Optimera frågan med hjälp av jobbsimulering
Ett sätt att förbättra prestandan för ett Azure Stream Analytics-jobb (ASA) är att tillämpa parallellitet i frågan. Den här artikeln visar hur du använder jobbsimuleringen i Azure Portal och Visual Studio Code (VS Code) för att utvärdera frågeparallelliteten för ett Stream Analytics-jobb. Du lär dig att visualisera en frågekörning med olika antal strömningsenheter och förbättra frågeparallelliteten baserat på redigeringsförslagen.
Vad är parallell fråga?
Frågeparallellitet delar upp arbetsbelastningen för en fråga genom att skapa flera processer (eller strömmande noder) och köra den parallellt. Det minskar avsevärt den totala körningstiden för frågan och därför behövs färre strömningstimmar.
För att ett jobb ska vara parallellt måste alla indata, utdata och frågesteg justeras och använda samma partitionsnycklar. Frågelogikpartitioneringen bestäms av de nycklar som används för aggregeringar (GROUP BY).
Mer information om frågeparallellisering finns i Använda frågeparallellisering i Azure Stream Analytics.
Använda jobbsimulering i VS Code
Jobbsimuleringsfunktionen simulerar hur jobbet skulle köra topologin i Azure. I den här självstudien lär du dig att förbättra frågeprestanda baserat på redigeringsförslag och att köra det parallellt. Vi använder till exempel ett icke-heltalsjobb som tar indata från en händelsehubb och skickar resultatet till en annan händelsehubb.
Krav:
- ASA Tools-tillägget för VS Code. Om du inte har installerat det ännu följer du den här guiden för att installera.
- Konfigurera liveindata och liveutdata för Stream Analytics-jobbet.
- Du måste inkludera live-indata och utdata i frågan.
Anteckning
Jobbsimuleringen kan inte simulera jobb som kör topologi för lokala indata och utdata. Inga data skulle skickas till utdatamålet under simuleringen.
Öppna ASA-projektet i VS Code. Gå till frågefilen *.asaql och välj Simulera jobb för att starta jobbsimuleringen.
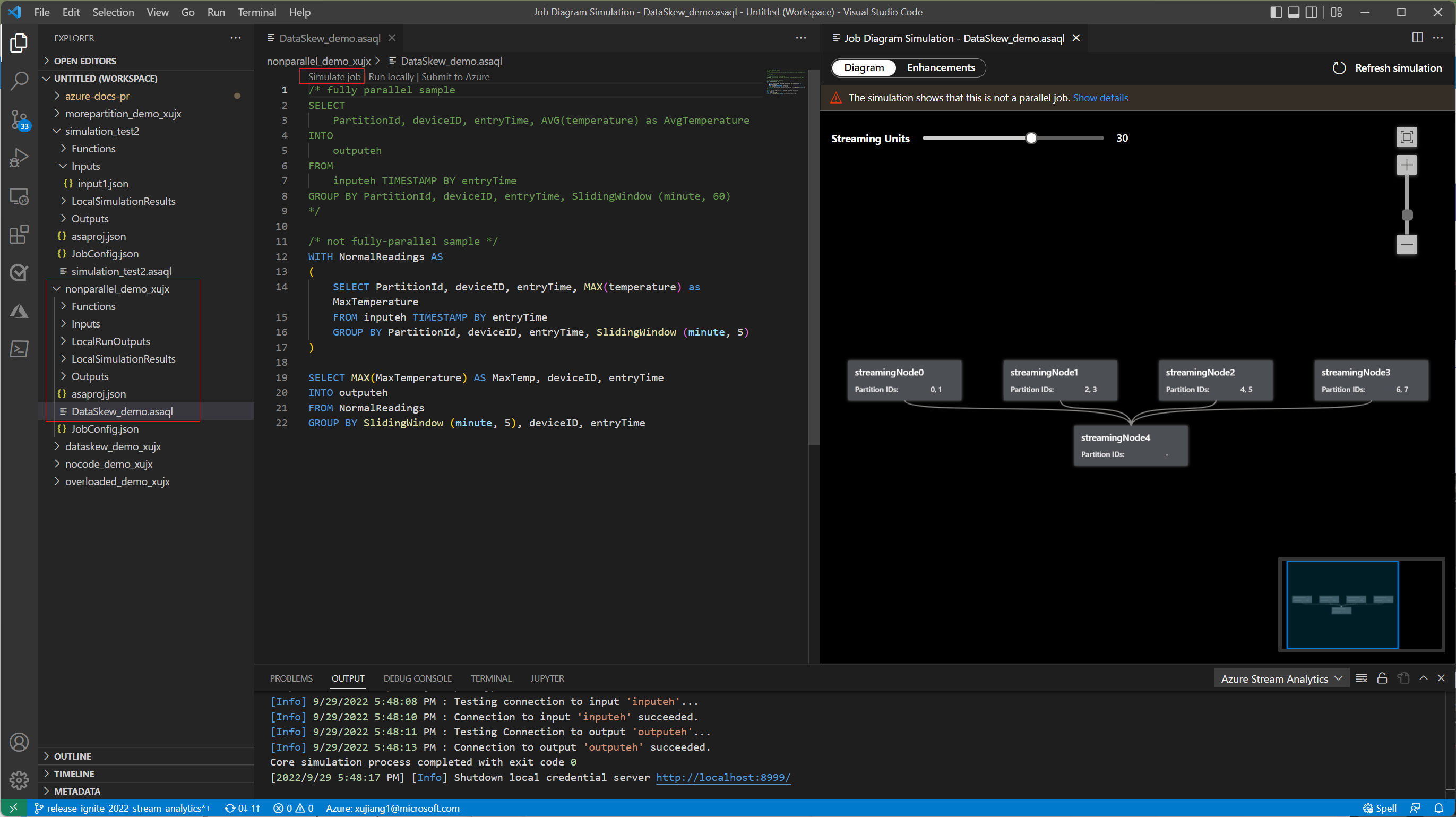
På fliken Diagram visas antalet direktuppspelade noder som allokerats till jobbet och antalet partitioner i varje direktuppspelningsnod. Följande skärmbild är ett exempel på ett icke-heltalsjobb där data flödar mellan noder.
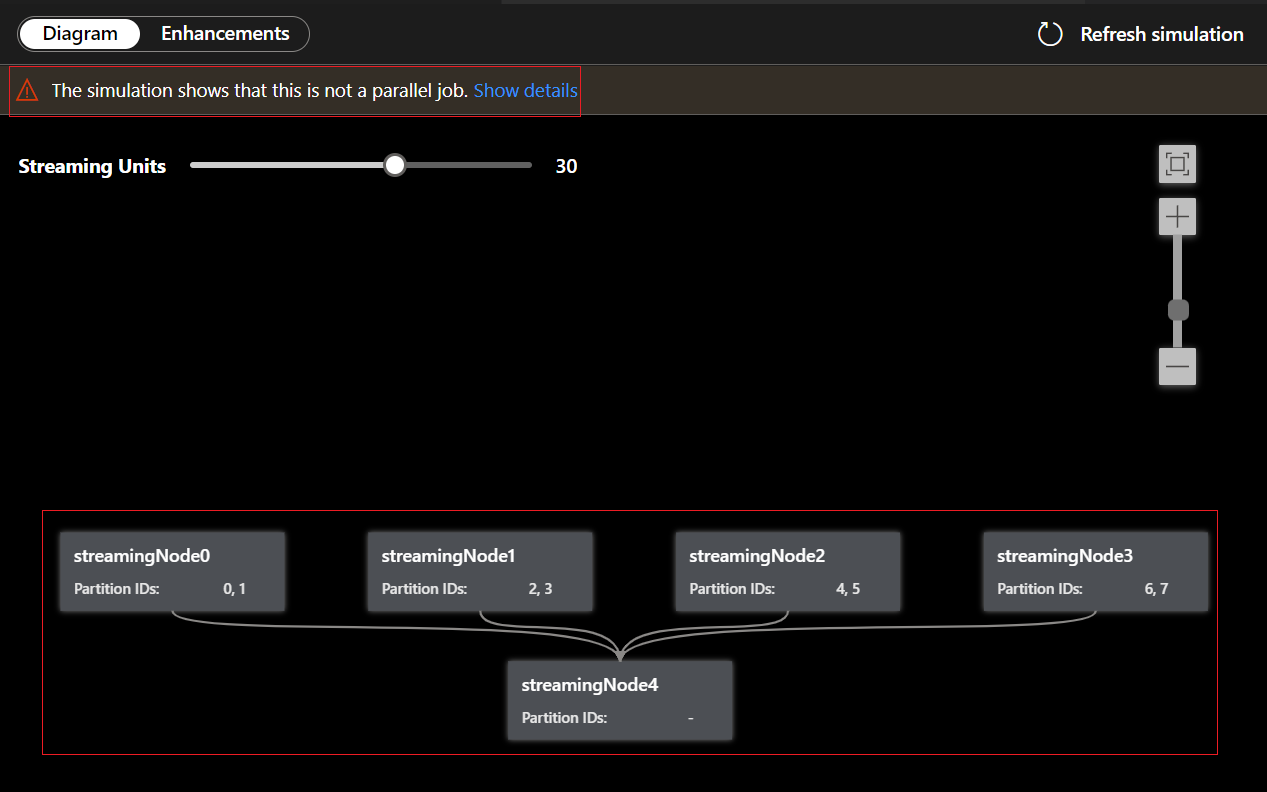
Eftersom den här frågan INTE är parallell kan du välja fliken Förbättringar för att visa förslag på hur du kan förbättra frågan.
