervärden som skickas till den Kan ta emot parametervärden som skickas till den Kan hämta en eller flera rader Måste använda en markör för att hämta mer än en rad Lagras i DBC PERM-utrymme Lagrad i DATABAS eller ANVÄNDAR-PERM Returnerar rader till klienten Kan returnera ett eller flera värden till klienten som parametrar SHOW,GLOPochTRIGGERhar ingen direkt motsvarighet i Azure Synapse.Dessa funktioner hanteras automatiskt av systemet i Azure Synapse. Se Driftöverväganden.
I Azure Synapse hanteras dessa funktioner utanför databasen.
Mer information om åtkomsträttigheter i Azure Synapse finns i Säkerhetsbehörigheter för Azure Synapse Analytics.
Operativa överväganden
Dricks
Operativa uppgifter är nödvändiga för att hålla alla informationslager i drift effektivt.
I det här avsnittet beskrivs hur du implementerar vanliga Teradata-driftuppgifter i Azure Synapse med minimal risk och påverkan för användarna.
Precis som med alla produkter för informationslager finns det löpande hanteringsuppgifter som är nödvändiga för att hålla systemet igång effektivt och för att tillhandahålla data för övervakning och granskning. Resursutnyttjande och kapacitetsplanering för framtida tillväxt ingår också i den här kategorin, liksom säkerhetskopiering/återställning av data.
Även om hanterings- och driftuppgifterna för olika informationslager är liknande, kan de enskilda implementeringarna skilja sig åt. I allmänhet tenderar moderna molnbaserade produkter som Azure Synapse att införliva en mer automatiserad och "systemhanterad" metod (i motsats till en mer "manuell" metod i äldre informationslager som Teradata).
I följande avsnitt jämförs alternativen Teradata och Azure Synapse för olika operativa uppgifter.
Hushållningsuppgifter
Dricks
Hushållningsuppgifter gör att ett produktionslager fungerar effektivt och optimerar användningen av resurser, till exempel lagring.
I de flesta äldre informationslagermiljöer finns det ett krav på att utföra regelbundna "hushållningsuppgifter", till exempel att frigöra diskutrymme som kan frigöras genom att ta bort gamla versioner av uppdaterade eller borttagna rader eller omorganisera dataloggfiler eller indexblock för effektivitet. Att samla in statistik är också en potentiellt tidskrävande uppgift. Insamling av statistik krävs efter massinmatning av data för att ge frågeoptimeraren uppdaterade data till basgenereringen av frågekörningsplaner.
Teradata rekommenderar att du samlar in statistik på följande sätt:
Samla in statistik om obefyllda tabeller för att konfigurera intervall histogrammet som används i intern bearbetning. Den här första samlingen gör efterföljande statistiksamlingar snabbare. Kom ihåg statistik när data har lagts till.
Samla in statistik för prototypfaser för nyligen ifyllda tabeller.
Samla in produktionsfasstatistik efter en betydande procentandel ändringar i tabellen eller partitionen (~10 % av raderna). För stora volymer av icke-substantivvärden, till exempel datum eller tidsstämplar, kan det vara fördelaktigt att komma ihåg vid 7 %.
Samla in produktionsfasstatistik när du har skapat användare och tillämpat verkliga frågeinläsningar på databasen (upp till cirka tre månaders frågekörning).
Samla in statistik under de första veckorna efter en uppgradering eller migrering under perioder med låg CPU-användning.
Statistikinsamling kan hanteras manuellt med hjälp av automatisk statistikhantering, öppna API:er eller automatiskt med hjälp av portleten Teradata Viewpoint Stats Manager.
Dricks
Automatisera och övervaka hushållningsuppgifter i Azure.
Teradata Database innehåller många loggtabeller i dataordlistan som ackumulerar data, antingen automatiskt eller efter att vissa funktioner har aktiverats. Eftersom loggdata växer med tiden rensar du äldre information för att undvika att använda permanent utrymme. Det finns alternativ för att automatisera underhållet av de här loggarna. De Teradata-ordlistetabeller som kräver underhåll diskuteras härnäst.
