Подготовка данных
Примечание.
Для повышения функциональности PyTorch также можно использовать с DirectML в Windows.
В предыдущей части этого руководства описано, как установить PyTorch на локальном компьютере. Теперь с помощью этой библиотеки мы настроим в коде доступ к данным, которые будут использоваться для создания модели.
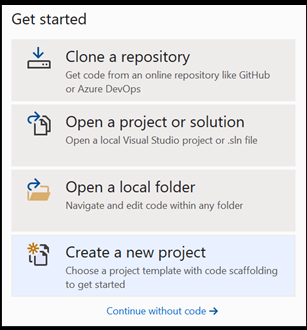
Откройте новый проект в Visual Studio.
- Откройте Visual Studio и выберите
create a new project.
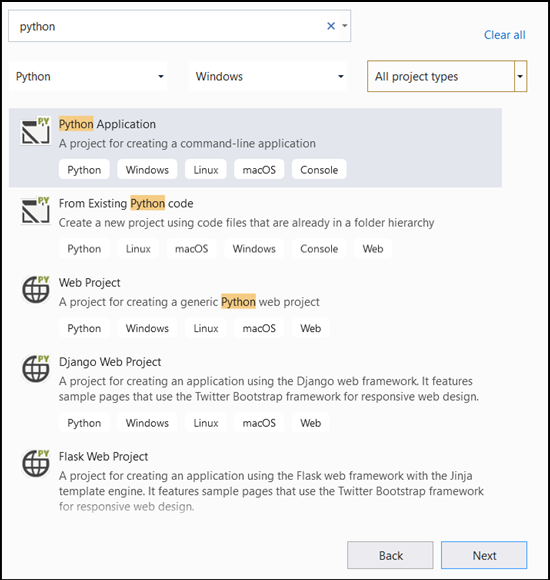
- На панели поиска введите
Pythonи выберитеPython Applicationкак шаблон проекта.
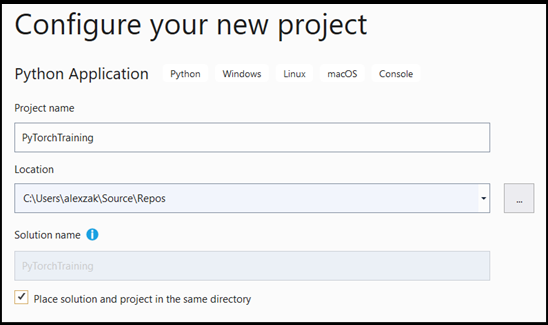
- В окне настроек сделайте следующее:
- Присвойте проекту имя. В нашем примере это PyTorchTraining.
- Выберите расположение проекта.
- Если вы используете VS 2019, установите флажок
Create directory for solution. - Если вы используете VS 2017, снимите флажок
Place solution and project in the same directory.
Щелкните create, чтобы создать проект.
Создание интерпретатора Python
Теперь вам нужно определить новый интерпретатор Python. Он должен включать недавно установленный пакет PyTorch.
- Перейдите в раздел для выбора интерпретатора и выберите
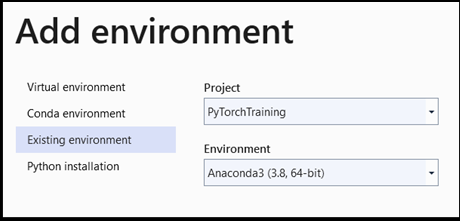
Add environment:
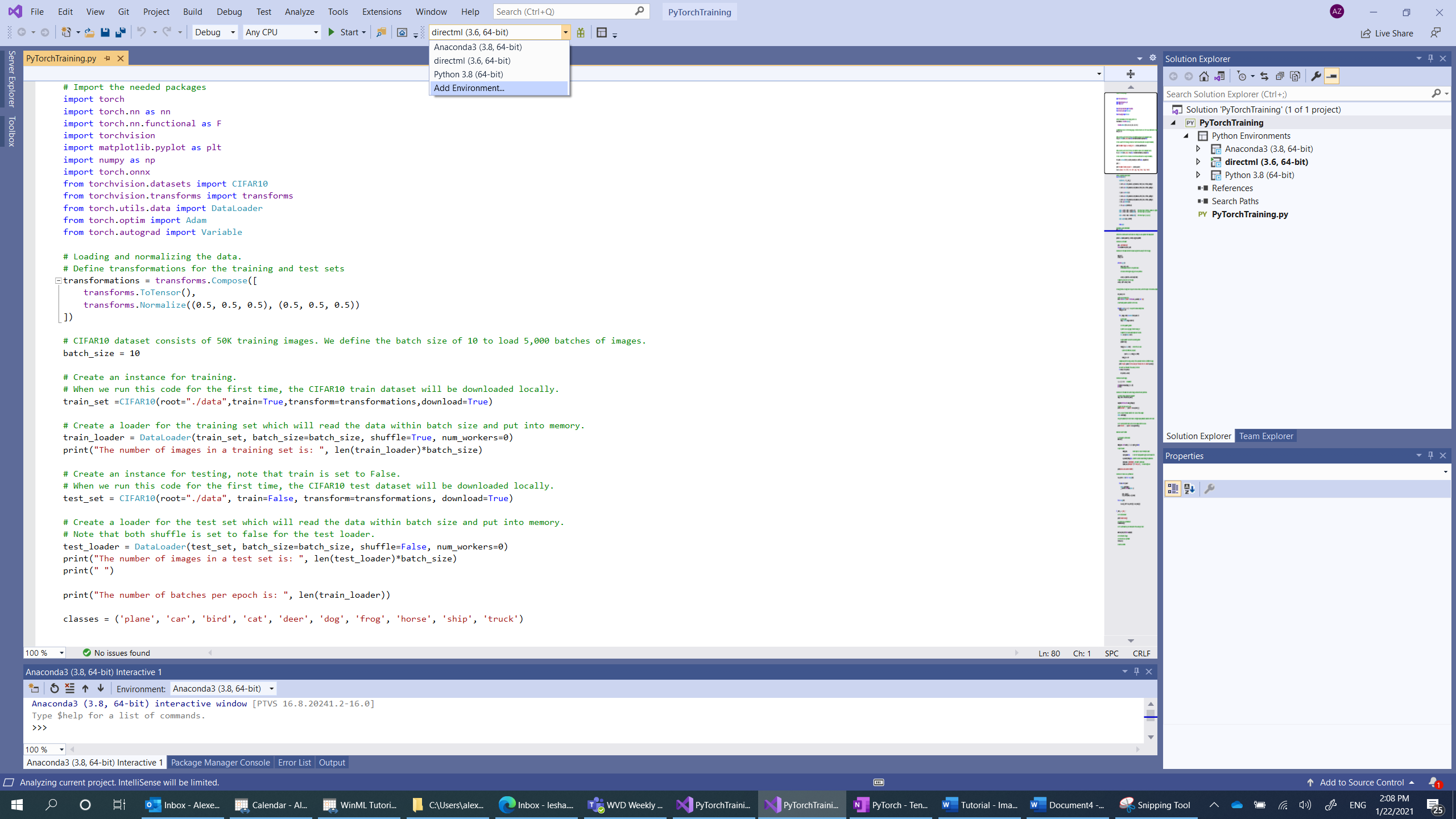
- В окне
Add environmentвыберитеExisting environment, а затемAnaconda3 (3.6, 64-bit). Это действие включает пакет PyTorch.
Чтобы протестировать работу интерпретатора Python и пакета PyTorch, введите в файл PyTorchTraining.py следующий код:
from __future__ import print_function
import torch
x=torch.rand(2, 3)
print(x)
В ответ вы должны получить тензор 5×3 со случайными значениями следующего вида.
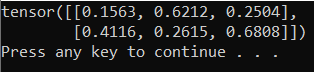
Примечание.
Хотите узнать больше? Посетите официальный веб-сайт PyTorch.
Загрузка набора данных
Для загрузки данных вы будете использовать класс PyTorch torchvision.
Библиотека Torchvision содержит несколько популярных наборов данных, например Imagenet, CIFAR10, MNIST и многие другие, а также архитектуры моделей и распространенные преобразования изображений для компьютерного зрения. Это упрощает загрузку данных в PyTorch.
CIFAR10
Здесь мы применим набор данных CIFAR10 для создания и обучения модели классификации. Набор данных CIFAR10 очень широко используется в сфере исследований машинного обучения. Он содержит 50 000 изображений для обучения и еще 10 000 изображений для тестирования. Каждое из них имеет размер 3×32×32 (трехканальный цвет, 32 пикселя в высоту и 32 пикселя в ширину).
Эти изображения разделены на 10 классов: airplane (0), automobile (1), bird (2), cat (3), deer (4), dog (5), frog (6), horse (7), ship (8), truck (9).
Для загрузки и чтения набора данных CIFAR10 в PyTorch нужно выполнить три шага:
- Определите преобразования, которые будут применяться к изображению. Для обучения модели вам нужно преобразовать изображения в тензоры или привести к нормализованному диапазону [-1,1].
- Создайте экземпляр доступного набора данных и загрузите его. Чтобы загрузить данные, используется абстрактный класс
torch.utils.data.Datasetдля представления набора данных. Этот набор данных будет скачан на локальный компьютер только при первом выполнении кода. - Доступ к данным с использованием DataLoader. Чтобы получить доступ к данным и поместить их в память компьютера, используется класс
torch.utils.data.DataLoader. DataLoader в PyTorch упаковывает набор данных и предоставляет доступ к базовым данным. Эта оболочка будет содержать пакеты изображений заданного размера.
Эти три шага нужно выполнить с наборами для обучения и тестирования.
- Откройте
PyTorchTraining.py fileв Visual Studio и добавьте следующий код. Он выполняет три описанных выше шага с наборами для обучения и тестирования из набора данных CIFAR10.
from torchvision.datasets import CIFAR10
from torchvision.transforms import transforms
from torch.utils.data import DataLoader
# Loading and normalizing the data.
# Define transformations for the training and test sets
transformations = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# CIFAR10 dataset consists of 50K training images. We define the batch size of 10 to load 5,000 batches of images.
batch_size = 10
number_of_labels = 10
# Create an instance for training.
# When we run this code for the first time, the CIFAR10 train dataset will be downloaded locally.
train_set =CIFAR10(root="./data",train=True,transform=transformations,download=True)
# Create a loader for the training set which will read the data within batch size and put into memory.
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=0)
print("The number of images in a training set is: ", len(train_loader)*batch_size)
# Create an instance for testing, note that train is set to False.
# When we run this code for the first time, the CIFAR10 test dataset will be downloaded locally.
test_set = CIFAR10(root="./data", train=False, transform=transformations, download=True)
# Create a loader for the test set which will read the data within batch size and put into memory.
# Note that each shuffle is set to false for the test loader.
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False, num_workers=0)
print("The number of images in a test set is: ", len(test_loader)*batch_size)
print("The number of batches per epoch is: ", len(train_loader))
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
При первом выполнении кода набор данных CIFAR10 будет скачан на устройство.

Next Steps
Когда данные будут готовы, переходите к обучению модели PyTorch.