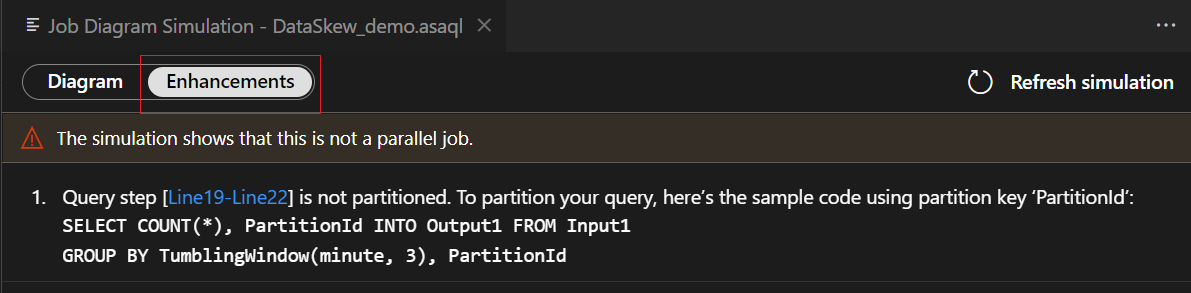
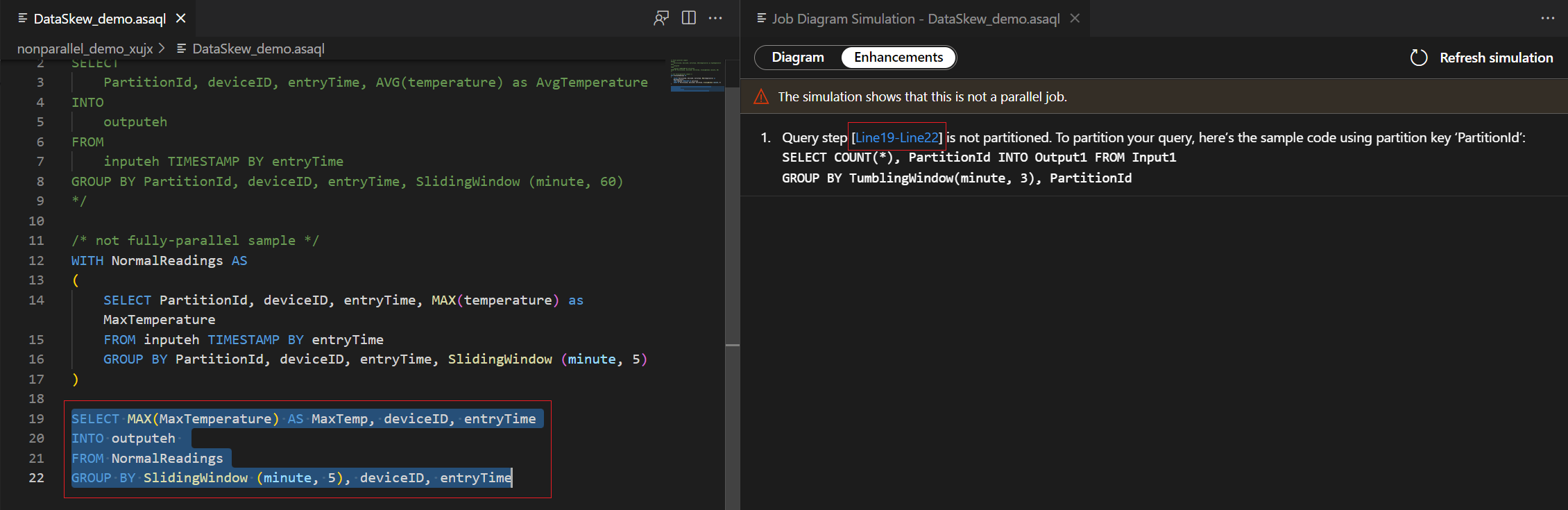
Välj frågesteg i listan med förbättringar. Du ser att motsvarande rader är markerade och att du kan redigera frågan baserat på förslagen.