Ordlistetabeller att underhålla
Återställ ackumulatorer och toppvärden med hjälp av DBC.AMPUsage vyn och ClearPeakDisk makrot som medföljer programvaran:
DBC.Acctg: resursanvändning per konto/användareDBC.DataBaseSpace: databas- och tabellutrymmesredovisning
Teradata underhåller automatiskt dessa tabeller, men bra metoder kan minska deras storlek:
DBC.AccessRights: användarrättigheter för objektDBC.RoleGrants: rollrättigheter för objektDBC.Roles: definierade rollerDBC.Accounts: kontokoder efter användare
Arkivera dessa loggningstabeller (om så önskas) och rensa information 60–90 dagar gammal. Kvarhållning beror på kundens krav:
DBC.SW_Event_Log: databaskonsolloggDBC.ResUsage: resursövervakningstabellerDBC.EventLog: sessionsinloggnings-/utloggningshistorikDBC.AccLogTbl: loggade användar-/objekthändelserDBC.DBQL tables: loggad användare/SQL-aktivitet.NETSecPolicyLogTbl: loggar spårningsloggar för dynamisk säkerhetsprincip.NETSecPolicyLogRuleTbl: styr när och hur dynamisk säkerhetsprincip loggas
Rensa dessa tabeller när det associerade flyttbara mediet har upphört att gälla och skrivs över:
DBC.RCEvent: arkiv-/återställningshändelserDBC.RCConfiguration: arkiv-/återställningskonfigurationDBC.RCMedia: VolSerial för arkiv/återställning
Azure Synapse har möjlighet att automatiskt skapa statistik så att de kan användas efter behov. Utför defragmentering av index och datablock manuellt, enligt schema eller automatiskt. Om du använder inbyggda inbyggda Azure-funktioner kan du minska den ansträngning som krävs i en migreringsövning.
Övervakning och granskning
Dricks
Med tiden har flera olika verktyg implementerats för att tillåta övervakning och loggning av Teradata-system.
Teradata innehåller flera verktyg för att övervaka åtgärden, inklusive Teradata Viewpoint och Ecosystem Manager. För loggning av frågehistorik är databasfrågeloggen (DBQL) en Teradata-databasfunktion som innehåller en serie fördefinierade tabeller som kan lagra historiska poster med frågor och deras varaktighet, prestanda och målaktivitet baserat på användardefinierade regler.
Databasadministratörer kan använda Teradata Viewpoint för att fastställa systemstatus, trender och individuell frågestatus. Genom att observera trender i systemanvändningen är systemadministratörerna bättre på att planera projektimplementeringar, batchjobb och underhåll för att undvika perioder med hög belastning. Företagsanvändare kan använda Teradata Viewpoint för att snabbt få åtkomst till status för rapporter och frågor och öka detaljnivån i information.
Dricks
Azure Portal tillhandahåller ett användargränssnitt för att hantera övervaknings- och granskningsuppgifter för alla Azure-data och -processer.
På samma sätt ger Azure Synapse en omfattande övervakningsupplevelse inom Azure Portal för att ge insikter om din arbetsbelastning i informationslagret. Azure Portal är det rekommenderade verktyget när du övervakar ditt informationslager eftersom det ger konfigurerbara kvarhållningsperioder, aviseringar, rekommendationer och anpassningsbara diagram och instrumentpaneler för mått och loggar.
Portalen möjliggör även integrering med andra Azure-övervakningstjänster som Operations Management Suite (OMS) och Azure Monitor (loggar) för att ge en holistisk övervakningsupplevelse för inte bara informationslagret utan även hela Azure-analysplattformen för en integrerad övervakningsupplevelse.
Dricks
Mått på låg nivå och systemomfattande loggas automatiskt i Azure Synapse.
Resursanvändningsstatistik för Azure Synapse loggas automatiskt i systemet. Måtten för varje fråga omfattar användningsstatistik för CPU, minne, cache, I/O och tillfällig arbetsyta samt anslutningsinformation som misslyckade anslutningsförsök.
Azure Synapse tillhandahåller en uppsättning dynamiska hanteringsvyer (DMV:er). Dessa vyer är användbara när du aktivt felsöker och identifierar flaskhalsar i prestanda med din arbetsbelastning.
Mer information finns i Åtgärder och hanteringsalternativ för Azure Synapse.
