Vad är affärskontinuitet, hög tillgänglighet och haveriberedskap?
Den här artikeln definierar och beskriver planering av affärskontinuitet och affärskontinuitet när det gäller riskhantering genom hög tillgänglighet och haveriberedskapsdesign. Även om den här artikeln inte ger explicit vägledning om hur du uppfyller dina egna affärskontinuitetsbehov, hjälper den dig att förstå de begrepp som används i Microsofts tillförlitlighetsvägledning.
Affärskontinuitet är det tillstånd där ett företag kan fortsätta sin verksamhet vid fel, avbrott eller katastrofer. Affärskontinuitet kräver proaktiv planering, förberedelse och implementering av motståndskraftiga system och processer.
Planering för affärskontinuitet kräver att identifiera, förstå, klassificera och hantera risker. Baserat på riskerna och deras sannolikheter utformar du för både hög tillgänglighet (HA) och haveriberedskap (DR).
Hög tillgänglighet handlar om att utforma en lösning som är motståndskraftig mot dagliga problem och för att uppfylla företagets behov av tillgänglighet.
Haveriberedskap handlar om att planera hur man ska hantera ovanliga risker och de katastrofala avbrott som kan uppstå.
Verksamhetskontinuitet
I allmänhet är molnlösningar direkt knutna till affärsåtgärder. När en molnlösning inte är tillgänglig eller upplever ett allvarligt problem kan påverkan på verksamheten vara allvarlig. En allvarlig inverkan kan bryta affärskontinuiteten.
Allvarliga effekter på affärskontinuiteten kan vara:
- Förlust av affärsinkomster.
- Det går inte att tillhandahålla en viktig tjänst till användarna.
- Brott mot ett åtagande som har gjorts till en kund eller en annan part.
Det är viktigt att förstå och förmedla företagets förväntningar och konsekvenserna av fel till viktiga intressenter, inklusive de som utformar, implementerar och hanterar arbetsbelastningen. Dessa intressenter svarar sedan genom att dela de kostnader som ingår i att uppfylla den visionen. Det finns vanligtvis en process med förhandlingar och revisioner av visionen baserat på budget och andra begränsningar.
Planering av affärskontinuitet
För att styra eller helt undvika en negativ inverkan på affärskontinuiteten är det viktigt att proaktivt skapa en affärskontinuitetsplan. En plan för affärskontinuitet bygger på riskbedömning och utvecklingsmetoder för att kontrollera dessa risker genom olika metoder. De specifika riskerna och metoderna för att minimera varierar för varje organisation och arbetsbelastning.
En affärskontinuitetsplan tar inte bara hänsyn till återhämtningsfunktionerna i själva molnplattformen utan även programmets funktioner. En robust affärskontinuitetsplan innehåller också alla aspekter av support i verksamheten, inklusive personer, affärsrelaterade manuella eller automatiserade processer och andra tekniker.
Planering av affärskontinuitet bör innehålla följande sekventiella steg:
Riskidentifiering. Identifiera risker för en arbetsbelastnings tillgänglighet eller funktioner. Möjliga risker kan vara nätverksproblem, maskinvarufel, mänskliga fel, regionfel osv. Förstå effekten av varje risk.
Riskklassificering. Klassificera varje risk som antingen en gemensam risk, som bör räknas in i planer för ha, eller en ovanlig risk, som bör ingå i DR-planeringen.
Riskreducering. Utforma riskreduceringsstrategier för HA eller DR för att minimera eller minimera risker, till exempel med hjälp av redundans, replikering, redundans och säkerhetskopior. Överväg även icke-tekniska och processbaserade åtgärder och kontroller.
Planering av affärskontinuitet är en process, inte en engångshändelse. Alla affärskontinuitetsplaner som skapas bör granskas och uppdateras regelbundet för att säkerställa att den förblir relevant och effektiv och att den stöder aktuella affärsbehov.
Riskidentifiering
Den inledande fasen i planeringen för affärskontinuitet är att identifiera risker för en arbetsbelastnings tillgänglighet eller funktioner. Varje risk bör analyseras för att förstå sannolikheten och dess allvarlighetsgrad. Allvarlighetsgraden måste omfatta eventuell stilleståndstid eller dataförlust, samt om några aspekter av resten av lösningsdesignen kan kompensera för negativa effekter.
Följande tabell är en icke-fullständig lista över risker, ordnade efter minskande sannolikhet:
| Exempelrisk | beskrivning | Regelbundenhet (sannolikhet) |
|---|---|---|
| Problem med tillfälligt nätverk | Ett tillfälligt fel i en komponent i nätverksstacken, som kan återställas efter en kort tid (vanligtvis några sekunder eller mindre). | Vanlig |
| Omstart av virtuell dator | En omstart av en virtuell dator som du använder eller som en beroende tjänst använder. Omstarter kan inträffa eftersom den virtuella datorn kraschar eller behöver tillämpa en korrigering. | Vanlig |
| Maskinvarufel | Ett fel på en komponent i ett datacenter, till exempel en maskinvarunod, ett rack eller ett kluster. | Tillfällig |
| Datacenterstopp | Ett avbrott som påverkar de flesta eller alla datacenter, till exempel strömavbrott, nätverksanslutningsproblem eller problem med uppvärmning och kylning. | Ovanlig |
| Regionstopp | Ett avbrott som påverkar ett helt storstadsområde eller större område, till exempel en stor naturkatastrof. | Mycket ovanligt |
Planering av affärskontinuitet handlar inte bara om molnplattformen och infrastrukturen. Det är viktigt att ta hänsyn till risken för mänskliga fel. Dessutom bör vissa risker som traditionellt kan betraktas som säkerhets-, prestanda- eller driftrisker även betraktas som tillförlitlighetsrisker eftersom de påverkar lösningens tillgänglighet.
Nedan följer några exempel:
| Exempelrisk | beskrivning |
|---|---|
| Dataförlust eller skada | Data har tagits bort, skrivits över eller på annat sätt skadats av en olycka eller från ett säkerhetsintrång som en utpressningstrojanattack. |
| Programfel | En distribution av ny eller uppdaterad kod introducerar ett fel som påverkar tillgängligheten eller integriteten, vilket gör att arbetsbelastningen inte fungerar. |
| Misslyckade distributioner | En distribution av en ny komponent eller version har misslyckats, vilket gör att lösningen är i ett inkonsekvent tillstånd. |
| Överbelastningsattacker | Systemet har attackerats i ett försök att förhindra legitim användning av lösningen. |
| Oseriösa administratörer | En användare med administratörsbehörighet har avsiktligt utfört en skadlig åtgärd mot systemet. |
| Oväntad tillströmning av trafik till ett program | En trafiktoppar har överbelastat systemets resurser. |
Analys av felläge (FMA) är en process för att identifiera potentiella sätt på vilka en arbetsbelastning eller dess komponenter kan misslyckas och hur lösningen beter sig i dessa situationer. Mer information finns i Rekommendationer för analys av felläge.
Riskklassificering
Affärskontinuitetsplaner måste hantera både vanliga och ovanliga risker.
Vanliga risker planeras och förväntas. I en molnmiljö är det till exempel vanligt att det uppstår tillfälliga fel , till exempel korta nätverksfel, omstarter av utrustning på grund av korrigeringar, tidsgränser när en tjänst är upptagen och så vidare. Eftersom dessa händelser inträffar regelbundet måste arbetsbelastningarna vara motståndskraftiga mot dem.
En strategi för hög tillgänglighet måste överväga och kontrollera varje risk av den här typen.
Ovanliga risker är vanligtvis resultatet av en oförutsedd händelse, till exempel en naturkatastrof eller större nätverksattack, som kan leda till ett katastrofalt avbrott.
Haveriberedskapsprocesser hanterar dessa sällsynta risker.
Hög tillgänglighet och haveriberedskap är sammankopplade och därför är det viktigt att planera strategier för dem båda tillsammans.
Det är viktigt att förstå att riskklassificeringen beror på arbetsbelastningsarkitekturen och affärskraven, och vissa risker kan klassificeras som HA för en arbetsbelastning och dr för en annan arbetsbelastning. Till exempel skulle ett fullständigt avbrott i Azure-regionen i allmänhet betraktas som en dr-risk för arbetsbelastningar i den regionen. Men för arbetsbelastningar som använder flera Azure-regioner i en aktiv-aktiv konfiguration med fullständig replikering, redundans och automatisk regionredundans klassificeras ett regionfel som en HA-risk.
Riskreducering
Riskreducering består av att utveckla strategier för HA eller DR för att minimera eller minimera risker för affärskontinuitet. Riskreducering kan vara teknikbaserad eller människobaserad.
Teknikbaserad riskreducering
Teknikbaserad riskreducering använder riskkontroller som baseras på hur arbetsbelastningen implementeras och konfigureras, till exempel:
- Redundans
- Datareplikering
- Redundans
- Säkerhetskopior
Teknikbaserade riskkontroller måste beaktas inom ramen för planen för affärskontinuitet.
Till exempel:
Krav på låg stilleståndstid. Vissa affärskontinuitetsplaner kan inte tolerera någon form av avbrottsrisk på grund av stränga krav på hög tillgänglighet . Det finns vissa teknikbaserade kontroller som kan kräva tid för en människa att meddelas och sedan svara. Teknikbaserade riskkontroller som omfattar långsamma manuella processer är sannolikt olämpliga för att ingå i riskreduceringsstrategin.
Tolerans mot partiella fel. Vissa affärskontinuitetsplaner kan tolerera ett arbetsflöde som körs i ett degraderat tillstånd. När en lösning fungerar i ett degraderat tillstånd kan vissa komponenter vara inaktiverade eller icke-funktionella, men kärnverksamheten kan fortsätta att utföras. Mer information finns i Rekommendationer för självåterställning och självbevarande.
Riskreducering baserad på människa
Riskreducering baserad på människa använder riskkontroller som baseras på affärsprocesser, till exempel:
- Utlöser en svarsspelbok.
- Återgår till manuella åtgärder.
- Utbildning och kulturella förändringar.
Viktigt!
Individer som utformar, implementerar, driver och utvecklar arbetsbelastningen bör vara kompetenta, uppmuntras att tala ut om de har problem och känna en ansvarskänsla för systemet.
Eftersom mänskligt baserade riskkontroller ofta är långsammare än teknikbaserade kontroller och mer utsatta för mänskliga fel, bör en bra affärskontinuitetsplan innehålla en formell förändringskontrollprocess för allt som skulle förändra tillståndet för det system som körs. Överväg till exempel att implementera följande processer:
- Testa dina arbetsbelastningar noggrant i enlighet med arbetsbelastningskritiskhet. För att förhindra ändringsrelaterade problem bör du testa eventuella ändringar som görs i arbetsbelastningen.
- Introducera strategiska kvalitetsgrindar som en del av arbetsbelastningens säkra distributionsmetoder. Mer information finns i Rekommendationer för säkra distributionsmetoder.
- Formalisera procedurer för ad hoc-produktionsåtkomst och datamanipulering. Dessa aktiviteter kan, oavsett hur små de är, utgöra en hög risk att orsaka tillförlitlighetsincidenter. Procedurerna kan omfatta parkoppling med en annan tekniker, användning av checklistor och att få peer-granskningar innan skript körs eller ändringar tillämpas.
Hög tillgänglighet
Hög tillgänglighet är det tillstånd där en specifik arbetsbelastning kan upprätthålla den nödvändiga drifttiden dagligen, även under tillfälliga fel och tillfälliga fel. Eftersom dessa händelser inträffar regelbundet är det viktigt att varje arbetsbelastning är utformad och konfigurerad för hög tillgänglighet i enlighet med kraven för det specifika programmet och kundens förväntningar. Ha för varje arbetsbelastning bidrar till din affärskontinuitetsplan.
Eftersom ha kan variera med varje arbetsbelastning är det viktigt att förstå kraven och kundernas förväntningar när man fastställer hög tillgänglighet. Till exempel kan ett program som din organisation använder för att beställa kontorsmaterial kräva en relativt låg drifttidsnivå, medan ett kritiskt ekonomiskt program kan kräva mycket högre drifttid. Även inom en arbetsbelastning kan olika flöden ha olika krav. I ett e-handelsprogram kan till exempel flöden som stöder kunders surfning och beställningar vara viktigare än orderuppfyllelse och bearbetningsflöden på serverkontor. Mer information om flöden finns i Rekommendationer för att identifiera och klassificera flöden.
Vanligtvis mäts drifttiden baserat på antalet "nior" i drifttidsprocenten. Drifttidsprocenten relaterar till hur mycket stilleståndstid du tillåter under en viss tidsperiod. Nedan följer några exempel:
- Ett drifttidskrav på 99,9 % (tre nior) möjliggör cirka 43 minuters stilleståndstid på en månad.
- Ett drifttidskrav på 99,95 % (tre och en halv nior) möjliggör cirka 21 minuters stilleståndstid under en månad.
Ju högre drifttidskrav, desto mindre tolerans har du för avbrott och desto mer arbete måste du göra för att nå den tillgänglighetsnivån. Drifttiden mäts inte av drifttiden för en enskild komponent som en nod, utan av den totala tillgängligheten för hela arbetsbelastningen.
Viktigt!
Överdriv inte lösningen för att nå högre tillförlitlighetsnivåer än vad som är motiverat. Använd affärskrav för att vägleda dina beslut.
Designelement med hög tillgänglighet
För att uppnå HA-krav kan en arbetsbelastning innehålla ett antal designelement. Några av de vanliga elementen visas och beskrivs nedan i det här avsnittet.
Kommentar
Vissa arbetsbelastningar är verksamhetskritiska, vilket innebär att eventuella driftstopp kan få allvarliga konsekvenser för människors liv och säkerhet eller stora ekonomiska förluster. Om du utformar en verksamhetskritisk arbetsbelastning finns det specifika saker du behöver tänka på när du utformar din lösning och hanterar din affärskontinuitet. Mer information finns i Azure Well-Architected Framework: Verksamhetskritiska arbetsbelastningar.
Azure-tjänster och -nivåer som stöder hög tillgänglighet
Många Azure-tjänster är utformade för att vara högtillgängliga och kan användas för att skapa arbetsbelastningar med hög tillgänglighet. Nedan följer några exempel:
- Skalningsuppsättningar för virtuella Azure-datorer ger hög tillgänglighet för virtuella datorer genom att automatiskt skapa och hantera virtuella datorinstanser och distribuera dessa VM-instanser för att minska effekten av infrastrukturfel.
- Azure App Service ger hög tillgänglighet via en mängd olika metoder, inklusive att automatiskt flytta arbetare från en nod som inte är felfri till en felfri nod, och genom att tillhandahålla funktioner för självåterställning från många vanliga feltyper.
Använd varje guide för tjänsttillförlitlighet för att förstå funktionerna i tjänsten, bestämma vilka nivåer som ska användas och avgöra vilka funktioner som ska ingå i din strategi för hög tillgänglighet.
Granska serviceavtalen (SLA) för varje tjänst för att förstå de förväntade tillgänglighetsnivåerna och de villkor som du behöver uppfylla. Du kan behöva välja eller undvika specifika nivåer av tjänster för att uppnå vissa tillgänglighetsnivåer. Vissa tjänster från Microsoft erbjuds med insikten att inget serviceavtal tillhandahålls, till exempel utvecklingsnivåer eller grundläggande nivåer, eller att resursen kan frigöras från ditt system som körs, till exempel spotbaserade erbjudanden. Vissa nivåer har också lagt till tillförlitlighetsfunktioner, till exempel stöd för tillgänglighetszoner.
Feltolerans
Feltolerans är möjligheten för ett system att fortsätta att fungera, i en viss definierad kapacitet, i händelse av ett fel. Ett webbprogram kan till exempel vara utformat för att fortsätta fungera även om en enskild webbserver misslyckas. Feltolerans kan uppnås genom redundans, redundans, partitionering, graciös nedbrytning och andra tekniker.
Feltolerans kräver också att dina program hanterar tillfälliga fel. När du skapar din egen kod kan du behöva aktivera tillfällig felhantering själv. Vissa Azure-tjänster tillhandahåller inbyggd tillfällig felhantering i vissa situationer. Som standard försöker till exempel Azure Logic Apps automatiskt skicka misslyckade begäranden till andra tjänster. Mer information finns i Rekommendationer för hantering av tillfälliga fel.
Redundans
Redundans är en metod för att duplicera instanser eller data för att öka arbetsbelastningens tillförlitlighet.
Redundans kan uppnås genom att distribuera repliker eller redundanta instanser på ytterligare ett av följande sätt:
- Inuti ett datacenter (lokal redundans)
- Mellan tillgänglighetszoner inom en region (zonredundans)
- Över regioner (geo-redundans).
Här följer några exempel på hur vissa Azure-tjänster tillhandahåller redundansalternativ:
- Med Azure App Service kan du köra flera instanser av ditt program för att säkerställa att programmet förblir tillgängligt även om en instans misslyckas. Om du aktiverar zonredundans sprids dessa instanser över flera tillgänglighetszoner i den Azure-region som du använder.
- Azure Storage ger hög tillgänglighet genom att automatiskt replikera data minst tre gånger. Du kan distribuera dessa repliker mellan tillgänglighetszoner genom att aktivera zonredundant lagring (ZRS), och i många regioner kan du också replikera dina lagringsdata mellan regioner med hjälp av geo-redundant lagring (GRS).
- Azure SQL Database har flera repliker för att säkerställa att data förblir tillgängliga även om en replik misslyckas.
Mer information om redundans finns i Rekommendationer för utformning av redundans och rekommendationer för användning av tillgänglighetszoner och regioner.
Skalbarhet och elasticitet
Skalbarhet och elasticitet är ett systems förmåga att hantera ökad belastning genom att lägga till och ta bort resurser (skalbarhet) och att göra det snabbt när dina krav ändras (elasticitet). Skalbarhet och elasticitet kan hjälpa ett system att upprätthålla tillgänglighet vid hög belastning.
Många Azure-tjänster stöder skalbarhet. Nedan följer några exempel:
- Azure Virtual Machine Scale Sets, Azure API Management och flera andra tjänster stöder autoskalning av Azure Monitor. Med autoskalning i Azure Monitor kan du ange principer som "när min CPU konsekvent överskrider 80 %, lägg till en annan instans".
- Azure Functions kan dynamiskt etablera instanser för att hantera dina begäranden.
- Azure Cosmos DB stöder autoskalningsdataflöde, där tjänsten automatiskt kan hantera de resurser som tilldelats till dina databaser baserat på principer som du anger.
Skalbarhet är en viktig faktor att tänka på vid partiellt eller fullständigt fel. Om en replik- eller beräkningsinstans inte är tillgänglig kan de återstående komponenterna behöva bära mer belastning för att hantera belastningen som tidigare hanterades av den felade noden. Överetablera om systemet inte kan skalas tillräckligt snabbt för att hantera förväntade belastningsändringar.
Mer information om hur du utformar ett skalbart och elastiskt system finns i Rekommendationer för att utforma en tillförlitlig skalningsstrategi.
Distributionstekniker med noll stilleståndstid
Distributioner och andra systemändringar medför en betydande risk för stilleståndstid. Eftersom driftavbrottsrisk är en utmaning för kraven på hög tillgänglighet är det viktigt att använda distributionsmetoder med noll driftstopp för att göra uppdateringar och konfigurationsändringar utan någon nödvändig stilleståndstid.
Distributionstekniker med noll stilleståndstid kan omfatta:
- Uppdatera en delmängd av dina resurser i taget.
- Kontrollera mängden trafik som når den nya distributionen.
- Övervakning för påverkan på dina användare eller system.
- Åtgärda problemet snabbt, till exempel genom att återställa till en tidigare känd distribution.
Mer information om distributionstekniker med noll driftstopp finns i Säkra distributionsmetoder.
Azure använder själv distributionsmetoder med noll stilleståndstid för våra egna tjänster. När du skapar egna program kan du använda distributioner utan avbrott genom en mängd olika metoder, till exempel:
- Azure Container Apps innehåller flera revisioner av ditt program, som kan användas för att uppnå distributioner med noll driftstopp.
- Azure Kubernetes Service (AKS) stöder en mängd olika tekniker för distribution utan avbrott.
Distributioner utan driftstopp är ofta associerade med programdistributioner, men de bör också användas för konfigurationsändringar. Här följer några sätt att tillämpa konfigurationsändringar på ett säkert sätt:
- Med Azure Storage kan du ändra åtkomstnycklarna för lagringskontot i flera steg, vilket förhindrar stilleståndstid under nyckelrotationsåtgärder.
- Azure App Configuration innehåller funktionsflaggor, ögonblicksbilder och andra funktioner som hjälper dig att styra hur konfigurationsändringar tillämpas.
Om du bestämmer dig för att inte implementera distributioner utan driftavbrott kontrollerar du att du definierar underhållsperioder så att du kan göra systemändringar vid en tidpunkt då användarna förväntar sig det.
Automatiserad testning
Det är viktigt att testa din lösnings förmåga att klara av de avbrott och fel som du anser vara i omfånget för HA. Många av dessa fel kan simuleras i testmiljöer. Att testa lösningens förmåga att automatiskt tolerera eller återställa från en mängd olika feltyper kallas för kaosteknik. Kaosteknik är avgörande för mogna organisationer med stränga standarder för HA. Azure Chaos Studio är ett verktyg för kaosteknik som kan simulera några vanliga feltyper.
Mer information finns i Rekommendationer för att utforma en strategi för tillförlitlighetstestning.
Övervakning och avisering
Med övervakning kan du känna till systemets hälsa, även när automatiserade åtgärder utförs. Övervakning är avgörande för att förstå hur din lösning fungerar och för att hålla utkik efter tidiga signaler om fel som ökad felfrekvens eller hög resursförbrukning. Med aviseringar kan du proaktivt ta emot viktiga ändringar i din miljö.
Azure tillhandahåller en mängd olika funktioner för övervakning och aviseringar, inklusive följande:
- Azure Monitor samlar in loggar och mått från Azure-resurser och program och kan skicka aviseringar och visa data på instrumentpaneler.
- Azure Monitor Application Insights tillhandahåller detaljerad övervakning av dina program.
- Azure Service Health och Azure Resource Health övervakar hälsotillståndet för Azure-plattformen och dina resurser.
- Schemalagda händelser meddelar när underhåll planeras för virtuella datorer.
Mer information finns i Rekommendationer för att utforma en tillförlitlig övervaknings- och aviseringsstrategi.
Haveriberedskap
En katastrof är en distinkt, ovanlig, större händelse som har en större och mer långvarig inverkan än ett program kan minimera genom den höga tillgänglighetsaspekten av dess design. Exempel på katastrofer är:
- Naturkatastrofer, till exempel orkaner, jordbävningar, översvämningar eller bränder.
- Mänskliga fel som resulterar i en stor inverkan, till exempel oavsiktligt borttagning av produktionsdata eller en felkonfigurerad brandvägg som exponerar känsliga data.
- Större säkerhetsincidenter, till exempel överbelastningsattacker eller utpressningstrojanattacker som leder till datakorruption, dataförlust eller avbrott i tjänsten.
Haveriberedskap handlar om att planera hur du ska hantera den här typen av situationer.
Kommentar
Du bör följa rekommenderade metoder i hela lösningen för att minimera sannolikheten för dessa händelser. Men även efter noggrann proaktiv planering är det klokt att planera hur du skulle reagera på dessa situationer om de uppstår.
Krav för haveriberedskap
På grund av katastrofhändelsernas sällsynthet och allvarlighetsgrad ger DR-planering olika förväntningar på ditt svar. Många organisationer accepterar att det i ett katastrofscenario är en viss nivå av stilleståndstid eller dataförlust oundviklig. En fullständig DR-plan måste ange följande viktiga affärskrav för varje flöde:
Mål för återställningspunkt (RPO) är den maximala varaktigheten för acceptabel dataförlust i händelse av en katastrof. RPO mäts i tidsenheter, till exempel "30 minuters data" eller "fyra timmars data".
Mål för återställningstid (RTO) är den maximala varaktigheten för acceptabel stilleståndstid i händelse av en katastrof, där "stilleståndstid" definieras av din specifikation. RTO mäts också i tidsenheter, som "åtta timmars stilleståndstid".
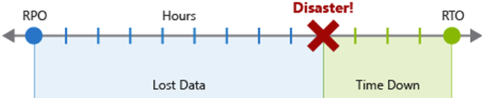
Varje komponent eller flöde i arbetsbelastningen kan ha enskilda RPO- och RTO-värden. Granska risker i katastrofscenariot och potentiella återställningsstrategier när du beslutar om kraven. Processen med att ange ett RPO och RTO skapar effektivt dr-krav för din arbetsbelastning som ett resultat av dina unika affärsproblem (kostnader, påverkan, dataförlust osv.).
Kommentar
Även om det är frestande att sikta på en RTO och RPO på noll (ingen stilleståndstid och ingen dataförlust i händelse av en katastrof), är det i praktiken svårt och kostsamt att implementera. Det är viktigt att tekniska intressenter och affärsintressenter diskuterar dessa krav tillsammans och beslutar om realistiska krav. Mer information finns i Rekommendationer för att definiera tillförlitlighetsmål.
Planer för haveriberedskap
Oavsett orsaken till katastrofen är det viktigt att du skapar en väldefinierad och testbar DR-plan. Planen kommer att användas som en del av infrastrukturen och programdesignen för att aktivt stödja den. Du kan skapa flera DR-planer för olika typer av situationer. DR-planer förlitar sig ofta på processkontroller och manuella åtgärder.
DR är inte en automatisk funktion i Azure. Många tjänster tillhandahåller dock funktioner som du kan använda för att stödja dina DR-strategier. Du bör gå igenom tillförlitlighetsguiderna för varje Azure-tjänst för att förstå hur tjänsten fungerar och dess funktioner och sedan mappa dessa funktioner till din DR-plan.
I följande avsnitt visas några vanliga element i en haveriberedskapsplan och beskriver hur Azure kan hjälpa dig att uppnå dem.
Redundans och återställning efter fel
Vissa planer för haveriberedskap omfattar etablering av en sekundär distribution på en annan plats. Om en katastrof påverkar den primära distributionen av lösningen kan trafiken sedan redväxas till den andra platsen. Redundans kräver noggrann planering och implementering. Azure tillhandahåller en mängd olika tjänster för att hjälpa till med redundansväxling, till exempel:
- Azure Site Recovery tillhandahåller automatiserad redundans för lokala miljöer och lösningar för virtuella datorer i Azure.
- Azure Front Door och Azure Traffic Manager stöder automatisk redundansväxling av inkommande trafik mellan olika distributioner av din lösning, till exempel i olika regioner.
Det tar vanligtvis lite tid för en redundansprocess att identifiera att den primära instansen har misslyckats och växla till den sekundära instansen. Kontrollera att RTO för arbetsbelastningen är i linje med redundanstiden.
Det är också viktigt att överväga återställning efter fel, vilket är den process som du återställer åtgärder i den primära regionen efter att den har återställts. Återställning efter fel kan vara komplext att planera och implementera. Data i den primära regionen kan till exempel ha skrivits när redundansväxlingen har påbörjats. Du måste fatta noggranna affärsbeslut om hur du hanterar dessa data.
Säkerhetskopior
Säkerhetskopior omfattar att ta en kopia av dina data och lagra dem på ett säkert sätt under en definierad tidsperiod. Med säkerhetskopior kan du återställa från katastrofer när automatisk redundansväxling till en annan replik inte är möjlig, eller när data skadats.
När du använder säkerhetskopior som en del av en haveriberedskapsplan är det viktigt att tänka på följande:
Lagringsplats. När du använder säkerhetskopior som en del av en haveriberedskapsplan bör de lagras separat till huvuddata. Säkerhetskopior lagras vanligtvis i en annan Azure-region.
Dataförlust. Eftersom säkerhetskopieringar vanligtvis görs sällan innebär återställning av säkerhetskopiering vanligtvis dataförlust. Därför bör säkerhetskopieringsåterställning användas som en sista utväg och en plan för haveriberedskap bör ange den sekvens med steg och återställningsförsök som måste utföras innan du återställer från en säkerhetskopia. Det är viktigt att se till att arbetsbelastningens RPO är i linje med säkerhetskopieringsintervallet.
Återställningstid. Återställning av säkerhetskopior tar ofta tid, så det är viktigt att testa dina säkerhetskopieringar och återställningsprocesser för att verifiera deras integritet och förstå hur lång tid återställningsprocessen tar. Kontrollera att arbetsbelastningens RTO står för den tid det tar att återställa säkerhetskopian.
Många Azure-data- och lagringstjänster stöder säkerhetskopieringar, till exempel följande:
- Azure Backup tillhandahåller automatiserade säkerhetskopieringar för virtuella datordiskar, lagringskonton, AKS och en mängd andra källor.
- Många Azure-databastjänster, inklusive Azure SQL Database och Azure Cosmos DB, har en automatiserad säkerhetskopieringsfunktion för dina databaser.
- Azure Key Vault innehåller funktioner för att säkerhetskopiera hemligheter, certifikat och nycklar.
Automatiserade distributioner
Om du snabbt vill distribuera och konfigurera nödvändiga resurser i händelse av ett haveri använder du IaC-tillgångar (Infrastruktur som kod), till exempel Bicep-filer, ARM-mallar eller Terraform-konfigurationsfil. Om du använder IaC minskar du återställningstiden och risken för fel, jämfört med att distribuera och konfigurera resurser manuellt.
Testning och övningar
Det är viktigt att rutinmässigt validera och testa dina DR-planer samt din bredare tillförlitlighetsstrategi. Inkludera alla mänskliga processer i dina övningar och fokusera inte bara på de tekniska processerna.
Om du inte har testat dina återställningsprocesser i en katastrofsimulering är det mer troligt att du får stora problem när du använder dem i en verklig katastrof. Genom att testa dina DR-planer och nödvändiga processer kan du också verifiera möjligheten för din RTO.
Mer information finns i Rekommendationer för att utforma en strategi för tillförlitlighetstestning.
Relaterat innehåll
- Använd tillförlitlighetsguiderna för Azure-tjänsten för att förstå hur varje Azure-tjänst stöder tillförlitlighet i sin design och för att lära dig mer om de funktioner som du kan bygga in i dina HA- och DR-planer.
- Använd grundpelare för Azure Well-Architected Framework: Reliability för att lära dig mer om hur du utformar en tillförlitlig arbetsbelastning i Azure.
- Använd perspektivet Well-Architected Framework på Azure-tjänster för att lära dig mer om hur du konfigurerar varje Azure-tjänst för att uppfylla dina krav på tillförlitlighet och över de andra grundpelarna i det välarkitekterade ramverket.
- Mer information om planering av haveriberedskap finns i Rekommendationer för att utforma en strategi för haveriberedskap.