Snabbstart: Mata in data med ett klick (förhandsversion)
Inmatning med ett klick gör datainmatningsprocessen enkel, snabb och intuitiv. Med inmatning med ett klick kan du snabbt komma igång med att mata in data, skapa databastabeller, mappa strukturer. Välj data från olika typer av källor i olika dataformat, antingen som en engångs- eller kontinuerlig inmatningsprocess.
Följande funktioner gör inmatning med ett klick så användbar:
- Intuitiv upplevelse som styrs av inmatningsguiden
- Mata in data på några minuter
- Mata in data från olika typer av källor: lokal fil, blobar och containrar (upp till 10 000 blobar)
- Mata in data i olika format
- Mata in data i nya eller befintliga tabeller
- Tabellmappning och schema föreslås för dig och är enkla att ändra
Inmatning med ett klick är särskilt användbart när du matar in data för första gången, eller när dina datas schema inte är bekant för dig.
Förutsättningar
En Azure-prenumeration. Skapa ett kostnadsfritt Azure-konto.
Skapa en Data Explorer pool med hjälp av Synapse Studio eller Azure Portal
Skapa en Data Explorer databas.
I Synapse Studio väljer du Data i fönstret till vänster.
Välj + (Lägg till ny resurs) >Data Explorer pool och använd följande information:
Inställning Föreslaget värde Beskrivning Poolnamn contosodataexplorer Namnet på den Data Explorer pool som ska användas Name TestDatabase Databasnamnet måste vara unikt inom klustret. Standardkvarhållningsperiod 365 Det tidsintervall (i dagar) då det är garanterat att data förblir tillgängliga för frågor. Tidsintervallet mäts från det att data matas in. Standardcacheperiod 31 Det tidsintervall (i dagar) då data som frågor körs mot ofta ska vara tillgängliga i SSD-lagring eller RAM i stället för i långsiktig lagring. Välj Skapa för att skapa databasen. Det brukar ta mindre än en minut att skapa en databas.
Skapa en tabell
- I Synapse Studio väljer du Utveckla i fönstret till vänster.
- Under KQL-skript väljer du + (Lägg till ny resurs) >KQL-skript. I den högra rutan kan du namnge skriptet.
- På menyn Anslut till väljer du contosodataexplorer.
- På menyn Använd databas väljer du TestDatabase.
- Klistra in följande kommando och välj Kör för att skapa tabellen.
.create table StormEvents (StartTime: datetime, EndTime: datetime, EpisodeId: int, EventId: int, State: string, EventType: string, InjuriesDirect: int, InjuriesIndirect: int, DeathsDirect: int, DeathsIndirect: int, DamageProperty: int, DamageCrops: int, Source: string, BeginLocation: string, EndLocation: string, BeginLat: real, BeginLon: real, EndLat: real, EndLon: real, EpisodeNarrative: string, EventNarrative: string, StormSummary: dynamic)Tips
Kontrollera att tabellen har skapats. I den vänstra rutan väljer du Data, väljer menyn contosodataexplorer more och väljer sedan Uppdatera. Under contosodataexplorer expanderar du Tabeller och kontrollerar att tabellen StormEvents visas i listan.
Öppna guiden med ett klick
Guiden för inmatning med ett klick vägleder dig genom inmatningsprocessen med ett klick.
Så här kommer du åt guiden från Azure Synapse:
I Synapse Studio väljer du Data i fönstret till vänster.
Under Data Explorer databaser högerklickar du på relevant databas och väljer sedan Öppna i Azure Data Explorer.
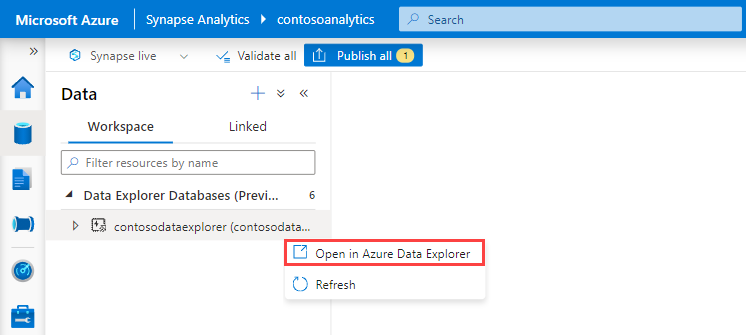
Högerklicka på den relevanta poolen och välj sedan Mata in nya data.
