Подготовка данных для анализа
В предыдущей части этого руководства описано, как установить PyTorch на локальном компьютере. Теперь с помощью этой библиотеки мы настроим в коде доступ к данным, которые будут использоваться для создания модели.
Откройте новый проект в Visual Studio.
- Откройте Visual Studio и выберите
create a new project.
- На панели поиска введите
Pythonи выберитеPython Applicationкак шаблон проекта.
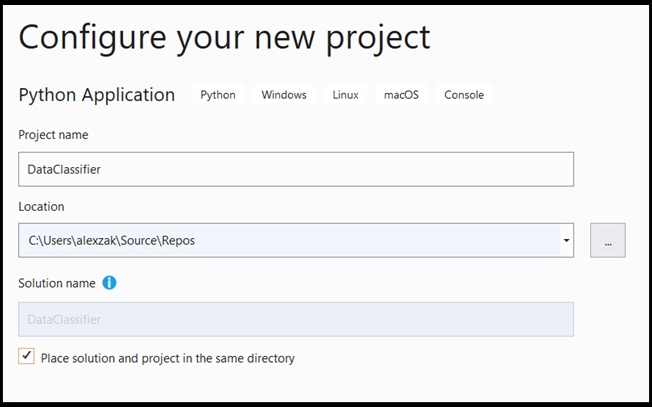
- В окне настроек сделайте следующее:
- Присвойте проекту имя. В нашем примере это DataClassifier.
- Выберите расположение проекта.
- Если вы используете VS 2019, установите флажок
Create directory for solution. - Если вы используете VS2017, снимите флажок
Place solution and project in the same directory.
Щелкните create, чтобы создать проект.
Создание интерпретатора Python
Теперь вам нужно определить новый интерпретатор Python. Он должен включать недавно установленный пакет PyTorch.
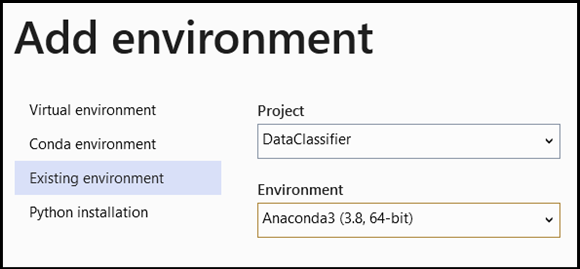
- Перейдите в раздел для выбора интерпретатора и выберите
Add Environment:

- В окне
Add EnvironmentвыберитеExisting environment, а затемAnaconda3 (3.6, 64-bit). Это действие включает пакет PyTorch.
Чтобы протестировать работу интерпретатора Python и пакета PyTorch, введите в файл DataClassifier.py следующий код:
from __future__ import print_function
import torch
x=torch.rand(2, 3)
print(x)
В ответ вы должны получить тензор 5×3 со случайными значениями следующего вида.
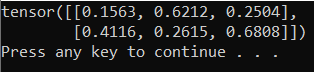
Примечание.
Хотите узнать больше? Посетите официальный веб-сайт PyTorch.
Основные сведения о данных
Мы обучим модель по набору данных "Ирисы Фишера". Этот известный набор данных включает 50 записей для каждого из трех видов Ириса: Ирис щетинистый, Ирис виргинский и Ирис разноцветный.
Были опубликованы несколько версий набора данных. Набор данных "Ирисы Фишера" можно найти в репозитории машинного обучения UCI, импортировать непосредственно из библиотеки Python Scikit-learn или использовать любую другую опубликованную ранее версию. Чтобы узнать больше о наборе данных "Ирисы Фишера", посетите соответствующую страницу на Википедии.
В этом учебнике, чтобы продемонстрировать, как обучить модель с помощью табличного типа входных данных, будет использоваться набор данных "Ирисы Фишера", экспортированный в файл Excel.
