Планирование емкости для служб домен Active Directory
В этой статье приведены рекомендации по планированию емкости для служб домен Active Directory (AD DS).
Цели планирования емкости
Планирование емкости не совпадает с устранением неполадок с производительностью. Цели планирования емкости:
- Правильно реализуйте и управляйте средой.
- Свести к минимуму время, затрачиваемое на устранение неполадок с производительностью.
В планировании емкости организация может иметь базовый целевой показатель 40 % использования процессора в пиковые периоды, чтобы удовлетворить требования к производительности клиента и дать достаточно времени для обновления оборудования в центре обработки данных. Между тем, они устанавливают пороговое значение оповещения мониторинга для проблем с производительностью на 90% в течение пяти минут.
При постоянном превышении порогового значения управления емкостью либо добавление более или более быстрых процессоров для увеличения емкости или масштабирования службы на нескольких серверах будет решением. Пороговые значения оповещений о производительности позволяют знать, когда необходимо немедленно принять меры, когда проблемы с производительностью негативно влияют на взаимодействие с клиентом. В отличие от этого, решение по устранению неполадок будет более обеспокоено решением для решения однократных событий.
Управление емкостью похоже на профилактические меры, которые вы бы принять, чтобы избежать аварии автомобиля, таких как оборонительный вождения, убедившись, что тормоза работают должным образом, и т. д. Устранение неполадок производительности больше похоже на то, что полиция, пожарная служба и экстренные медицинские работники реагируют на аварию.
За последние несколько лет руководство по планированию емкости для систем масштабирования значительно изменилось. Следующие изменения в системных архитектурах оспаривают фундаментальные предположения о проектировании и масштабировании службы:
- 64-разрядные серверные платформы
- Виртуализация
- Повышенное внимание к потреблению электроэнергии
- Хранилище SSD
- Облачные сценарии
Подход к планированию емкости также сдвигается с серверных упражнений планирования на службы. домен Active Directory Службы (AD DS), зрелая распределенная служба, которая многие продукты Майкрософт и сторонних производителей используются в качестве серверной части, теперь является одним из наиболее важных продуктов для обеспечения работы других приложений.
Важные сведения, которые следует учитывать перед началом планирования
Чтобы получить большую часть этой статьи, сделайте следующее:
- Убедитесь, что вы ознакомились с рекомендациями по настройке производительности для Windows Server 2012 R2.
- Понимать, что платформа Windows Server — это архитектура на основе x64. Кроме того, необходимо понимать, что рекомендации этой статьи по-прежнему применяются, даже если среда Active Directory установлена в Windows Server 2003 x86 (теперь за пределами жизненного цикла поддержки) и содержит дерево сведений о каталоге (DIT), которое меньше 1,5 ГБ и может легко храниться в памяти.
- Понять, что планирование емкости является непрерывным процессом, поэтому следует регулярно проверять, насколько хорошо вы создаете среду, соответствует вашим ожиданиям.
- Понять, что оптимизация происходит в течение нескольких жизненных циклов оборудования в результате изменения затрат на оборудование. Например, если память становится дешевле, стоимость на ядро уменьшается или цена различных вариантов хранения изменяется.
- Планирование пиковой нагрузки каждый день. Рекомендуется создавать планы на основе 30 минут или часовых интервалов. Интервалы, превышающие один час, могут скрываться, когда служба на самом деле достигает пиковой емкости, и интервалы менее 30 минут могут дать неточные сведения, которые делают временные увеличения более важными, чем они на самом деле.
- Планирование роста на протяжении жизненного цикла оборудования для предприятия. Это планирование может включать стратегии обновления или добавления оборудования в ошеломленном виде или полное обновление каждые три-пять лет. Для каждого плана роста требуется оценить, сколько нагрузки на Active Directory растет. Исторические данные помогут вам сделать более точную оценку.
- Планирование отказоустойчивости. После получения оценки N план для сценариев, включающих N - 1, N - 2 и N - x.
На основе плана роста добавьте дополнительные серверы в соответствии с организационными потребностями, чтобы гарантировать, что потеря одного или нескольких серверов не приводит к превышению максимальной пиковой нагрузки системы.