Anteckning
Det här är redigeringsförslag för att förbättra frågeparallelliteten. Men om du använder mängdfunktionen bland alla partitioner kanske en parallell fråga inte är tillämplig för dina scenarier.
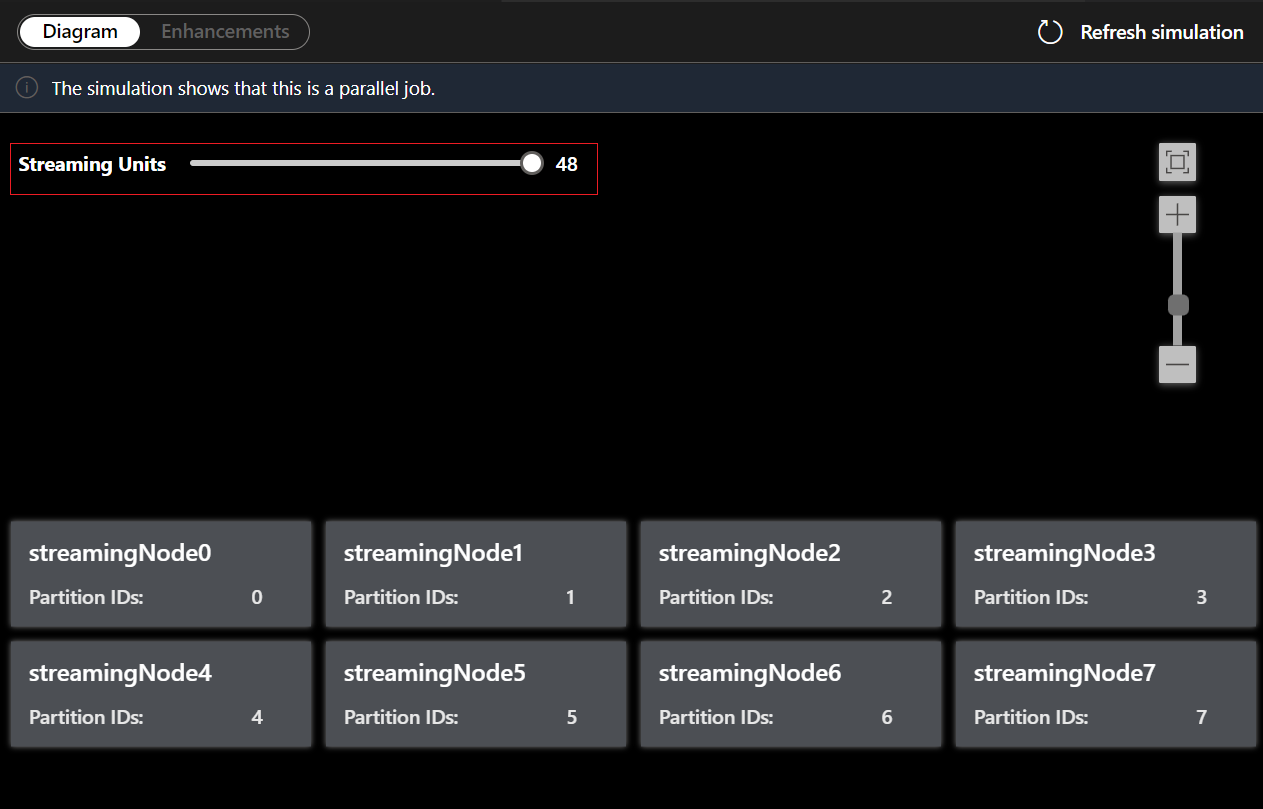
I det här exemplet lägger du till PartitionId på rad 22 och sparar ändringen. Sedan kan du använda uppdateringssimulering för att hämta det nya diagrammet.