В каждой строке таблицы Excel будет четыре признака Ирисов: длина чашелистика в см, ширина чашелистика в см, длина лепестка в см и ширина лепестка в см. Они будут использоваться в качестве входных данных. Последний столбец содержит тип Ириса, связанный с этими параметрами, и будет представлять выходные данные регрессии. В итоге набор данных включает 150 единиц входных данных четырех признаков, каждая из которых соответствует соответствующему типу Ириса.
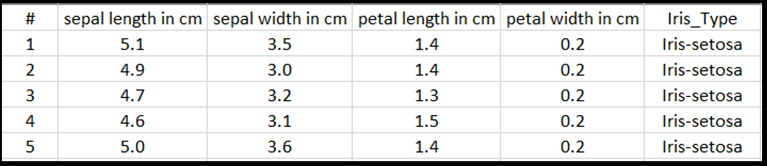
Регрессионный анализ рассматривает связь между входными переменными и результатом. На основе входных данных модель научится прогнозировать правильный тип выходных данных — один из трех типов Ирисов: Ирис щетинистый, Ирис разноцветный и Ирис виргинский.
Важно!
Если вы решили использовать другой набор данных для создания собственной модели, необходимо указать входные переменные модели и выходные данные в соответствии с вашим сценарием.
Загрузите набор данных.
Скачайте набор данных "Ирисы Фишера" в формате Excel. Его можно найти по этой ссылке.
В файле
DataClassifier.pyпапки Solution Explorer Files добавьте указанный ниже оператор импорта, чтобы получить доступ ко всем необходимым пакетам.
import torch
import pandas as pd
import torch.nn as nn
from torch.utils.data import random_split, DataLoader, TensorDataset
import torch.nn.functional as F
import numpy as np
import torch.optim as optim
from torch.optim import Adam
Как видите, для загрузки данных и управления ими вы будете использовать пакет Pandas (анализ данных Python), а также пакет torch.nn, который содержит модули и расширяемые классы для создания нейронных сетей.
- Загрузите данные в память и проверьте число классов. Мы рассчитываем увидеть 50 элементов каждого типа Ириса. Не забудьте указать расположение набора данных на компьютере.
Добавьте в файл DataClassifier.py указанный ниже код.
# Loading the Data
df = pd.read_excel(r'C:…\Iris_dataset.xlsx')
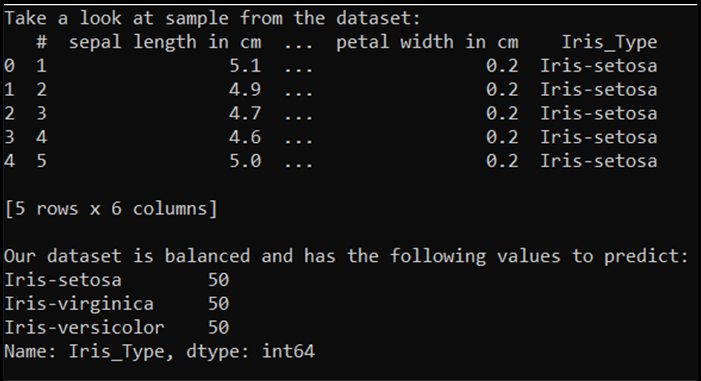
print('Take a look at sample from the dataset:')
print(df.head())
# Let's verify if our data is balanced and what types of species we have
print('\nOur dataset is balanced and has the following values to predict:')
print(df['Iris_Type'].value_counts())
При выполнении этого кода ожидаемые выходные данные выглядят следующим образом:
Чтобы иметь возможность использовать набор данных и обучать модель, необходимо определить входные и выходные данные. Входные данные включают 150 строк с признаками, а выходные — столбец с типом Ириса. Для нейронной сети, которую мы будем использовать, требуются числовые переменные, поэтому выходную переменную нужно преобразовать в числовой формат.
- Создайте в наборе данных столбец, где будут отображаться выходные данные в числовом формате, и определите входные и выходные данные регрессии.
Добавьте в файл DataClassifier.py указанный ниже код.
# Convert Iris species into numeric types: Iris-setosa=0, Iris-versicolor=1, Iris-virginica=2.
labels = {'Iris-setosa':0, 'Iris-versicolor':1, 'Iris-virginica':2}
df['IrisType_num'] = df['Iris_Type'] # Create a new column "IrisType_num"
df.IrisType_num = [labels[item] for item in df.IrisType_num] # Convert the values to numeric ones
# Define input and output datasets
input = df.iloc[:, 1:-2] # We drop the first column and the two last ones.
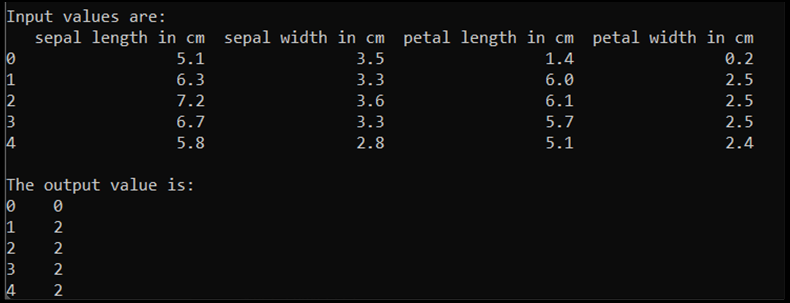
print('\nInput values are:')
print(input.head())
output = df.loc[:, 'IrisType_num'] # Output Y is the last column
print('\nThe output value is:')
print(output.head())
При выполнении этого кода ожидаемые выходные данные выглядят следующим образом:
Чтобы обучить модель, необходимо преобразовать входные и выходные данные модели в формат тензора:
- Чтобы преобразовать выходные данные в формат тензора, сделайте следующее:
Добавьте в файл DataClassifier.py указанный ниже код.
# Convert Input and Output data to Tensors and create a TensorDataset
input = torch.Tensor(input.to_numpy()) # Create tensor of type torch.float32
print('\nInput format: ', input.shape, input.dtype) # Input format: torch.Size([150, 4]) torch.float32
output = torch.tensor(output.to_numpy()) # Create tensor type torch.int64
print('Output format: ', output.shape, output.dtype) # Output format: torch.Size([150]) torch.int64
data = TensorDataset(input, output) # Create a torch.utils.data.TensorDataset object for further data manipulation
При выполнении кода ожидаемый формат входных и выходных данных будет следующим:

Существует 150 входных значений. Примерно 60 % будет использоваться в качестве данных для обучения модели. 20 % будет использоваться для проверки, а 30 % — для тестирования.
В этом учебнике размер пакета для набора данных для обучения определяется как 10. В обучающем наборе есть 95 элементов. Это значит, что в среднем существует 9 полных пакетов для единичной (одна эпоха) итерации по обучающим наборам. Размер пакета проверки и набора тестов должен иметь значение 1.
- Разделите данные на наборы обучения, проверки и тестирования:
Добавьте в файл DataClassifier.py указанный ниже код.
# Split to Train, Validate and Test sets using random_split
train_batch_size = 10
number_rows = len(input) # The size of our dataset or the number of rows in excel table.
test_split = int(number_rows*0.3)
validate_split = int(number_rows*0.2)
train_split = number_rows - test_split - validate_split
train_set, validate_set, test_set = random_split(
data, [train_split, validate_split, test_split])
# Create Dataloader to read the data within batch sizes and put into memory.
train_loader = DataLoader(train_set, batch_size = train_batch_size, shuffle = True)
validate_loader = DataLoader(validate_set, batch_size = 1)
test_loader = DataLoader(test_set, batch_size = 1)
Дальнейшие действия
Когда данные будут готовы, переходите к обучению модели PyTorch.