Så här kommer du åt guiden från Azure Portal:
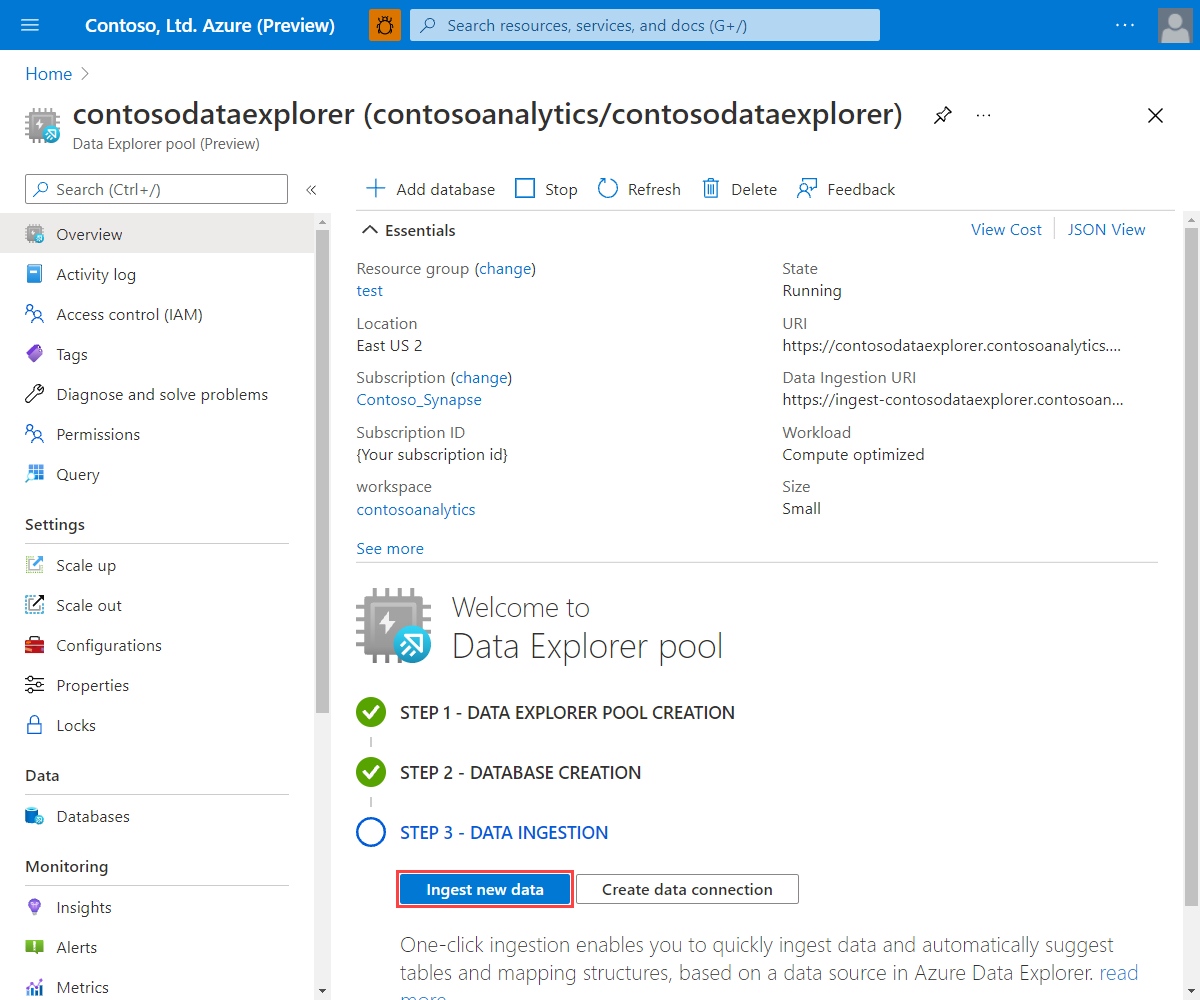
I Azure Portal söker du efter och väljer relevant Synapse-arbetsyta.