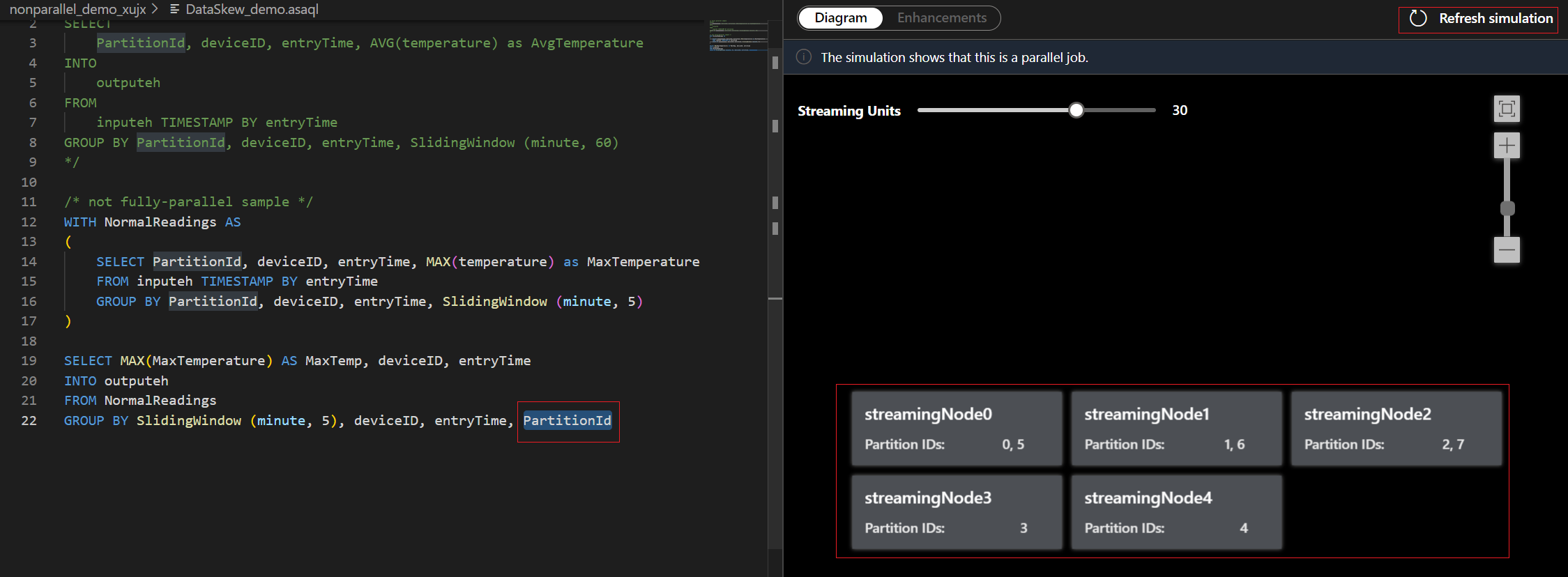
Du kan också justera strömningsenheter för att stimulera hur strömmande noder allokeras med olika SU:er. Det ger dig en uppfattning om hur många SU:er du behöver för att hantera din arbetsbelastning.