Hög tillgänglighet (HA) och haveriberedskap (DR)
Teradata implementerar funktioner som FALLBACKarc-verktyget (Archive Restore Copy) och Data Stream Architecture (DSA) för att ge skydd mot dataförlust och hög tillgänglighet (HA) via replikering och arkivering av data. Alternativen för haveriberedskap (DR) omfattar dubbel aktiv lösning, dr som en tjänst eller ett ersättningssystem beroende på återställningstidskravet.
Dricks
Azure Synapse skapar ögonblicksbilder automatiskt för att säkerställa snabba återställningstider.
Azure Synapse använder databasögonblicksbilder för att tillhandahålla hög tillgänglighet för lagret. En ögonblicksbild av informationslagret skapar en återställningspunkt som kan användas för att återställa eller kopiera ett informationslager till ett tidigare tillstånd. Eftersom Azure Synapse är ett distribuerat system består en ögonblicksbild av informationslagret av många filer som finns i Azure Storage. Ögonblicksbilder samlar in inkrementella ändringar från data som lagras i ditt informationslager.
Azure Synapse tar automatiskt ögonblicksbilder under dagen och skapar återställningspunkter som är tillgängliga i sju dagar. Det går inte att ändra kvarhållningsperioden. Azure Synapse stöder ett mål för åtta timmars återställningspunkt (RPO). Ett informationslager kan återställas i den primära regionen från någon av ögonblicksbilderna som tagits under de senaste sju dagarna.
Dricks
Använd användardefinierade ögonblicksbilder för att definiera en återställningspunkt före viktiga uppdateringar.
Användardefinierade återställningspunkter stöds också, vilket gör att manuell utlösande av ögonblicksbilder kan skapa återställningspunkter för ett informationslager före och efter stora ändringar. Den här funktionen säkerställer att återställningspunkterna är logiskt konsekventa, vilket ger ytterligare dataskydd vid avbrott i arbetsbelastningen eller användarfel för ett önskat RPO på mindre än 8 timmar.
Dricks
Microsoft Azure tillhandahåller automatiska säkerhetskopior till en separat geografisk plats för att aktivera DR.
Förutom de ögonblicksbilder som beskrevs tidigare utför Azure Synapse även som standard en geo-säkerhetskopiering en gång per dag till ett kopplat datacenter. RPO för en geo-återställning är 24 timmar. Du kan återställa geo-säkerhetskopieringen till en server i alla andra regioner där Azure Synapse stöds. En geo-säkerhetskopia säkerställer att ett informationslager kan återställas om återställningspunkterna i den primära regionen inte är tillgängliga.
Arbetsbelastningshantering
Dricks
I ett informationslager för produktion finns det vanligtvis blandade arbetsbelastningar med olika resursanvändningsegenskaper som körs samtidigt.
En arbetsbelastning är en klass med databasbegäranden med gemensamma egenskaper vars åtkomst till databasen kan hanteras med en uppsättning regler. Arbetsbelastningar är användbara för:
Ange olika åtkomstprioriteringar för olika typer av begäranden.
Övervaka resursanvändningsmönster, prestandajustering och kapacitetsplanering.
Begränsa antalet begäranden eller sessioner som kan köras samtidigt.
I ett Teradata-system är arbetsbelastningshantering att hantera arbetsbelastningsprestanda genom att övervaka systemaktivitet och agera när fördefinierade gränser nås. Arbetsbelastningshantering använder regler, och varje regel gäller endast för vissa databasbegäranden. Samlingen av alla regler gäller dock för allt aktivt arbete på plattformen. Teradata Active System Management (TASM) utför fullständig arbetsbelastningshantering i en Teradata-databas.
I Azure Synapse är resursklasser förutbestämda resursgränser som styr beräkningsresurser och samtidighet för frågekörning. Resursklasser kan hjälpa dig att hantera din arbetsbelastning genom att ange gränser för antalet frågor som körs samtidigt och på de beräkningsresurser som tilldelats till varje fråga. Det finns en kompromiss mellan minne och samtidighet.
Azure Synapse loggar automatiskt statistik över resursanvändning. Måtten omfattar användningsstatistik för CPU, minne, cache, I/O och tillfällig arbetsyta för varje fråga. Azure Synapse loggar även anslutningsinformation, till exempel misslyckade anslutningsförsök.