Under Data Explorer pooler väljer du relevant pool.
På startskärmen Välkommen till Data Explorer pool väljer du Mata in nya data.
Så här kommer du åt guiden från webbgränssnittet i Azure Data Explorer:
- Innan du börjar använder du följande steg för att hämta fråge- och datainmatningsslutpunkterna.
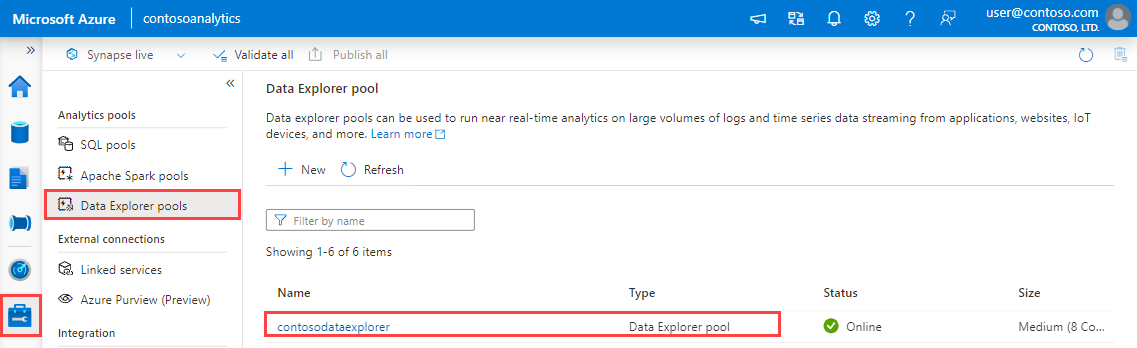
I Synapse Studio går du till fönstret till vänster och väljer Hantera>Data Explorer pooler.
Välj den Data Explorer pool som du vill använda för att visa dess information.
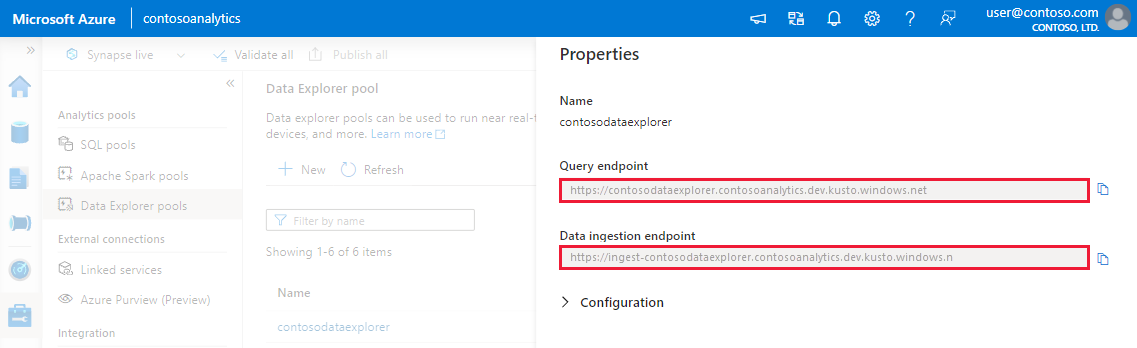
Anteckna fråge- och datainmatningsslutpunkterna. Använd frågeslutpunkten som kluster när du konfigurerar anslutningar till din Data Explorer pool. När du konfigurerar SDK:er för datainmatning använder du slutpunkten för datainmatning.
- I webbgränssnittet för Azure Data Explorer lägger du till en anslutning till frågeslutpunkten.
- Välj Fråga på den vänstra menyn, högerklicka på databasen eller tabellen och välj Mata in nya data.
- Innan du börjar använder du följande steg för att hämta fråge- och datainmatningsslutpunkterna.
Inmatningsguiden med ett klick
Anteckning
I det här avsnittet beskrivs guiden med Event Hub som datakälla. Du kan också använda de här stegen för att mata in data från en blob, fil, blobcontainer och en ADLS Gen2-container.
Ersätt exempelvärdena med faktiska värden för Synapse-arbetsytan.
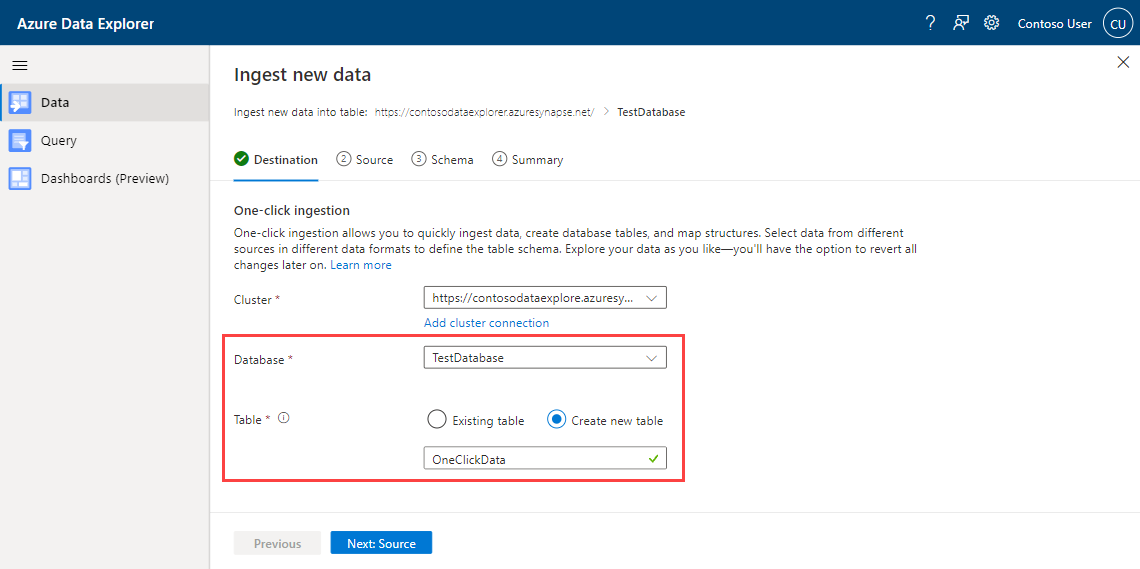
På fliken Mål väljer du databasen och tabellen för inmatade data.
På fliken Källa:
Välj Händelsehubb som Källtyp för inmatningen.

Fyll i information om händelsehubbens dataanslutning med hjälp av följande information:
Inställning Exempelvärde Beskrivning Namn på dataanslutning ContosoDataConnection Namnet på händelsehubbens dataanslutning Prenumeration Contoso_Synapse Den prenumeration där händelsehubben finns. Namnområde för hubb contosoeventhubnamespace Namnområdet för händelsehubben. Konsumentgrupp contosoconsumergroup Namnet på konsumentgruppen Even Hub. 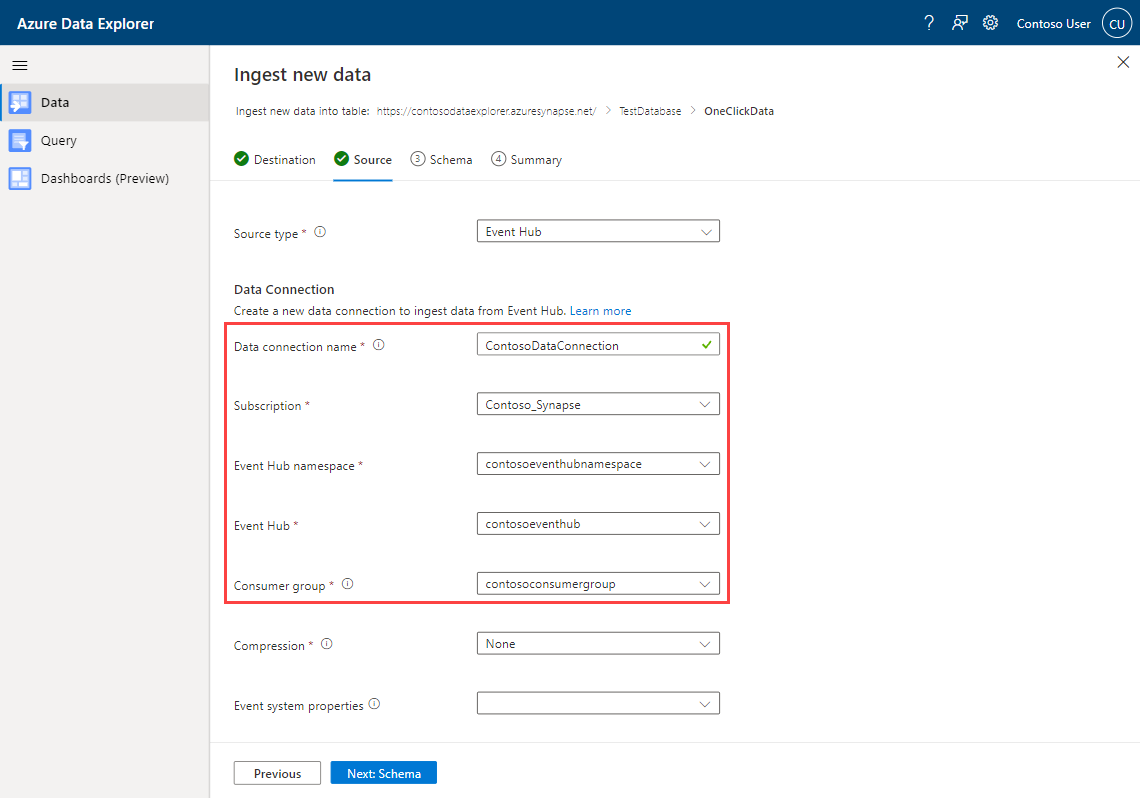
Välj Nästa.
Schemamappning
Tjänsten genererar automatiskt schema- och inmatningsegenskaper som du kan ändra. Du kan använda en befintlig mappningsstruktur eller skapa en ny, beroende på om du matar in till en ny eller befintlig tabell.
Gör följande på fliken Schema :
- Bekräfta den automatiskt genererade komprimeringstypen.
- Välj formatet för dina data. Med olika format kan du göra ytterligare ändringar.
- Ändra mappning i redigeringsfönstret.
Filformat
Inmatning med ett klick stöder inmatning från källdata i alla dataformat som stöds av Data Explorer för inmatning.
Redigeringsfönster
I redigeringsfönstret på fliken Schema kan du justera datatabellkolumner efter behov.
Vilka ändringar du kan göra i en tabell beror på följande parametrar:
- Tabelltypen är ny eller befintlig
- Mappningstypen är ny eller befintlig
| Tabelltyp | Mappningstyp | Tillgängliga justeringar |
|---|---|---|
| Ny tabell | Ny mappning | Ändra datatyp, Byt namn på kolumn, Ny kolumn, Ta bort kolumn, Uppdatera kolumn, Sortera stigande, Sortera fallande |
| Befintlig tabell | Ny mappning | Ny kolumn (där du sedan kan ändra datatyp, byta namn på och uppdatera) Uppdatera kolumn, Sortera stigande, Sortera fallande |
| Befintlig mappning | Sortera stigande, Sortera fallande |
Anteckning
När du lägger till en ny kolumn eller uppdaterar en kolumn kan du ändra mappningstransformeringar. Mer information finns i Mappa transformeringar
Mappning av transformeringar
Vissa dataformatmappningar (Parquet, JSON och Avro) stöder enkla inmatningstidstransformeringar. Om du vill använda mappningstransformeringar skapar eller uppdaterar du en kolumn i redigeringsfönstret.
Mappningstransformeringar kan utföras på en kolumn med typsträng eller datetime, där källan har datatypen int eller lång. Mappningstransformeringar som stöds är:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Datainhämtning
När du har slutfört schemamappning och kolumnmanipuleringar startar inmatningsguiden datainmatningsprocessen.
När data matas in från icke-containerkällor börjar inmatningen att gälla omedelbart.
Om din datakälla är en container:
- Data Explorer batchprincip aggregerar dina data.
- Efter inmatningen kan du ladda ned inmatningsrapporten och granska prestanda för varje blob som har åtgärdats.
Inledande datagranskning
Efter inmatningen ger guiden dig alternativ för att använda snabbkommandon för inledande utforskning av dina data.