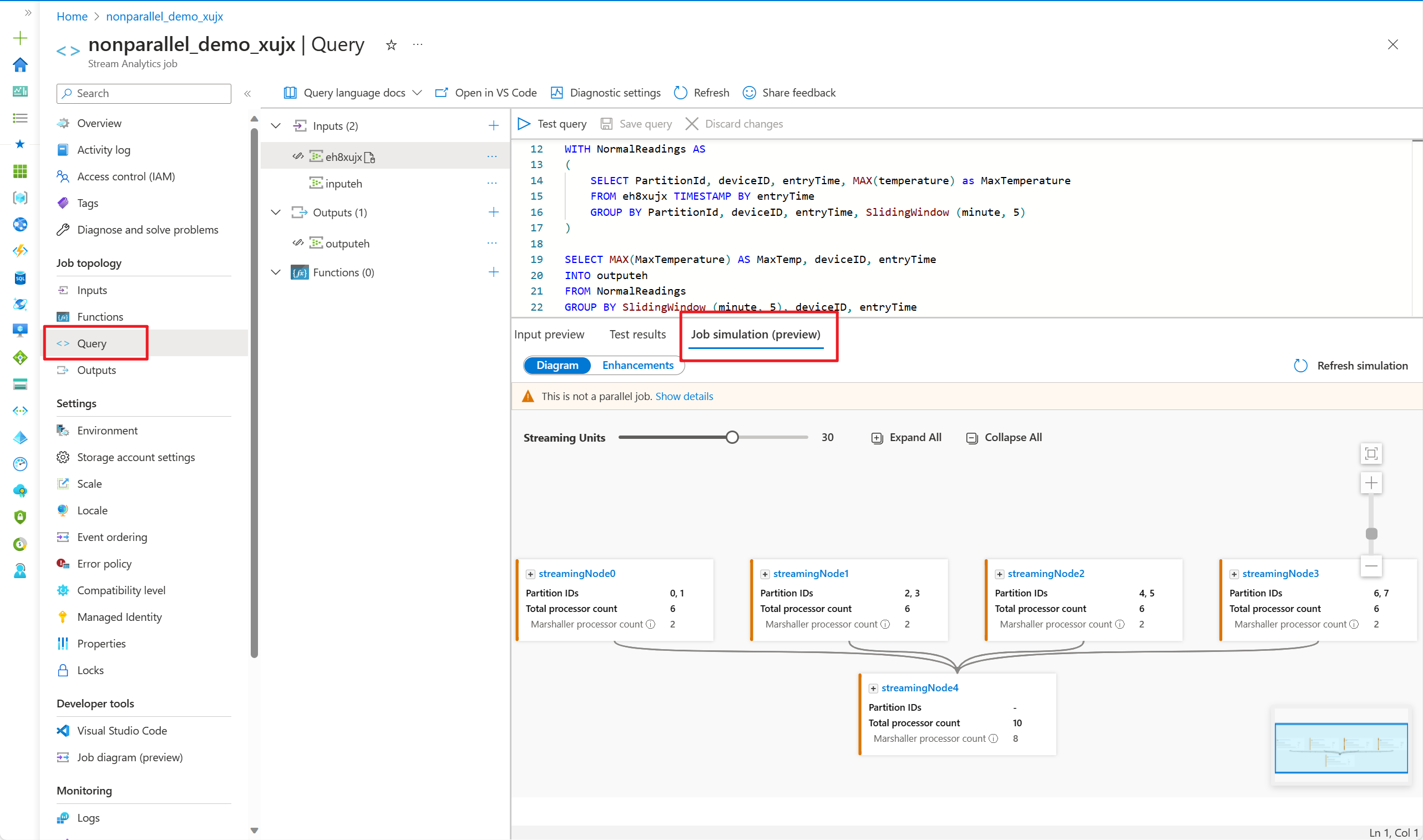
Använda jobbsimulering i Azure Portal
- Gå till frågeredigeraren i Azure Portal och välj Jobbsimulering i det nedre fönstret. Den simulerar jobbet som kör topologin baserat på din fråga och fördefinierade strömningsenheter.