Также помните, что необходимо интегрировать планы роста и отказоустойчивости. Например, если вы знаете, что развертывание в настоящее время требует одного контроллера домена (DC) для поддержки нагрузки, но ваша оценка говорит, что загрузка удвоится в следующем году и требует наличия двух контроллеров домена, то ваша система не имеет достаточной емкости для поддержки отказоустойчивости. Чтобы предотвратить эту нехватку емкости, следует вместо этого запланировать запуск с трех контроллеров домена. Если бюджет не разрешает три контроллера домена, вы также можете начать с двух контроллеров домена, а затем запланировать добавление третьего после трех или шести месяцев.
Примечание.
Добавление приложений с поддержкой Active Directory может существенно повлиять на нагрузку контроллера домена, независимо от того, поступает ли загрузка с серверов приложений или клиентов.
Цикл планирования емкости в трех частях
Прежде чем начать цикл планирования, необходимо решить, какой уровень обслуживания требуется вашей организации. Все рекомендации и рекомендации в этой статье предназначены для оптимальной среды производительности. Однако вы можете выборочно расслабить их в тех случаях, когда вам не нужна оптимизация. Например, если в вашей организации требуется более высокий уровень параллелизма и более согласованного взаимодействия с пользователем, следует ознакомиться с настройкой центра обработки данных. Центры обработки данных позволяют уделять больше внимания избыточности и минимизации узких мест в системе и инфраструктуре. В отличие от этого, если вы планируете развертывание для вспомогательного офиса только с несколькими пользователями, вам не нужно беспокоиться столько о оптимизации оборудования и инфраструктуры, что позволяет выбрать варианты с более низкими затратами.
Затем необходимо решить, следует ли использовать виртуальные или физические машины. С точки зрения планирования емкости нет правильного или неправильного ответа. Однако следует помнить, что каждый сценарий дает вам другой набор переменных для работы.
Сценарии виртуализации предоставляют два варианта:
- Прямое сопоставление, где у вас есть только один гость на узел.
- Сценарии общего узла , где имеется несколько гостей на узел.
Сценарии прямого сопоставления идентичны физическим узлам. При выборе сценария общего узла он вводит другие переменные, которые следует учитывать в последующих разделах. Общие узлы также конкурируют за ресурсы с домен Active Directory службами (AD DS), что может повлиять на производительность системы и взаимодействие с пользователем.
Теперь, когда мы ответили на эти вопросы, давайте рассмотрим сам цикл планирования емкости. Каждый цикл планирования емкости включает в себя трехэтапный процесс:
- Измеряйте существующую среду, определите, где в настоящее время находятся узкие места в системе, и получите основы среды, необходимые для планирования объема емкости, необходимой для развертывания.
- Определите, какое оборудование требуется на основе требований к емкости.
- Отслеживайте и проверяйте, работает ли настроенная инфраструктура в спецификациях. Данные, собранные на этом шаге, становятся базовыми для следующего цикла планирования емкости.
Применение процесса
Чтобы оптимизировать производительность, убедитесь, что следующие основные компоненты правильно выбраны и настроены на нагрузку приложения:
- Память
- Network
- Хранилище
- Процессор
- Netlogon
Базовые требования к хранилищу для AD DS и общее поведение совместимого клиентского программного обеспечения позволяют средам с 10 000 до 20 000 пользователей игнорировать планирование емкости физического оборудования, так как большинство современных систем класса серверов уже могут обрабатывать нагрузку этого размера. Однако таблицы в сводных таблицах сбора данных объясняют, как оценить существующую среду для выбора подходящего оборудования. В разделах после этого вы узнаете больше о базовых рекомендациях и принципах, относящихся к среде, для оборудования, чтобы помочь администраторам AD DS оценить свою инфраструктуру.
Другие сведения, которые следует учитывать при планировании:
- Любой размер на основе текущих данных является точным только для текущей среды.
- При оценке ожидается рост спроса на протяжении жизненного цикла оборудования.
- Поместите будущий рост, определив, следует ли переувыключать среду сегодня или постепенно добавлять емкость в течение жизненного цикла.
- Все принципы планирования емкости и методологии, применяемые к физическому развертыванию, также применяются к виртуализированному развертыванию. Однако при планировании виртуализированной среды необходимо помнить, чтобы добавить расходы на виртуализацию в любое планирование или оценки, связанные с доменом.
- Планирование емкости является прогнозом, а не совершенно правильным значением, поэтому не ожидайте, что он будет совершенно точным. Всегда помните, чтобы настроить емкость по мере необходимости и постоянно проверить, работает ли ваша среда в соответствии с потребностями.