Dricks
Mått på låg nivå och systemomfattande loggas automatiskt i Azure.
Azure Synapse stöder följande grundläggande begrepp för arbetsbelastningshantering:
Arbetsbelastningsklassificering: Du kan tilldela en begäran till en arbetsbelastningsgrupp för att ange prioritetsnivåer.
Arbetsbelastningens betydelse: du kan påverka i vilken ordning en begäran får åtkomst till resurser. Som standard släpps frågor från kön först in, först ut när resurser blir tillgängliga. Med arbetsbelastningsprioritet kan frågor med högre prioritet ta emot resurser omedelbart oavsett kön.
Arbetsbelastningsisolering: du kan reservera resurser för en arbetsbelastningsgrupp, tilldela maximal och minsta användning för olika resurser, begränsa de resurser som en grupp med begäranden kan använda och ange ett timeout-värde för att automatiskt döda skenande frågor.
Att köra blandade arbetsbelastningar kan innebära resursutmaningar i upptagna system. Ett lyckat arbetsbelastningshanteringsschema hanterar effektivt resurser, säkerställer högeffektiv resursanvändning och maximerar avkastningen på investeringen (ROI). Arbetsbelastningsklassificering, arbetsbelastningsbetydelse och arbetsbelastningsisolering ger mer kontroll över hur arbetsbelastningen använder systemresurser.
Arbetsbelastningshanteringsguiden beskriver de tekniker som används för att analysera arbetsbelastningen, hantera och övervaka arbetsbelastningens betydelse](.. /.. /sql-data-warehouse/sql-data-warehouse-how-to-manage-and-monitor-workload-importance.md) och stegen för att konvertera en resursklass till en arbetsbelastningsgrupp. Använd Azure Portal- och T-SQL-frågorna på DMV:er för att övervaka arbetsbelastningen för att säkerställa att tillämpliga resurser används effektivt. Azure Synapse tillhandahåller en uppsättning dynamiska hanteringsvyer (DMV:er) för övervakning av alla aspekter av arbetsbelastningshantering. Dessa vyer är användbara när du aktivt felsöker och identifierar flaskhalsar i arbetsbelastningen.
Den här informationen kan också användas för kapacitetsplanering och fastställa vilka resurser som krävs för ytterligare användare eller programarbetsbelastningar. Detta gäller även för planering av upp- och nedskalning av beräkningsresurser för kostnadseffektivt stöd för "peaky"-arbetsbelastningar.
Mer information om arbetsbelastningshantering i Azure Synapse finns i Arbetsbelastningshantering med resursklasser.
Scale compute resources (Skala beräkningsresurser)
Dricks
En stor fördel med Azure är möjligheten att självständigt skala upp och ned beräkningsresurser på begäran för att hantera arbetsbelastningar med hög belastning på ett kostnadseffektivt sätt.
Arkitekturen i Azure Synapse separerar lagring och beräkning, vilket gör att var och en kan skalas separat. Därför kan beräkningsresurser skalas för att uppfylla prestandakrav oberoende av datalagring. Du kan också pausa och återuppta beräkningsresurser. En naturlig fördel med den här arkitekturen är att faktureringen för beräkning och lagring är separat. Om ett informationslager inte används kan du spara på beräkningskostnader genom att pausa beräkningen.
Beräkningsresurser kan skalas upp eller skalas tillbaka genom att justera inställningen för informationslagerenheter för informationslagret. Inläsnings- och frågeprestanda ökar linjärt när du lägger till fler informationslagerenheter.
Att lägga till fler beräkningsnoder ger mer beräkningskraft och möjlighet att utnyttja mer parallell bearbetning. När antalet beräkningsnoder ökar minskar antalet fördelningar per beräkningsnod, vilket ger mer beräkningskraft och parallell bearbetning för frågor. På samma sätt minskar minskande informationslagerenheter antalet beräkningsnoder, vilket minskar beräkningsresurserna för frågor.
Nästa steg
Mer information om visualisering och rapportering finns i nästa artikel i den här serien: Visualisering och rapportering för Teradata-migreringar.