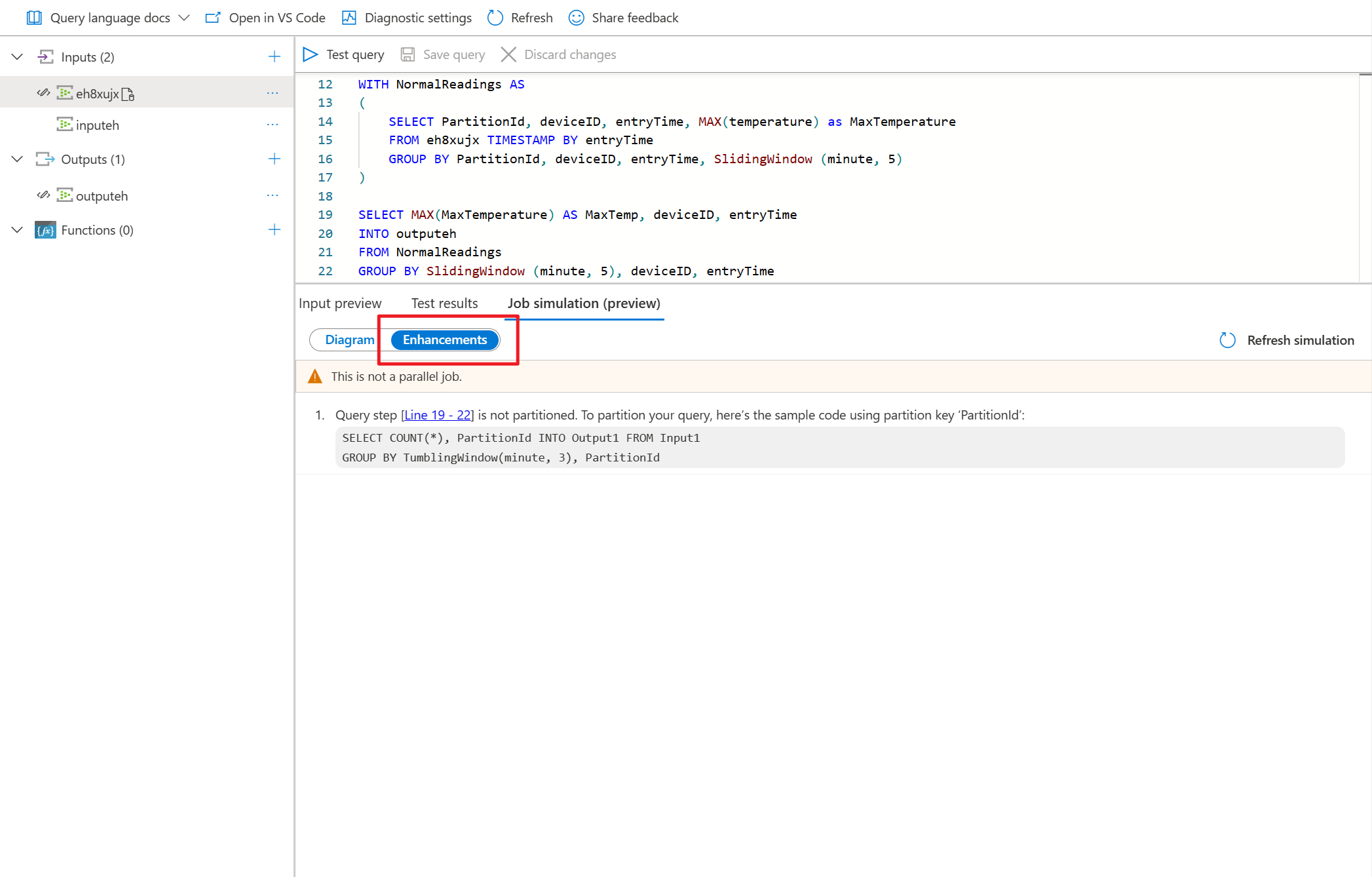
- Välj Förbättringar för att visa förslag på hur du kan förbättra frågeparallelliteten.
- Justera strömningsenheterna för att se hur många SU:er du behövde för att hantera arbetsbelastningen.
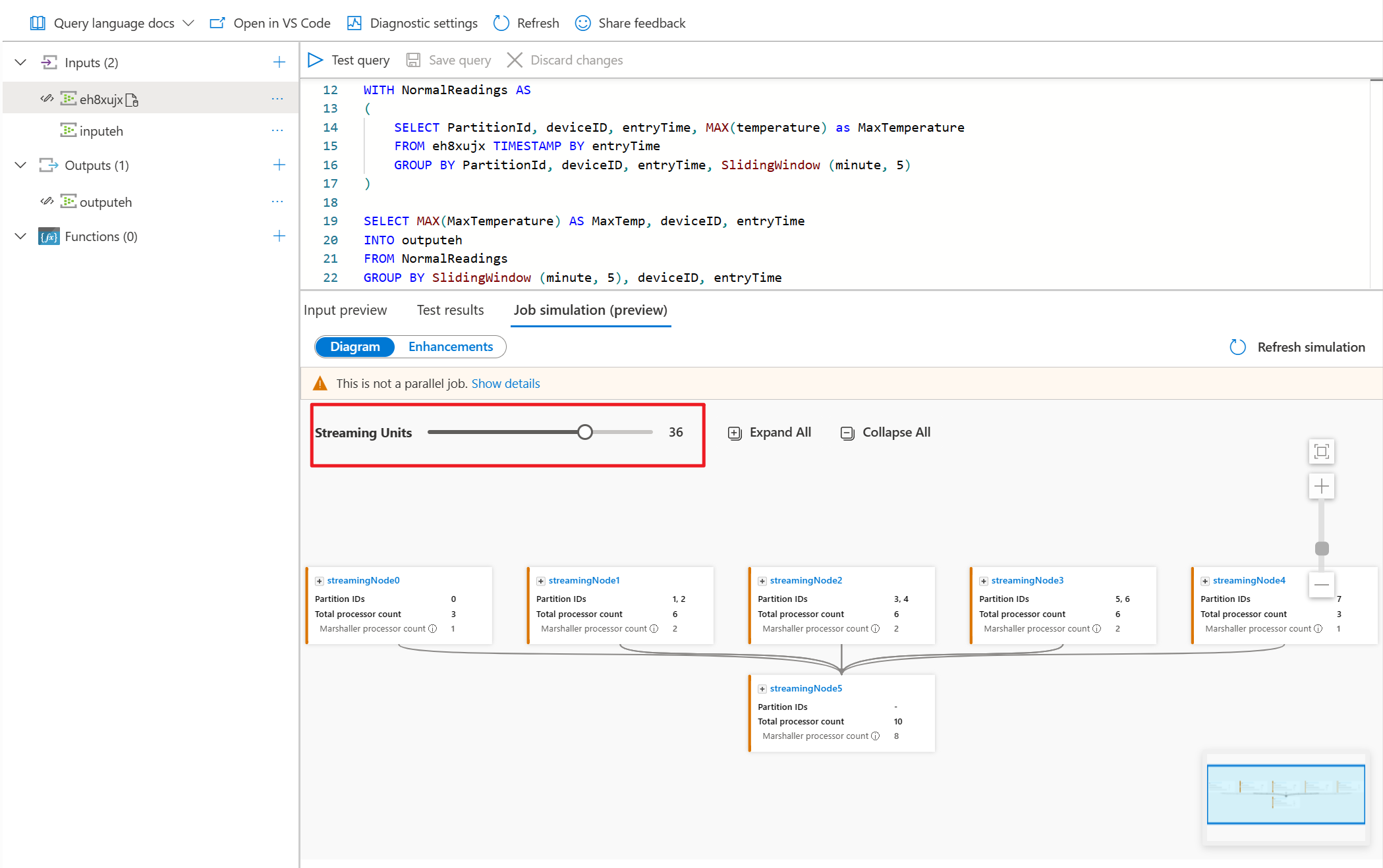



Diagram på processornivå
När du har justerat strömningsenheterna för att simulera jobbets topologi kan du expandera någon av de strömmande noderna för att se hur dina data bearbetas på processornivå.

Med diagrammet på processornivå kan du:
- observera hur indatapartitionerna allokeras och bearbetas på varje direktuppspelningsnod.
- ta reda på vad tidsskiftet är för varje databehandlingsprocessor.
- ange information om huruvida indata- och utdataprocessorerna är parallella.
Dubbelklicka på diagrammet om du vill mappa processorn med frågesteget. Den här funktionen hjälper dig att hitta frågestegen som utför aggregeringen.

Förslag på förbättringar
Här är förklaringarna till Förbättringar:
| Typ | Innebörd |
|---|---|
| Anpassad partition stöds inte | Ändra indatapartitionsnyckeln "xxx" till "xxx". |
| Antal partitioner som inte matchar | Indata och utdata måste ha samma antal partitioner. |
| Partitionsnycklar matchas inte | Indata, utdata och varje frågesteg måste använda samma partitionsnyckel. |
| Antal indatapartitioner som inte matchar | Alla indata måste ha samma antal partitioner. |
| Indatapartitionsnycklar matchas inte | Alla indata måste använda samma partitionsnyckel. |
| Låg kompatibilitetsnivå | Uppgradera CompatibilityLevel på filen JobConfig.json . |
| Det går inte att hitta utdatapartitionsnyckeln | Du måste använda den angivna partitionsnyckeln för utdata. |
| Anpassad partition stöds inte | Du kan bara använda fördefinierade partitionsnycklar. |
| Frågesteget använder inte partition | Frågan använder inte någon PARTITION BY-sats. |
Nästa steg
Om du vill veta mer om frågeparallellisering och jobbdiagram kan du läsa de här självstudierna: