Distribuera en IoT Edge-arbetsbelastning med GPU-delning i Azure Stack Edge Pro
Den här artikeln beskriver hur containerbaserade arbetsbelastningar kan dela GPU:er på din Azure Stack Edge Pro GPU-enhet. Metoden innebär att aktivera multiprocesstjänsten (MPS) och sedan ange GPU-arbetsbelastningarna via en IoT Edge-distribution.
Förutsättningar
Innan du börjar bör du kontrollera att:
Du har åtkomst till en Azure Stack Edge Pro GPU-enhet som är aktiverad och har konfigurerat beräkning. Du har Kubernetes API-slutpunkten och du har lagt till den här slutpunkten i
hostsfilen på klienten som ska komma åt enheten.Du har åtkomst till ett klientsystem med ett operativsystem som stöds. Om du använder en Windows-klient ska systemet köra PowerShell 5.0 eller senare för att få åtkomst till enheten.
Spara följande distribution
jsoni det lokala systemet. Du använder information från den här filen för att köra IoT Edge-distributionen. Den här distributionen baseras på enkla CUDA-containrar som är offentligt tillgängliga från Nvidia.{ "modulesContent": { "$edgeAgent": { "properties.desired": { "modules": { "cuda-sample1": { "settings": { "image": "nvidia/samples:nbody", "createOptions": "{\"Entrypoint\":[\"/bin/sh\"],\"Cmd\":[\"-c\",\"/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done\"],\"HostConfig\":{\"IpcMode\":\"host\",\"PidMode\":\"host\"}}" }, "type": "docker", "version": "1.0", "env": { "NVIDIA_VISIBLE_DEVICES": { "value": "0" } }, "status": "running", "restartPolicy": "never" }, "cuda-sample2": { "settings": { "image": "nvidia/samples:nbody", "createOptions": "{\"Entrypoint\":[\"/bin/sh\"],\"Cmd\":[\"-c\",\"/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done\"],\"HostConfig\":{\"IpcMode\":\"host\",\"PidMode\":\"host\"}}" }, "type": "docker", "version": "1.0", "env": { "NVIDIA_VISIBLE_DEVICES": { "value": "0" } }, "status": "running", "restartPolicy": "never" } }, "runtime": { "settings": { "minDockerVersion": "v1.25" }, "type": "docker" }, "schemaVersion": "1.1", "systemModules": { "edgeAgent": { "settings": { "image": "mcr.microsoft.com/azureiotedge-agent:1.0", "createOptions": "" }, "type": "docker" }, "edgeHub": { "settings": { "image": "mcr.microsoft.com/azureiotedge-hub:1.0", "createOptions": "{\"HostConfig\":{\"PortBindings\":{\"443/tcp\":[{\"HostPort\":\"443\"}],\"5671/tcp\":[{\"HostPort\":\"5671\"}],\"8883/tcp\":[{\"HostPort\":\"8883\"}]}}}" }, "type": "docker", "status": "running", "restartPolicy": "always" } } } }, "$edgeHub": { "properties.desired": { "routes": { "route": "FROM /messages/* INTO $upstream" }, "schemaVersion": "1.1", "storeAndForwardConfiguration": { "timeToLiveSecs": 7200 } } }, "cuda-sample1": { "properties.desired": {} }, "cuda-sample2": { "properties.desired": {} } } }
Verifiera GPU-drivrutin, CUDA-version
Det första steget är att kontrollera att enheten kör nödvändig GPU-drivrutin och CUDA-versioner.
Kör följande kommando:
Get-HcsGpuNvidiaSmiAnteckna GPU-versionen och CUDA-versionen på enheten i Nvidia smi-utdata. Om du kör Programvara för Azure Stack Edge 2102 motsvarar den här versionen följande drivrutinsversioner:
- GPU-drivrutinsversion: 460.32.03
- CUDA-version: 11.2
Här är ett exempel på utdata:
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Tue Feb 23 10:34:01 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 0000041F:00:00.0 Off | 0 | | N/A 40C P8 15W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Håll den här sessionen öppen eftersom du kommer att använda den för att visa Nvidia smi-utdata i hela artikeln.
Distribuera utan kontextdelning
Nu kan du distribuera ett program på enheten när multiprocesstjänsten inte körs och det inte finns någon kontextdelning. Distributionen sker via Azure-portalen i namnområdet iotedge som finns på enheten.
Skapa användare i IoT Edge-namnområdet
Först skapar du en användare som ansluter till iotedge namnområdet. IoT Edge-modulerna distribueras i iotedge-namnområdet. Mer information finns i Kubernetes-namnområden på enheten.
Följ de här stegen för att skapa en användare och ge användaren åtkomst till iotedge namnområdet.
Skapa en ny användare i
iotedgenamnområdet. Kör följande kommando:New-HcsKubernetesUser -UserName <user name>Här är ett exempel på utdata:
[10.100.10.10]: PS>New-HcsKubernetesUser -UserName iotedgeuser apiVersion: v1 clusters: - cluster: certificate-authority-data: ===========================//snipped //======================// snipped //============================= server: https://compute.myasegpudev.wdshcsso.com:6443 name: kubernetes contexts: - context: cluster: kubernetes user: iotedgeuser name: iotedgeuser@kubernetes current-context: iotedgeuser@kubernetes kind: Config preferences: {} users: - name: iotedgeuser user: client-certificate-data: ===========================//snipped //======================// snipped //============================= client-key-data: ===========================//snipped //======================// snipped ============================ PQotLS0tLUVORCBSU0EgUFJJVkFURSBLRVktLS0tLQo=Kopiera utdata som visas i oformaterad text. Spara utdata som en konfigurationsfil (utan tillägg) i
.kubemappen för din användarprofil på den lokala datorn, till exempelC:\Users\<username>\.kube.Ge användaren som du skapade åtkomst till
iotedgenamnområdet. Kör följande kommando:Grant-HcsKubernetesNamespaceAccess -Namespace iotedge -UserName <user name>Här är ett exempel på utdata:
[10.100.10.10]: PS>Grant-HcsKubernetesNamespaceAccess -Namespace iotedge -UserName iotedgeuser [10.100.10.10]: PS>
Detaljerade instruktioner finns i Anslut till och hantera ett Kubernetes-kluster via kubectl på din Azure Stack Edge Pro GPU-enhet.
Distribuera moduler via portalen
Distribuera IoT Edge-moduler via Azure-portalen. Du distribuerar offentligt tillgängliga Nvidia CUDA-exempelmoduler som kör n-body-simulering.
Kontrollera att IoT Edge-tjänsten körs på enheten.
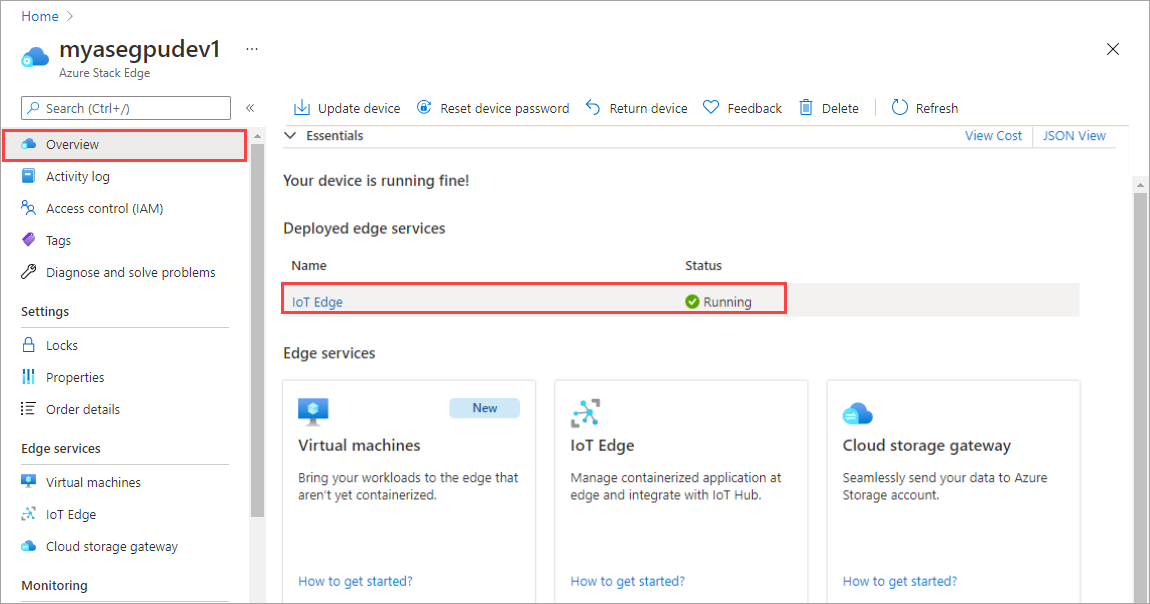
Välj IoT Edge-panelen i den högra rutan. Gå till IoT Edge-egenskaper>. I den högra rutan väljer du den IoT Hub-resurs som är associerad med enheten.
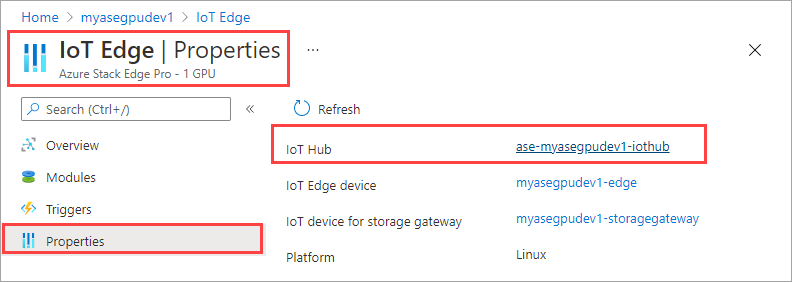
I IoT Hub-resursen går du till Automatisk Enhetshantering > IoT Edge. I den högra rutan väljer du den IoT Edge-enhet som är associerad med enheten.
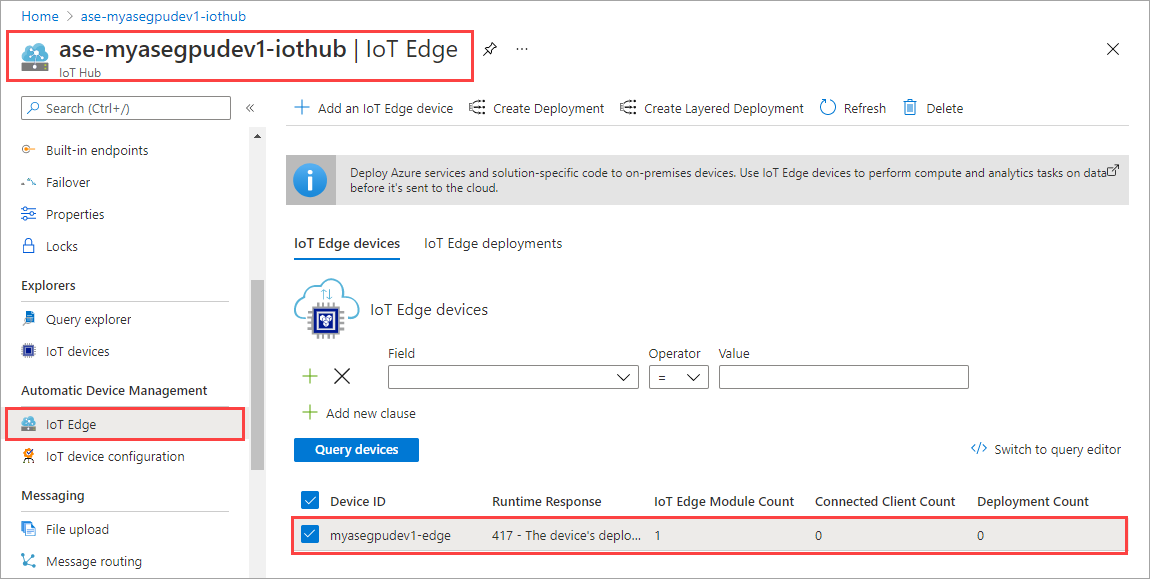
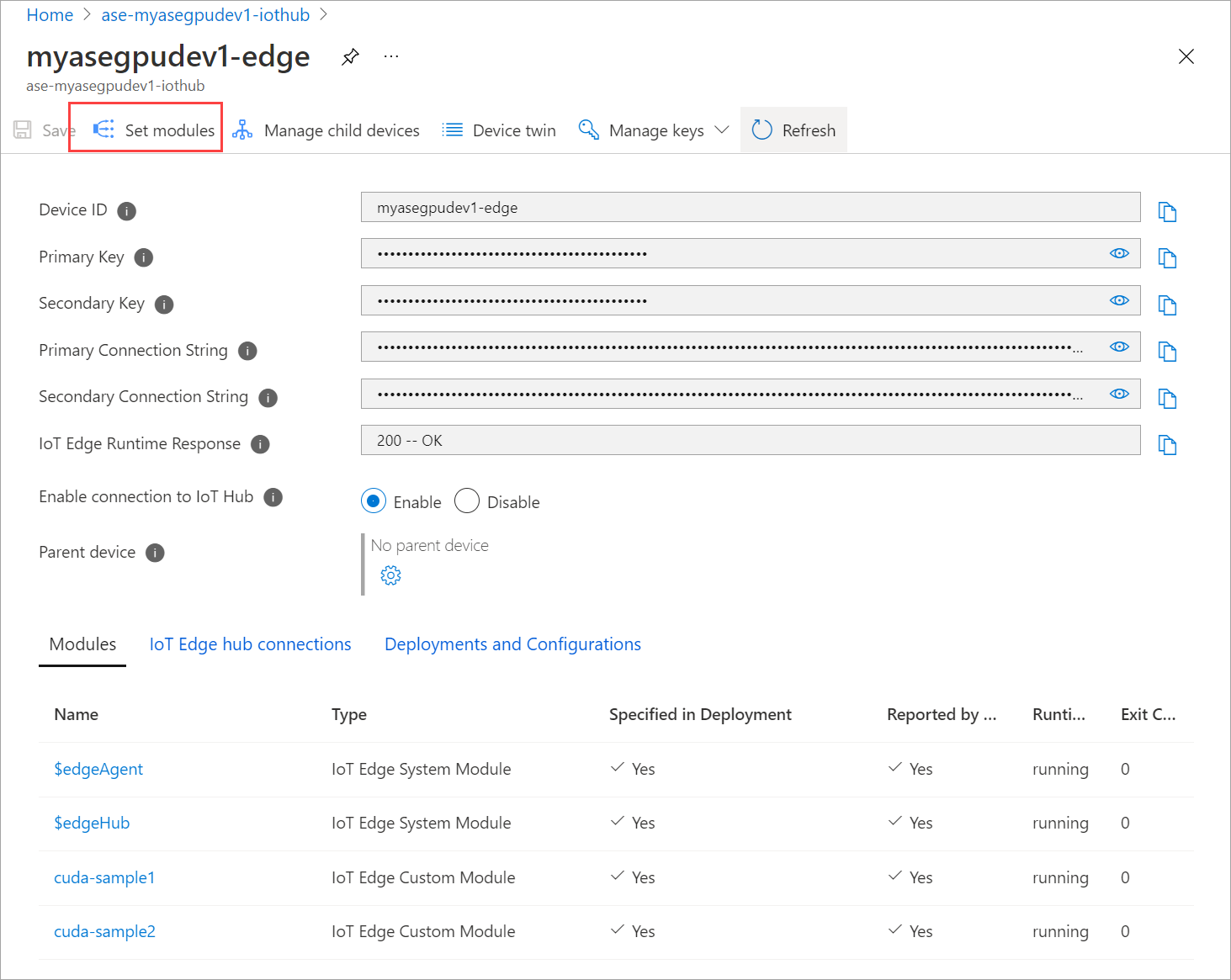
Välj Ange moduler.
Välj + Lägg till > + IoT Edge-modul.
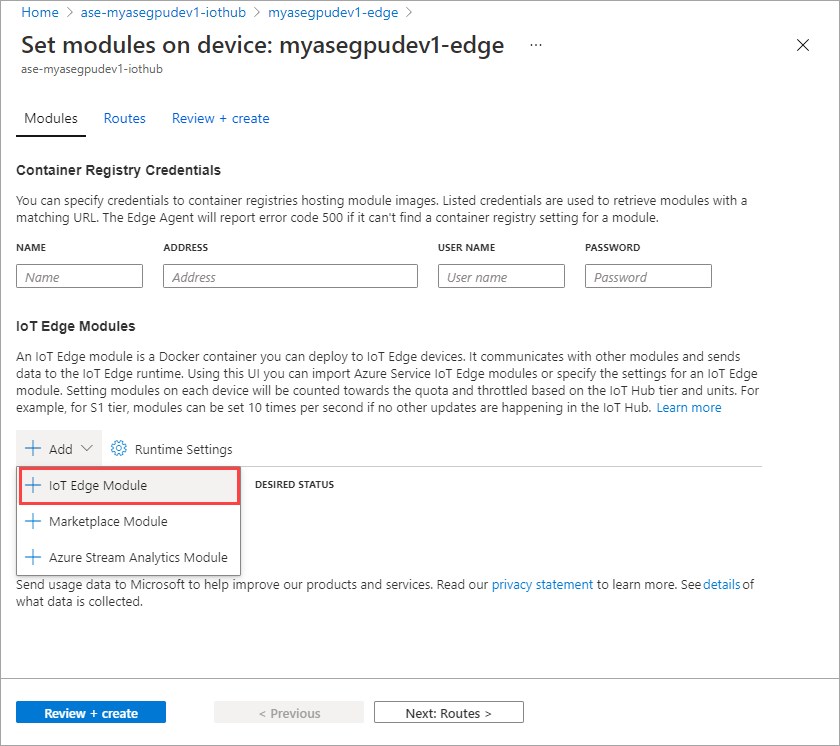
På fliken Modul Inställningar anger du IoT Edge-modulens namn och bild-URI. Ange Avbildnings pull-princip till Vid skapande.
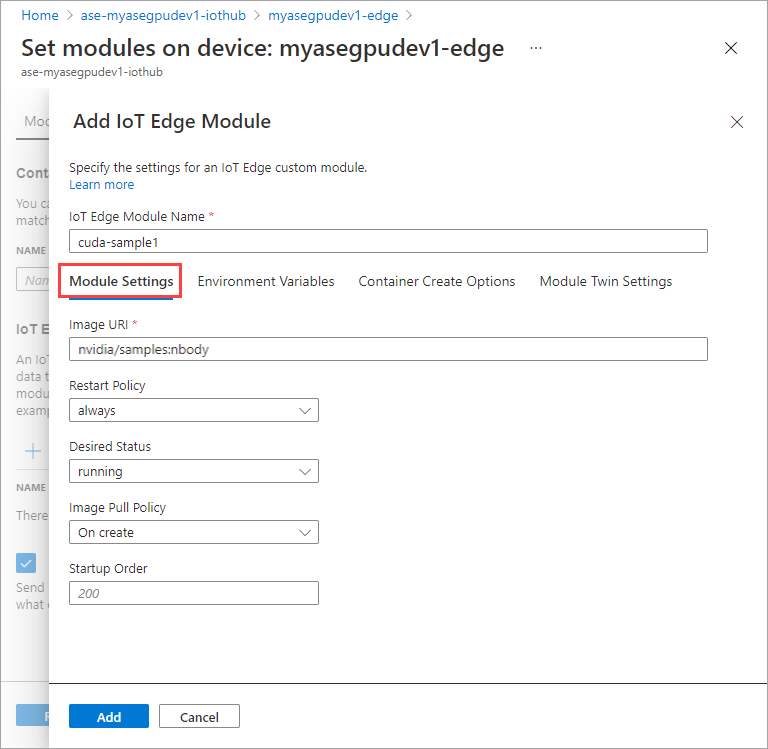
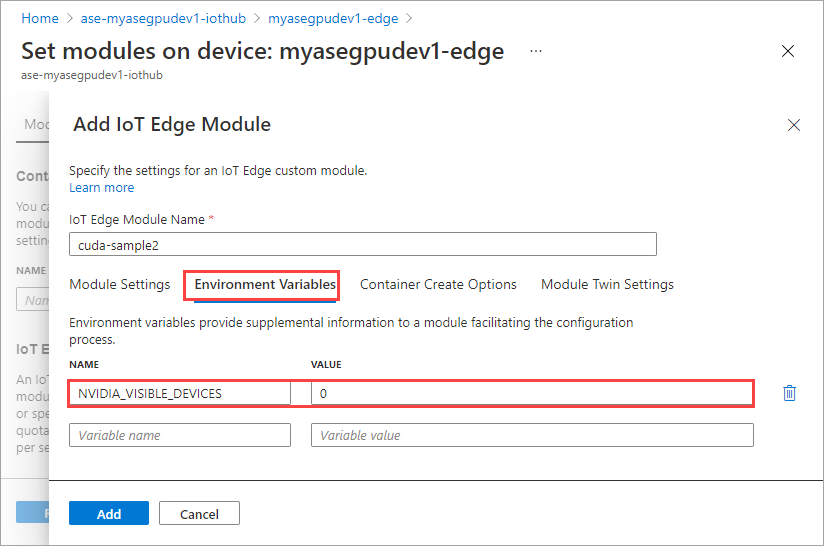
På fliken Miljövariabler anger du NVIDIA_VISIBLE_DEVICES som 0.
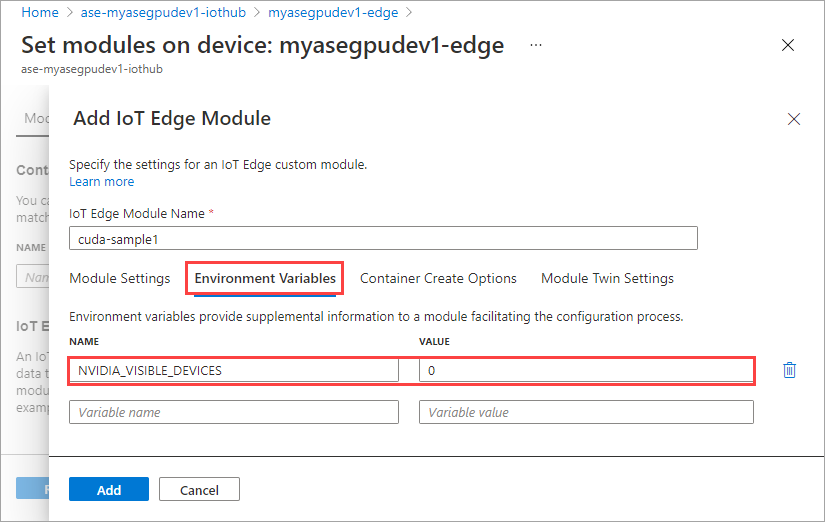
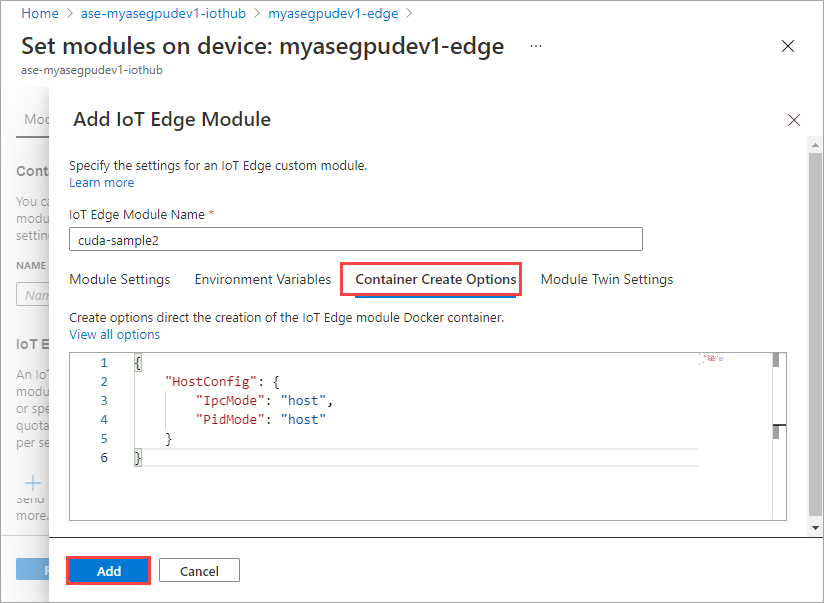
På fliken Alternativ för att skapa container anger du följande alternativ:
{ "Entrypoint": [ "/bin/sh" ], "Cmd": [ "-c", "/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done" ], "HostConfig": { "IpcMode": "host", "PidMode": "host" } }Alternativen visas på följande sätt:
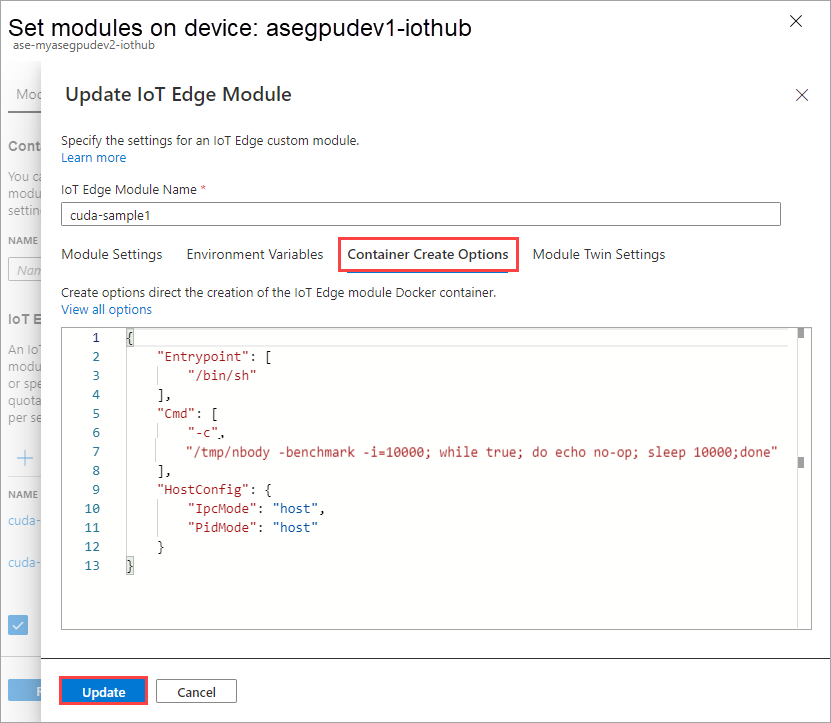
Markera Lägga till.
Modulen som du lade till ska visas som Körs.
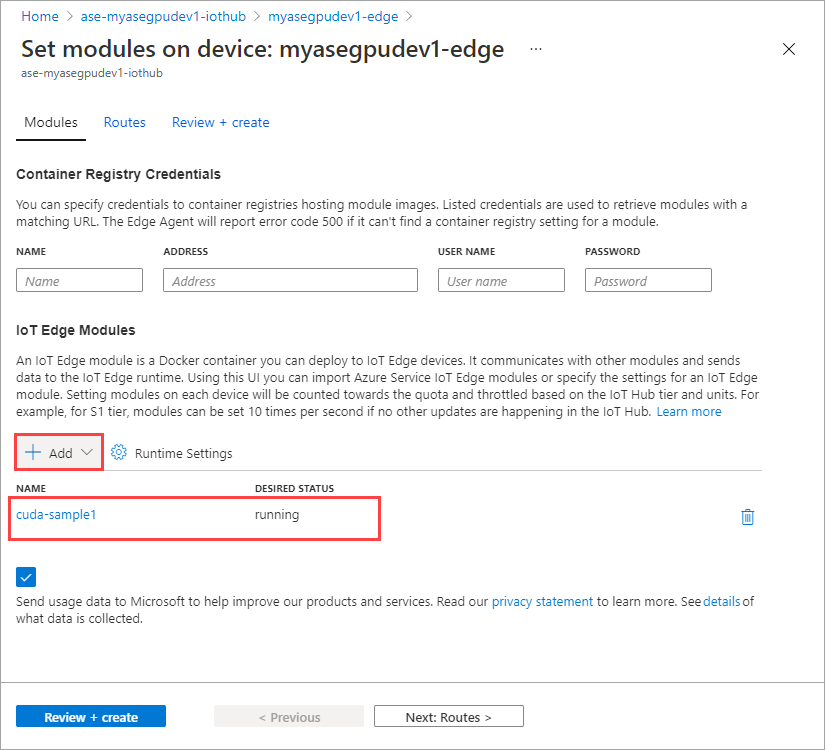
Upprepa alla steg för att lägga till en modul som du följde när du lade till den första modulen. I det här exemplet anger du namnet på modulen som
cuda-sample2.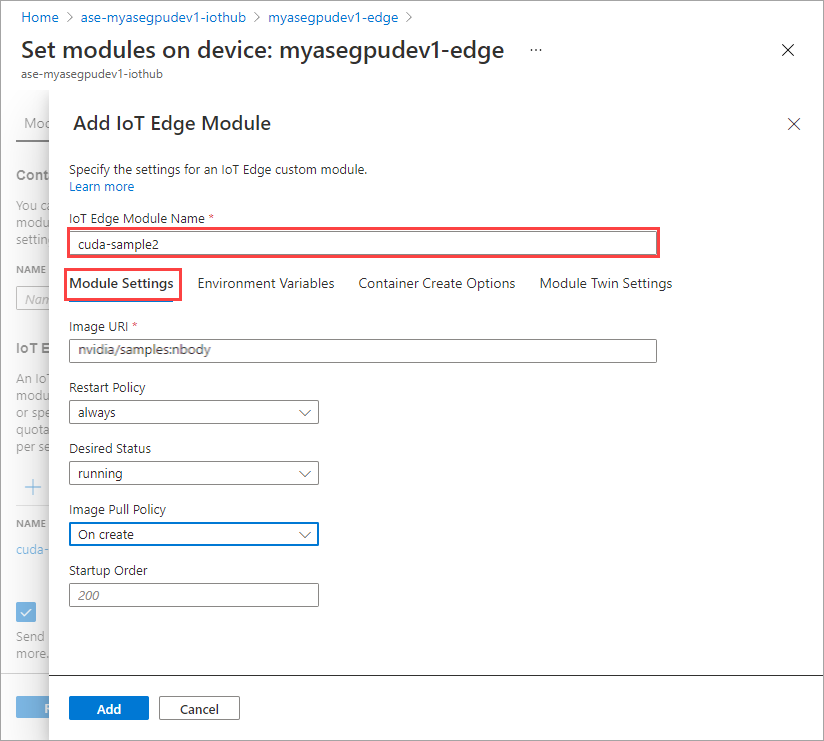
Använd samma miljövariabel som båda modulerna delar samma GPU.
Använd samma alternativ för att skapa containrar som du angav för den första modulen och välj Lägg till.
På sidan Ange moduler väljer du Granska + Skapa och sedan Skapa.
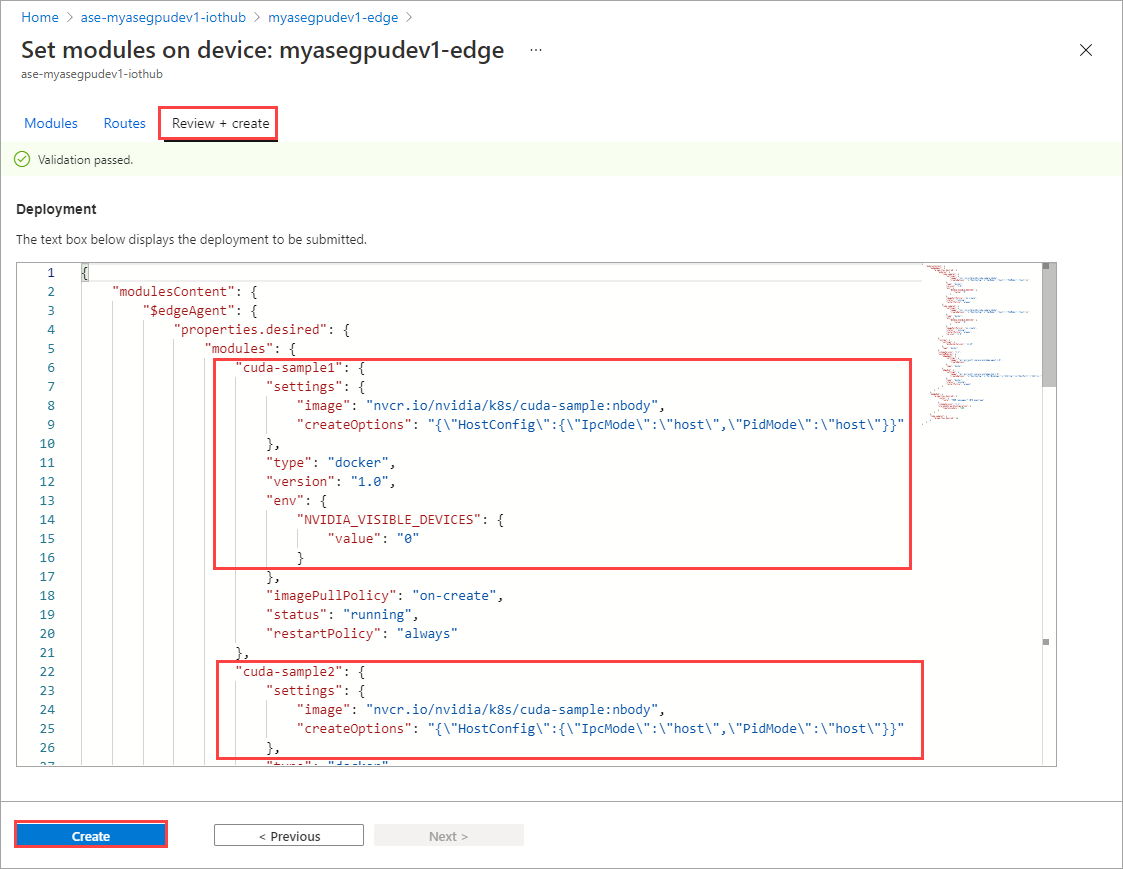
Körningsstatusen för båda modulerna bör nu visas som Körs.
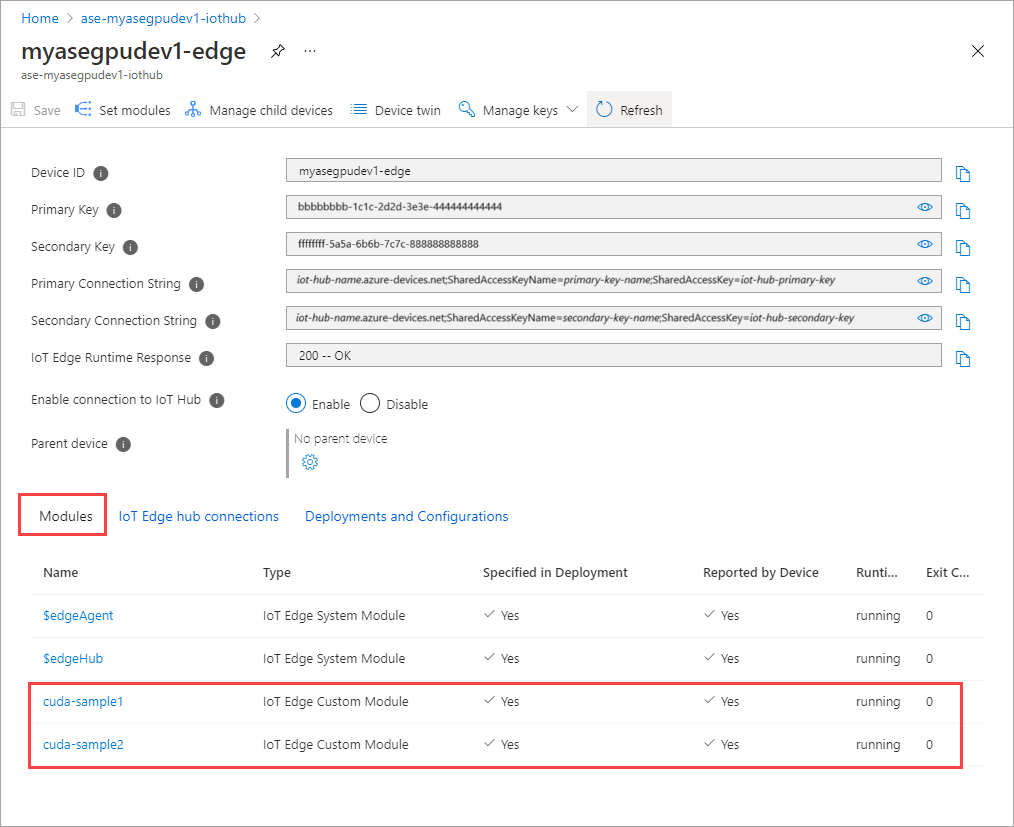
Övervaka distribution av arbetsbelastningar
Öppna en ny PowerShell-session.
Visa en lista över poddar som körs i
iotedgenamnområdet. Kör följande kommando:kubectl get pods -n iotedgeHär är ett exempel på utdata:
PS C:\WINDOWS\system32> kubectl get pods -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 NAME READY STATUS RESTARTS AGE cuda-sample1-869989578c-ssng8 2/2 Running 0 5s cuda-sample2-6db6d98689-d74kb 2/2 Running 0 4s edgeagent-79f988968b-7p2tv 2/2 Running 0 6d21h edgehub-d6c764847-l8v4m 2/2 Running 0 24h iotedged-55fdb7b5c6-l9zn8 1/1 Running 1 6d21h PS C:\WINDOWS\system32>Det finns två poddar
cuda-sample1-97c494d7f-lnmnsochcuda-sample2-d9f6c4688-2rld9körs på enheten.Medan båda containrarna kör n-body-simuleringen kan du visa GPU-användningen från Nvidia smi-utdata. Gå till PowerShell-gränssnittet på enheten och kör
Get-HcsGpuNvidiaSmi.Här är ett exempel på utdata när båda containrarna kör n-body-simuleringen:
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Fri Mar 5 13:31:16 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 52C P0 69W / 70W | 221MiB / 15109MiB | 100% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 188342 C /tmp/nbody 109MiB | | 0 N/A N/A 188413 C /tmp/nbody 109MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Som du ser finns det två containrar som körs med n-body-simulering på GPU 0. Du kan också visa deras motsvarande minnesanvändning.
När simuleringen är klar visar Nvidia smi-utdata att det inte finns några processer som körs på enheten.
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Fri Mar 5 13:54:48 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 34C P8 9W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>När n-body-simuleringen har slutförts visar du loggarna för att förstå information om distributionen och den tid som krävs för att simuleringen ska slutföras.
Här är ett exempel på utdata från den första containern:
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample1-869989578c-ssng8 cuda-sample1 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 170171.531 ms = 98.590 billion interactions per second = 1971.801 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Här är ett exempel på utdata från den andra containern:
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample2-6db6d98689-d74kb cuda-sample2 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 170054.969 ms = 98.658 billion interactions per second = 1973.152 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Stoppa moduldistributionen. I IoT Hub-resursen för din enhet:
Gå till IoT Edge för automatisk enhetsdistribution>. Välj den IoT Edge-enhet som motsvarar din enhet.
Gå till Ange moduler och välj en modul.
På fliken Moduler väljer du en modul.
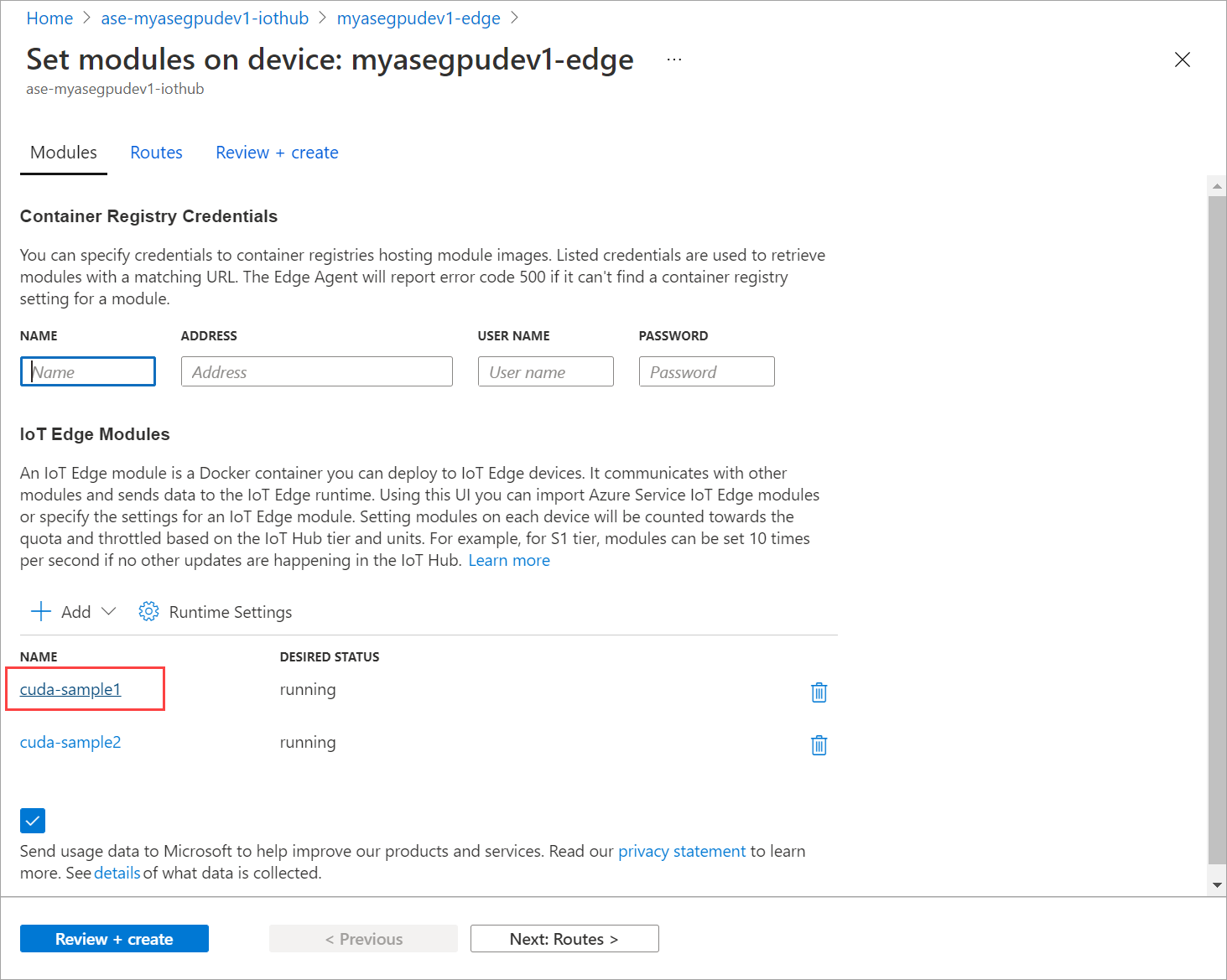
På fliken Modulinställningar anger du Önskad status till stoppad. Välj Uppdatera.
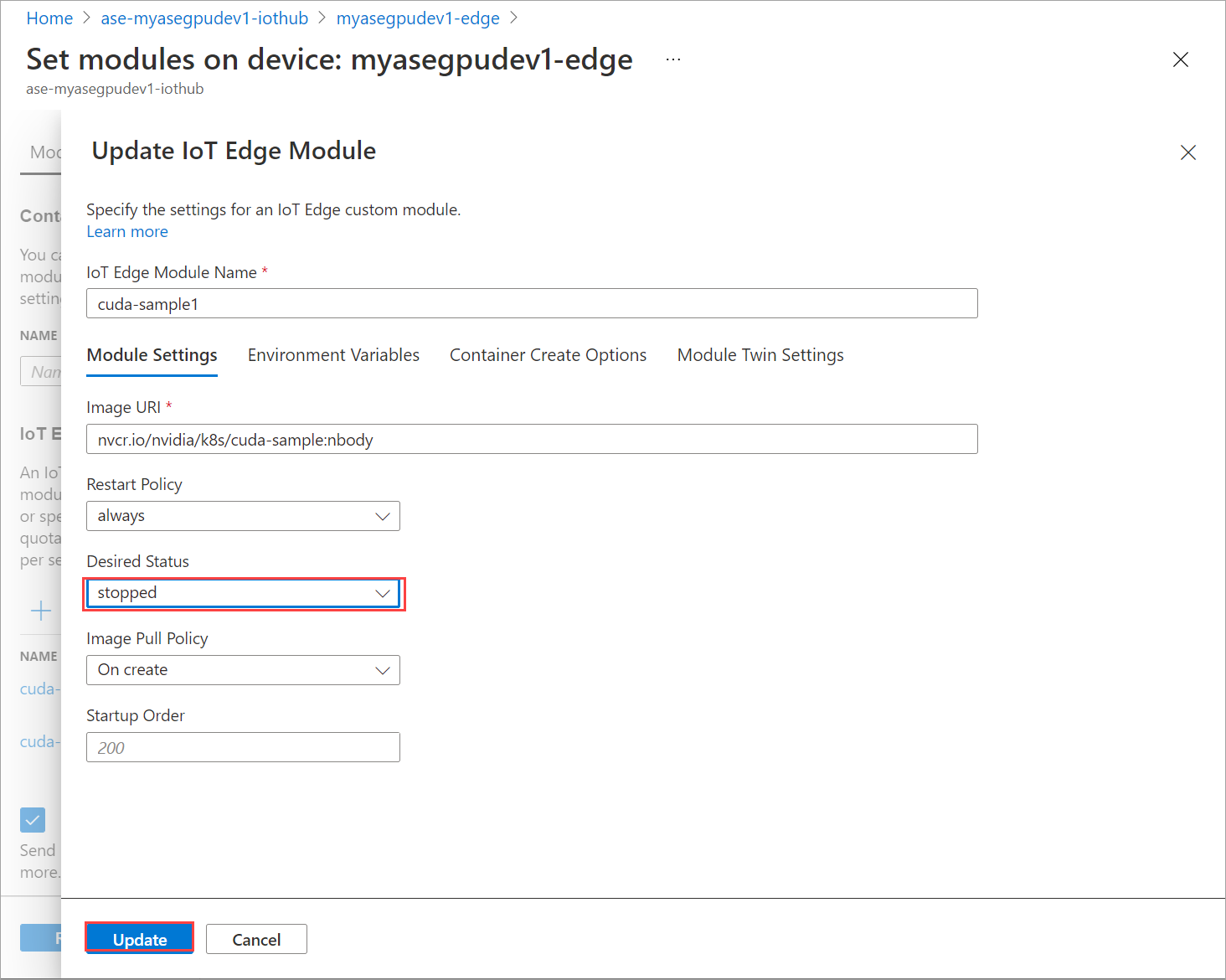
Upprepa stegen för att stoppa den andra modulen som distribueras på enheten. Välj Granska + skapa och välj sedan Skapa. Detta bör uppdatera distributionen.
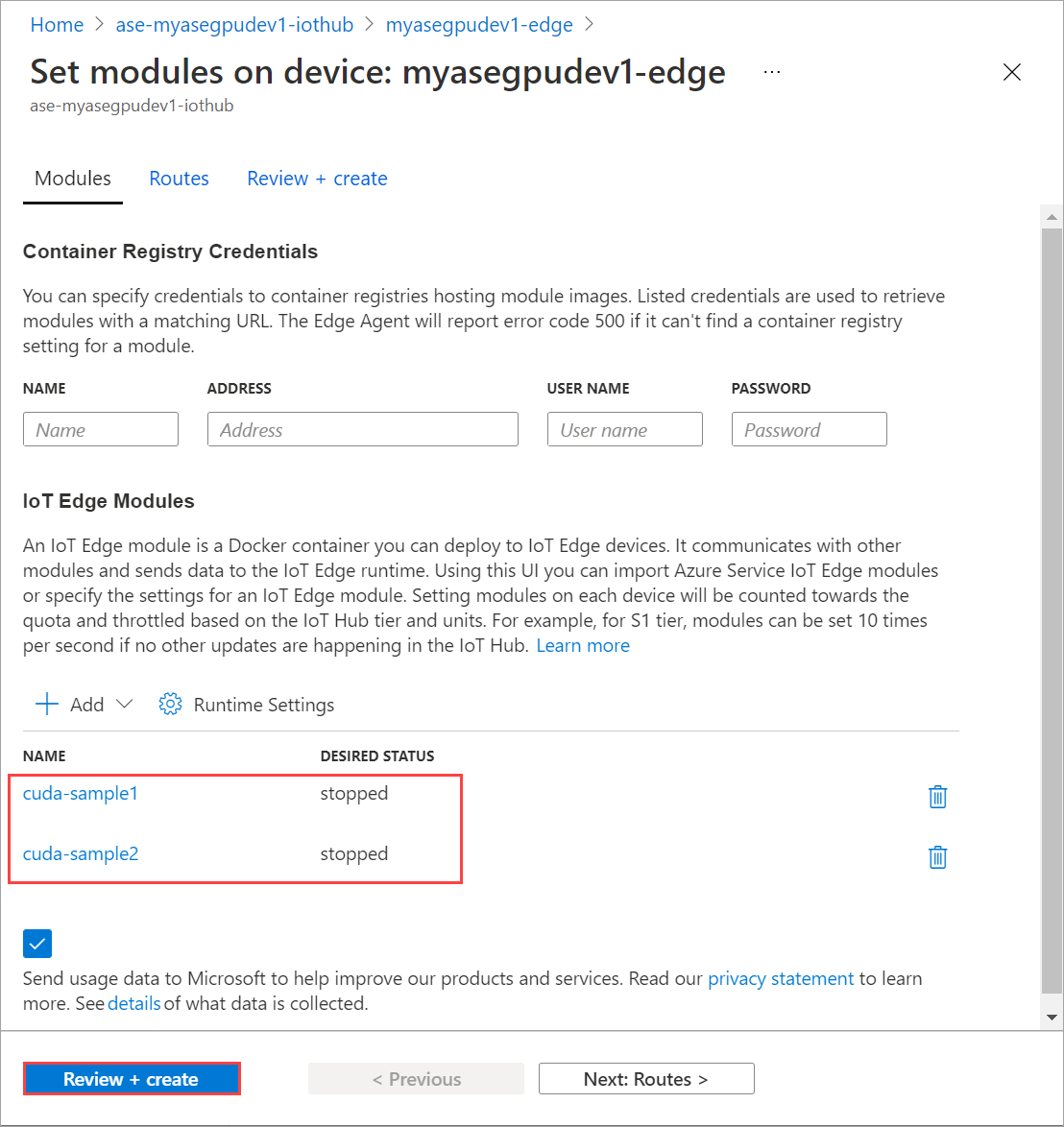
Sidan Uppdatera uppsättningsmoduler flera gånger. tills modulens körningsstatus visas som Stoppad.
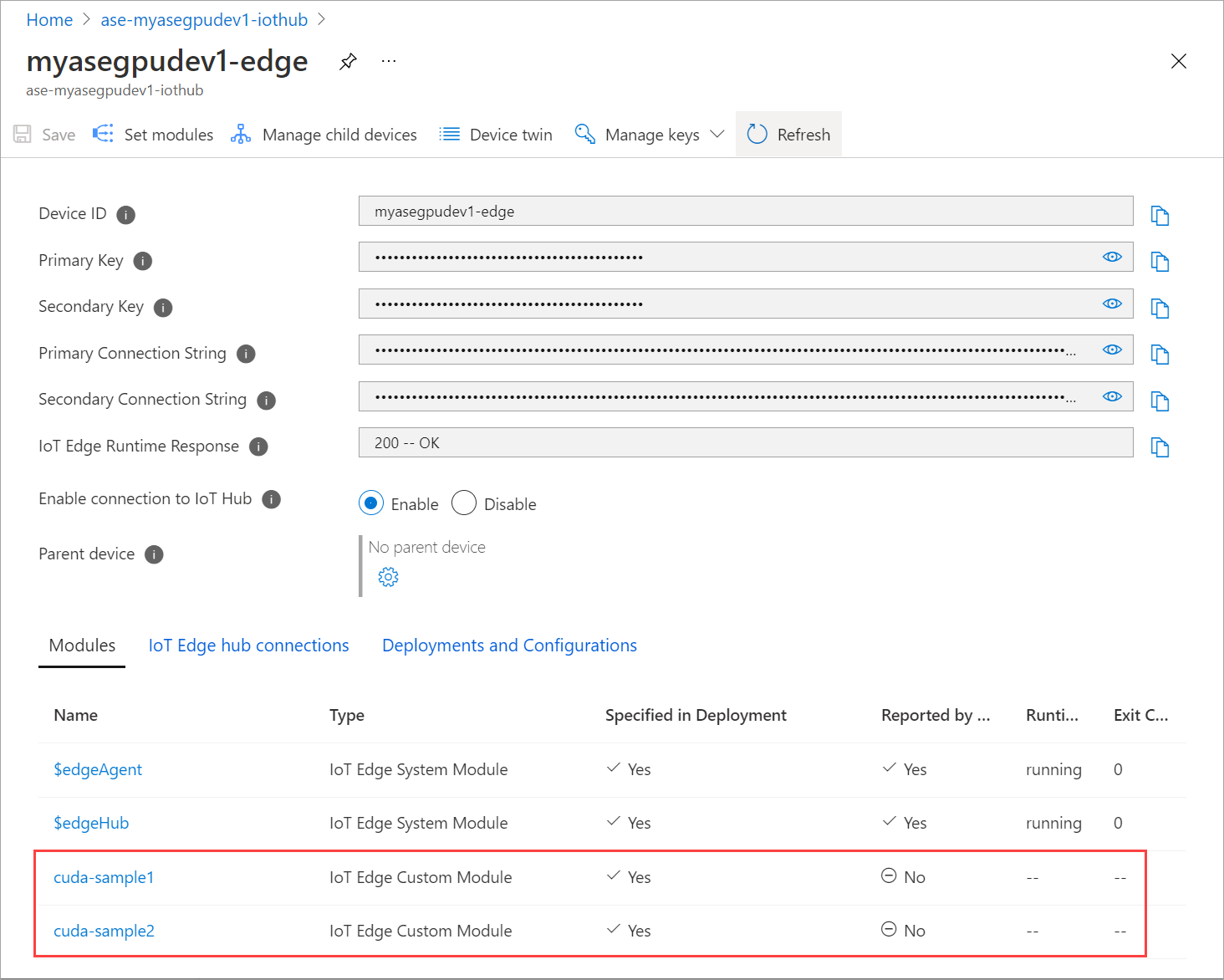
Distribuera med kontextdelning
Nu kan du distribuera n-body-simuleringen på två CUDA-containrar när MPS körs på enheten. Först aktiverar du MPS på enheten.
Om du vill aktivera MPS på enheten kör du
Start-HcsGpuMPSkommandot .[10.100.10.10]: PS>Start-HcsGpuMPS K8S-1HXQG13CL-1HXQG13: Set compute mode to EXCLUSIVE_PROCESS for GPU 0000191E:00:00.0. All done. Created nvidia-mps.service [10.100.10.10]: PS>Hämta Nvidia smi-utdata från Enhetens PowerShell-gränssnitt. Du kan se att
nvidia-cuda-mps-serverprocessen eller MPS-tjänsten körs på enheten.Här är ett exempel på utdata:
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Thu Mar 4 12:37:39 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 36C P8 9W / 70W | 28MiB / 15109MiB | 0% E. Process | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 122792 C nvidia-cuda-mps-server 25MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Get-HcsGpuNvidiaSmiDistribuera de moduler som du stoppade tidigare. Ange önskad status till att köras via Set-moduler.
Här är exempelutdata:
PS C:\WINDOWS\system32> kubectl get pods -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 NAME READY STATUS RESTARTS AGE cuda-sample1-869989578c-2zxh6 2/2 Running 0 44s cuda-sample2-6db6d98689-fn7mx 2/2 Running 0 44s edgeagent-79f988968b-7p2tv 2/2 Running 0 5d20h edgehub-d6c764847-l8v4m 2/2 Running 0 27m iotedged-55fdb7b5c6-l9zn8 1/1 Running 1 5d20h PS C:\WINDOWS\system32>Du kan se att modulerna distribueras och körs på enheten.
När modulerna distribueras börjar även n-body-simuleringen köras på båda containrarna. Här är exempelutdata när simuleringen har slutförts på den första containern:
PS C:\WINDOWS\system32> kubectl -n iotedge logs cuda-sample1-869989578c-2zxh6 cuda-sample1 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 155256.062 ms = 108.062 billion interactions per second = 2161.232 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Här är exempelutdata när simuleringen har slutförts på den andra containern:
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample2-6db6d98689-fn7mx cuda-sample2 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 155366.359 ms = 107.985 billion interactions per second = 2159.697 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Hämta Nvidia smi-utdata från PowerShell-gränssnittet på enheten när båda containrarna kör n-body-simuleringen. Här är ett exempel på utdata. Det finns tre processer,
nvidia-cuda-mps-serverprocessen (typ C) motsvarar MPS-tjänsten och processerna/tmp/nbody(typ M + C) motsvarar de n-body-arbetsbelastningar som distribueras av modulerna.[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Thu Mar 4 12:59:44 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 54C P0 69W / 70W | 242MiB / 15109MiB | 100% E. Process | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 56832 M+C /tmp/nbody 107MiB | | 0 N/A N/A 56900 M+C /tmp/nbody 107MiB | | 0 N/A N/A 122792 C nvidia-cuda-mps-server 25MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Get-HcsGpuNvidiaSmi