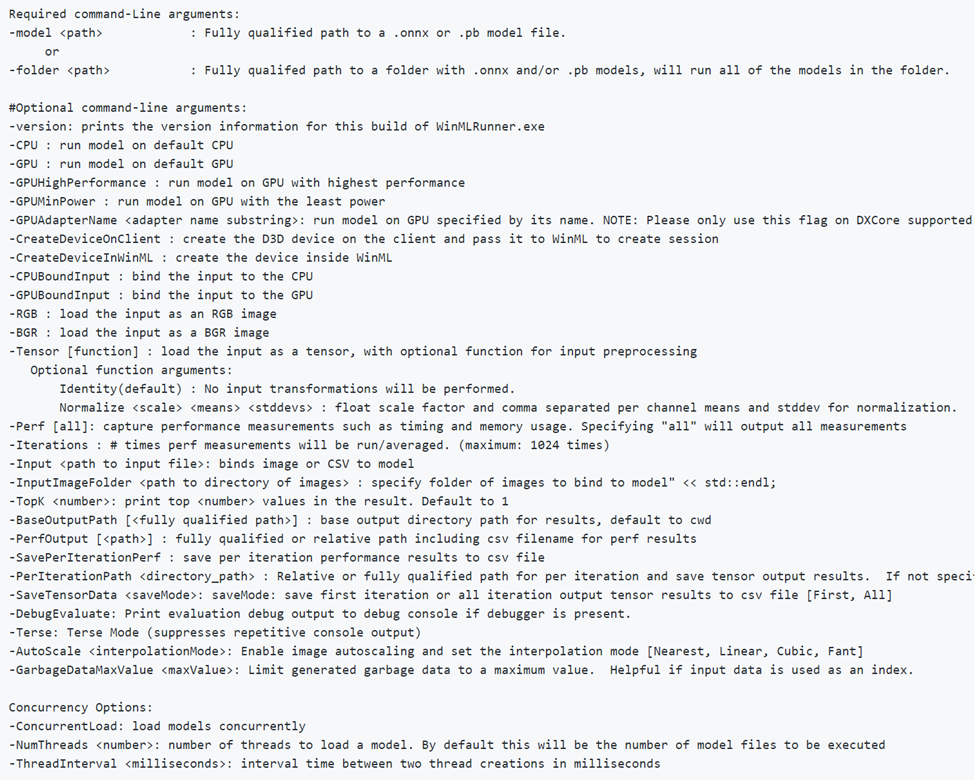
WinMLRunner
Средство WinMLRunner позволяет убедиться, что модель успешно выполняется при оценке через API-интерфейсы машинного обучения. Кроме того, вы можете получить сведения о времени выполнения и использовании памяти, времени ЦП и (или) GPU. Модели в форматах .onnx или .pb можно оценивать с тензорами или изображениями в качестве входных и выходных переменных. Есть два способа использовать WinMLRunner:
- Скачайте средство командной строки python.
- Откройте средство на информационной панели WinML. Дополнительные сведения см. в документации по информационной панели WinML.
Запуск модели
Для начала откройте скачанное средство Python. Перейдите в папку с файлом WinMLRunner.exe и выполните исполняемый файл, как описано ниже. Не забудьте заменить расположение установки реальными данными для вашей среды.
.\WinMLRunner.exe -model SqueezeNet.onnx
Кроме того, вы можете запустить сразу несколько моделей в одной папке с помощью следующей команды.
WinMLRunner.exe -folder c:\data -perf -iterations 3 -CPU`\
Выполнение хорошей модели
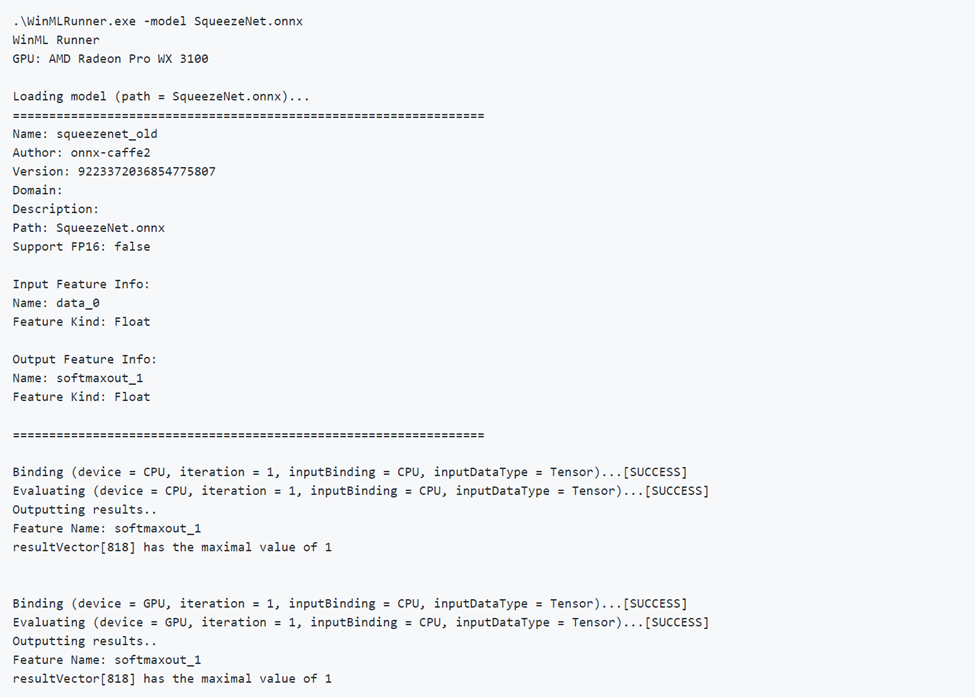
Ниже представлен пример успешного выполнения модели. Обратите внимание, как первая модель загружает и выводит метаданные модели. Затем эта модель выполняется отдельно в ЦП и GPU, выводя сообщения об успешной привязке и успешной оценке. И, наконец, выводятся выходные данные модели.
Выполнение плохой модели
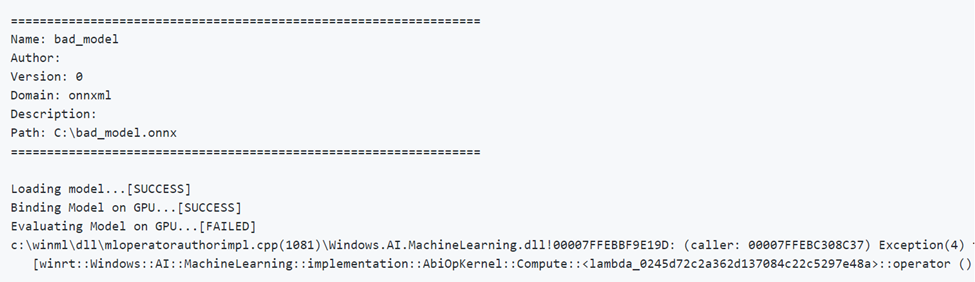
Ниже приведен пример выполнения модели с неверными параметрами. Обратите внимание на сообщение FAILED (Сбой) при оценке модели на GPU.
Оптимизация и выбор устройства
По умолчанию модель выполняется отдельно в ЦП и GPU, но с помощью флагов -CPU и -GPU вы можете указать конкретное устройство. В следующем примере модель выполняется три раза только в ЦП.
WinMLRunner.exe -model c:\data\concat.onnx -iterations 3 -CPU
Сохранение данных производительности
Укажите флаг -perf, чтобы собирать данные о производительности. В следующем примере выполняются все модели в указанной папке данных, по три раза отдельно в ЦП и GPU, а также собираются данные о производительности.
WinMLRunner.exe -folder c:\data iterations 3 -perf
Показатели производительности
Следующие показатели производительности выводятся в командную строку и в отдельный CSV-файл при каждой операции загрузки, привязки и оценки.
- Wall-clock time (ms) (Время по часам в мс) — прошедшее время с начала до завершения операции.
- GPU time (ms) (Время GPU в мс) — время, затраченное на передачу операции из ЦП в GPU и ее выполнение в GPU (примечание: операция Load() не передается на выполнение в GPU).
- CPU time (ms) (Время ЦП в мс) — время выполнения операции в ЦП.
- Dedicated and Shared Memory Usage (MB) (Использование общей и выделенной памяти в МБ) — средний объем использования памяти на уровне пользователя и ядра в процессе оценки модели в ЦП и GPU.
- Working Set Memory (MB) (Память рабочего набора в МБ) — объем памяти DRAM, который потребовался процессу в ЦП при выполнении оценки. Dedicated Memory (MB) (Выделенная память в МБ) — объем памяти, который использовался из VRAM выделенного GPU.
- Shared Memory (MB) (Общая память в МБ) — объем памяти, который использовался из DRAM графическим процессором (GPU).
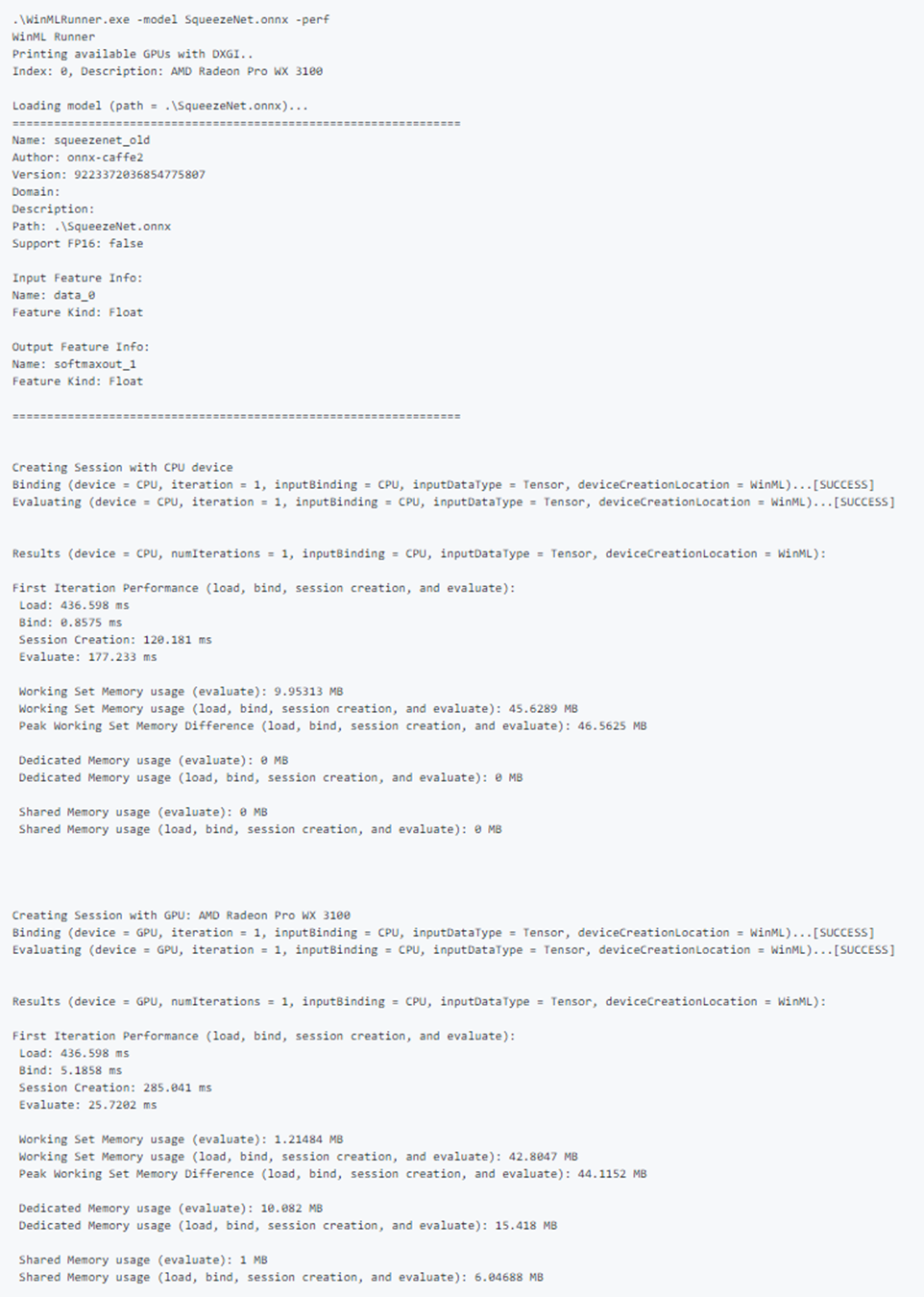
Пример сведений о производительности
Тестирование примеров входных данных
Отдельное выполнение модели в ЦП и GPU с отдельной привязкой входных данных к ЦП и GPU (всего 4 выполнения):
WinMLRunner.exe -model c:\data\SqueezeNet.onnx -CPU -GPU -CPUBoundInput -GPUBoundInput
Выполнение модели в ЦП с привязкой входных данных к GPU и загрузкой в формате RGB-изображения:
WinMLRunner.exe -model c:\data\SqueezeNet.onnx -CPU -GPUBoundInput -RGB
Сбор журналов трассировки
Если вы намерены собирать журналы трассировки, можно применить команды logman в сочетании с флагом debug:
logman start winml -ets -o winmllog.etl -nb 128 640 -bs 128logman update trace winml -p {BCAD6AEE-C08D-4F66-828C-4C43461A033D} 0xffffffffffffffff 0xff -ets WinMLRunner.exe -model C:\Repos\Windows-Machine-Learning\SharedContent\models\SqueezeNet.onnx -debuglogman stop winml -ets
Файл winmllog.etl появится в том же каталоге, где расположен WinMLRunner.exe.
Изучение журналов трассировки
С помощью traceprt.exe выполните приведенную ниже команду в командной строке.
tracerpt.exe winmllog.etl -o logdump.csv -of CSV
Теперь откройте файл logdump.csv.
Кроме того, вы можете использовать средство Windows Performance Analyzer, входящее в состав Visual Studio. Запустите Windows Performance Analyzer и откройте winmllog.etl.
Обратите внимание, что флаги -CPU, -GPU, -GPUHighPerformance, -GPUMinPower -BGR, -RGB, -tensor, -CPUBoundInput, -GPUBoundInput не являются взаимоисключающими (то есть вы можете использовать их в любых сочетаниях для выполнения модели с разными конфигурациями).
Динамическая загрузка DLL
Если вы намерены выполнить WinMLRunner с другой версией WinML (например, для сравнения производительности со старой версией или для тестирования), просто поместите файлы windows.ai.machinelearning.dll и directml.dll в ту же папку, где находится WinMLRunner.exe. WinMLRunner сначала будет искать файлы DLL именно здесь, а если не найдет, перейдет к папке C:/Windows/System32.
Известные проблемы
- Входные данные в форматах последовательности или карты пока не поддерживаются (такая модель просто пропускается, чтобы не блокировать выполнение других моделей в папке).
- Не удается реализовать надежное выполнение нескольких моделей с аргументом -folder и реальными данными. Так как можно указать только один вход, размер входа не будет совпадать с большинством моделей. Сейчас аргумент -folder нормально работает только со случайно сгенерированными данными.
- Генерация случайных данных в форматах Grey и YUV пока не поддерживается. В идеале конвейер генерации случайных данных в WinMLRunner должен поддерживать все типы входных данных, которые можно передавать в WinML.