Сводные таблицы сбора данных
В следующих таблицах перечислены критерии определения оценки оборудования.
Рабочая среда
| Компонент | Оценки |
|---|---|
| Размер хранилища и базы данных | 40 КБ до 60 КБ для каждого пользователя |
| ОЗУ | Размер базы данных Рекомендации по базовой операционной системе Приложения третьих лиц |
| Network | 1 ГБ |
| ЦП | 1000 одновременных пользователей для каждого ядра |
Высокоуровневые критерии оценки
| Компонент | Критерии оценки | Общие вопросы планирования |
|---|---|---|
| Размер хранилища и базы данных | Автономная дефрагментация | |
| Производительность хранилища и базы данных |
|
|
| ОЗУ |
|
|
| Network |
|
|
| ЦП |
|
|
| NetLogon |
|
|
Планирование
В течение длительного времени обычная рекомендация по размеру AD DS была помещена в столько ОЗУ, сколько размер базы данных. Теперь, когда среды AD DS и экосистема, которые потребляют их, выросли гораздо больше, все изменилось. Хотя увеличение вычислительной мощности и переход с архитектуры x86 на x64 сделало более тонкие аспекты изменения размера для производительности, не относящиеся к клиентам, работающим с AD DS на физических компьютерах, виртуализация сделала настройку гораздо более важной.
Чтобы устранить эти проблемы, в следующих разделах описано, как определить и спланировать требования Active Directory в качестве службы. Эти рекомендации можно применять к любой среде независимо от того, является ли ваша среда физической, виртуализированной или смешанной. Чтобы максимально повысить производительность, ваша цель должна быть максимально близкой к процессору среды AD DS.
ОЗУ
Чем больше хранилища можно кэшировать в ОЗУ, тем меньше необходимо перейти на диск. Чтобы максимально увеличить масштабируемость сервера, минимальный объем ОЗУ, который вы используете, должен соответствовать сумме текущего размера базы данных, общему размеру системного значения, рекомендуемой сумме для операционной системы и рекомендациям поставщика для агентов (антивирусные программы, мониторинг, резервное копирование и т. д.). Кроме того, вы должны включить дополнительные ОЗУ, чтобы обеспечить будущий рост на протяжении всего времени существования сервера. Эта оценка изменится на основе роста базы данных и изменения окружающей среды.
В средах, где максимизация ОЗУ не является экономичной или неэффективной, например в вспомогательных расположениях или когда дерево сведений о каталоге (DIT) слишком велик, перейдите к хранилищу , чтобы убедиться, что хранилище настроено правильно.
Еще одним важным фактором, который следует учитывать при изменении размера памяти, является размер файла страницы. При изменении размера диска, как и все остальное, связанное с памятью, цель заключается в минимизации использования дисков. В частности, сколько ОЗУ необходимо свести к минимуму разбиение по страницам? Следующие несколько разделов должны дать вам информацию, необходимую для ответа на этот вопрос. Другие рекомендации по размеру страницы, которые не обязательно влияют на производительность AD DS, являются рекомендациями по операционной системе и настройке системы для дампов памяти.
Определение объема ОЗУ контроллера домена (DC) может быть сложно из-за многих сложных факторов:
- Существующие системы не всегда являются надежными индикаторами требований к ОЗУ, так как служба подсистемы локального центра безопасности (LSSAS) обрезает ОЗУ в условиях давления памяти, искусственно отложенных требований.
- Отдельные контроллеры домена должны кэшировать данные своих клиентов. Это означает, что кэшированные данные в разных средах будут изменяться в зависимости от типов клиентов, содержащихся в нем. Например, контроллер домена в среде с Exchange Server собирает данные, отличные от контроллера домена, который выполняет проверку подлинности только пользователей.
- Объем усилий, необходимых для оценки ОЗУ для каждого контроллера домена на основе регистра, часто является чрезмерным и изменяется по мере изменения среды.
Критерии рекомендаций помогут вам принять более обоснованные решения:
- Чем больше кэшируете в ОЗУ, тем меньше необходимо перейти на диск.
- Хранилище — это самый медленный компонент компьютера. Доступ к данным на основе спинделя и носителей SSD меньше, чем доступ к данным в ОЗУ.
Рекомендации по виртуализации оЗУ
Ваша цель оптимизации ОЗУ — свести к минимуму время, затраченное на диск. Кроме того, следует избежать чрезмерной фиксации памяти на узле. В сценариях виртуализации перезафиксирование памяти происходит, когда система выделяет больше ОЗУ для гостей, чем то, что существует на самом физическом компьютере. Хотя превышение фиксации не является проблемой самостоятельно, когда общая память, используемая всеми гостями, превышает возможность ОЗУ узла, она приводит к тому, что узел будет страницу. Разбиение на страницы связывает диск производительности в тех случаях, когда контроллер домена переходит в NTDS.nit или файл страницы, чтобы получить данные или узел переходит на диск, чтобы попытаться получить доступ к данным ОЗУ. В результате этот процесс значительно снижает производительность и общую работу пользователей.
Пример сводки вычислений
| Компонент | Оценочная память (пример) |
|---|---|
| Рекомендуемая базовая операционная система ОЗУ (Windows Server 2008) | 2 ГБ |
| Внутренние задачи LSASS | 200 МБ |
| Агент мониторинга | 100 МБ |
| Антивирусная программа | 100 МБ |
| База данных (глобальный каталог) | 8,5 ГБ |
| Подушка для запуска резервного копирования, администраторы могут войти в систему без влияния | 1 ГБ |
| Итог | 12 ГБ |
Рекомендуется: 16 ГБ
С течением времени в базу данных добавляются дополнительные данные, а средняя продолжительность жизни сервера составляет около трех–пяти лет. На основе оценки роста на 333%, 16 ГБ является разумным объемом ОЗУ, который будет помещен на физический сервер.
Network
В этом разделе рассматривается оценка общего объема пропускной способности и емкости сети, необходимых для развертывания, включая запросы клиента, параметры групповой политики и т. д. Вы можете собирать данные для оценки с помощью Network Interface(*)\Bytes Received/sec счетчиков производительности и Network Interface(*)\Bytes Sent/sec счетчиков производительности. Выборка интервалов для счетчиков сетевых интерфейсов должна составлять 15, 30 или 60 минут. Что-нибудь меньше будет слишком неустойчивым для хороших измерений, и что-нибудь большее будет чрезмерно сглаживать ежедневные пики.
Примечание.
Как правило, большинство сетевого трафика на контроллере домена исходят, так как контроллер домена отвечает на клиентские запросы. В результате в этом разделе основное внимание уделяется исходящему трафику. Однако мы также рекомендуем оценить каждую из сред для входящего трафика. Рекомендации, приведенные в этой статье, можно также использовать для оценки требований к входящего сетевого трафика. Дополнительные сведения см. в разделе 929851: динамический диапазон портов по умолчанию для TCP/IP изменился в Windows Vista и в Windows Server 2008.
Требования к пропускной способности
Планирование масштабируемости сети охватывает две отдельные категории: объем трафика и нагрузку ЦП из сетевого трафика.
При планировании емкости для поддержки трафика необходимо учитывать две вещи. Во-первых, необходимо знать, сколько трафика репликации Active Directory проходит между контроллерами домена. Во-вторых, необходимо оценить внутренний трафик клиента к серверу. Внутренний трафик в основном получает небольшие запросы от клиентов относительно больших объемов данных, которые он отправляет обратно клиентам. 100 МБ обычно достаточно для сред с до 5000 пользователей на сервер. Для сред более 5000 пользователей рекомендуется использовать сетевой адаптер размером 1 ГБ и поддержку масштабирования на стороне получения (RSS).
Чтобы оценить пропускную способность внутрисайтового трафика, особенно в сценариях консолидации сервера, необходимо просмотреть Network Interface(*)\Bytes/sec счетчик производительности на всех контроллерах домена на сайте, добавить их вместе, а затем разделить сумму на целевое число контроллеров домена. Простой способ вычисления этого числа — открыть представление надежности Windows и Монитор производительности и просмотреть представление области с накоплением. Убедитесь, что все счетчики масштабируются одинаково.
Рассмотрим пример более сложного способа проверки того, что это общее правило применяется к определенной среде. В этом примере мы делаем следующие предположения:
- Цель состоит в том, чтобы сократить объем ресурсов до максимально возможного количества серверов. В идеале один сервер несет нагрузку, а затем развертывает дополнительный сервер для избыточности (n + 1 сценарий).
- В этом сценарии текущий сетевой адаптер поддерживает только 100 МБ и находится в переключении среды.
- Максимальное использование целевой пропускной способности сети составляет 60 % в сценарии n (потеря контроллера домена).
- Каждый сервер имеет около 10 000 клиентов, подключенных к нему.
Теперь давайте рассмотрим, что диаграмма в Network Interface(*)\Bytes Sent/sec счетчике говорит об этом примере сценария:
- Рабочий день начинается нарастать около 5:30 утра и уйдет в 7:00 вечера.
- Пиковый загруженный период составляет от 8:00 до 8:15, с более чем 25 байтами, отправленными в секунду на самый загруженный контроллер домена.
Примечание.
Все данные производительности являются историческими, поэтому пиковая точка данных в 8:15 указывает нагрузку с 8:00 до 8:15.
- Есть пики до 4:00, с более чем 20 байтами, отправленными в секунду на самый загруженный контроллер домена, который может указывать на загрузку из разных часовых поясов или фоновых действий инфраструктуры, таких как резервные копии. Так как пик в 8:00 превышает это действие, это не актуально.
- На сайте есть пять контроллеров домена.
- Максимальная нагрузка составляет около 5,5 МБИТ/с на контроллер контроллера домена, что представляет собой 44% подключения 100 МБ. Используя эти данные, мы можем оценить, что общая пропускная способность, необходимая в диапазоне от 8:00 до 8:15: 28 Мбит/с.
Примечание.
Счетчики отправки и получения сетевого интерфейса находятся в байтах, но пропускная способность сети измеряется в битах. Таким образом, чтобы вычислить общую пропускную способность, необходимо сделать 100 МБ ÷ 8 = 12,5 МБ и 1 ГБ ÷ 8 = 128 МБ.
Теперь, когда мы рассмотрели данные, какие выводы мы можем извлечь из него?
- Текущая среда соответствует уровню отказоустойчивости n + 1 при целевом использовании на 60 %. Использование одной системы в автономном режиме приведет к перемещению пропускной способности на сервер примерно с 5,5 МБИТ/с (44%) на около 7 МБИТ/с (56%).
- Исходя из ранее указанной цели консолидации на один сервер, это изменение превышает максимальное целевое использование и возможное использование подключения в 100 МБ.
- При подключении к 1 ГБ это значение составляет 22% от общей емкости.
- В обычном режиме работы в сценарии n + 1 нагрузка клиента относительно равномерно распределяется примерно на 14 МБИТ/с на сервер или 11% от общей емкости.
- Чтобы убедиться, что у вас достаточно емкости, пока контроллер домена недоступен, обычные операционные целевые объекты на сервере будут составлять около 30 % сетевого использования или 38 МБИТ/с на сервер. Целевые показатели отработки отказа будут составлять 60% от сетевого использования или 72 МБИТ/с на сервер.
Окончательное развертывание системы должно иметь сетевой адаптер размером 1 ГБ и подключение к сетевой инфраструктуре, которая будет поддерживать такую нагрузку. Из-за объема сетевого трафика загрузка ЦП из сетевых коммуникаций может ограничить максимальную масштабируемость AD DS. Этот же процесс можно использовать для оценки входящего взаимодействия с контроллером домена. Однако в большинстве случаев вам не нужно вычислять входящий трафик, так как он меньше исходящего трафика.
Важно убедиться, что оборудование поддерживает RSS в средах с более чем 5000 пользователями на сервер. Для сценариев высокого сетевого трафика балансировка нагрузки прерываний может быть узким местом. Вы можете обнаружить потенциальные узкие места, проверив Processor(*)\% Interrupt Time счетчик, чтобы узнать, распределяется ли время прерывания неравномерно между ЦП. Контроллеры сетевых интерфейсов с поддержкой RSS могут снизить эти ограничения и повысить масштабируемость.
Примечание.
Вы можете использовать аналогичный подход, чтобы оценить, требуется ли больше емкости при консолидации центров обработки данных или удалении контроллера домена в вспомогательном расположении. Чтобы оценить необходимую емкость, просто просмотрите данные для исходящего и входящего трафика клиентам. Результатом является объем трафика od, присутствующих в каналах широкой сети (глобальной сети).
В некоторых случаях может возникнуть больше трафика, чем ожидалось, так как трафик медленнее, например если проверка сертификатов не соответствует агрессивным тайм-аутам в глобальной сети. По этой причине размер и использование глобальной сети должно быть итеративным, текущим процессом.
Рекомендации по виртуализации для пропускной способности сети
Типичные рекомендации для физического сервера — 1 ГБ для серверов, поддерживающих более 5000 пользователей. После того как несколько гостей начнут совместно использовать базовую инфраструктуру виртуального коммутатора, следует обратить особое внимание на то, имеет ли узел достаточную пропускную способность сети для поддержки всех гостей в системе. Необходимо учитывать пропускную способность независимо от того, включает ли сеть контроллер домена, работающий в качестве виртуальной машины на узле с сетевым трафиком, проходящим по виртуальному коммутатору или напрямую подключен к физическому коммутатору. Виртуальные коммутаторы — это компоненты, в которых связь вверх должна поддерживать объем данных, передаваемых подключением, что означает, что сетевой адаптер физического узла, связанный с коммутатором, должен иметь возможность поддерживать нагрузку контроллера домена и всех других гостей, которые совместно используют виртуальный коммутатор, подключенный к физическому сетевому адаптеру.
Пример сводки по вычислению сети
В следующей таблице содержатся значения из примера сценария, который можно использовать для вычисления емкости сети:
| Системные | Пиковая пропускная способность |
|---|---|
| DC 1 | 6,5 МБИТ/с |
| DC 2 | 6,25 мб/с |
| DC 3 | 6,25 мб/с |
| DC 4 | 5,75 мб/с |
| DC 5 | 4.75 MBps |
| Итог | 28,5 мб/с |
На основе этой таблицы рекомендуемая пропускная способность составляет 72 МБИТ/с (28,5 МБИТ/с ÷ 40%).
| Число целевых систем | Общая пропускная способность (из выше) |
|---|---|
| 2 | 28,5 мб/с |
| Результат нормального поведения | 28.5 ÷ 2 = 14,25 мб/с |
Как всегда, следует предположить, что загрузка клиента будет увеличиваться со временем, поэтому следует планировать этот рост как можно раньше. Рекомендуется планировать по крайней мере 50% предполагаемый рост сетевого трафика.
Хранилище
При планировании емкости для хранилища следует учитывать два способа.
- Размер емкости или хранилища
- Производительность
Хотя емкость важна, важно не игнорировать производительность. С текущими затратами на оборудование большинство сред недостаточно большими, чтобы любой фактор был серьезной проблемой. Таким образом, обычная рекомендация заключается в том, чтобы просто поместить столько ОЗУ, сколько размер базы данных. Однако эта рекомендация может быть чрезмерной для спутниковых расположений в более крупных средах.
Определение параметров
Оценка хранилища
По сравнению с тем, когда Active Directory впервые прибыл в то время, когда 4 ГБ и 9 ГБ дисков были самыми распространенными размерами дисков, теперь размер для Active Directory даже не учитывается для всех, кроме крупнейших сред. С наименьшими доступными размерами жестких дисков в диапазоне 180 ГБ вся операционная система, SYSVOL и NTDS.dit можно легко разместить на одном диске. В результате мы рекомендуем избегать инвестиций слишком сильно в этой области.
Наша единственная рекомендация заключается в том, что вы гарантируете, что размер NTS.dit доступен на 110 % от размера NTS.dit, чтобы можно было дефрагментации хранилища. Помимо этого, следует учитывать обычные соображения в том, чтобы обеспечить дальнейшее развитие.
Если вы собираетесь оценить хранилище, сначала необходимо оценить размер NTDS.dit и SYSVOL. Эти измерения помогут вам размер фиксированного диска и выделения ОЗУ. Так как компоненты относительно низкие затраты, вам не нужно быть супер точным при выполнении математики. Дополнительные сведения об оценке хранилища см. в разделе "Ограничения хранилища" и "Оценки роста" для пользователей Active Directory и организационных подразделений.
Примечание.
Статьи, связанные с предыдущим абзацем, основаны на оценках размера данных, сделанных во время выпуска Active Directory в Windows 2000. При создании собственной оценки используйте размеры объектов, которые отражают фактический размер объектов в вашей среде.
При просмотре существующих сред с несколькими доменами можно заметить варианты размеров базы данных. При обнаружении этих вариантов используйте наименьший глобальный каталог (GC) и размеры, отличные от GC.
Размеры баз данных могут отличаться от версий ОС. DCs под управлением более ранних версий ОС, таких как Windows Server 2003, имеют меньший размер базы данных, чем в более поздней версии, например Windows Server 2008 R2. Контроллер домена с такими функциями, как rEcycle Bin или Credential Roaming, также может повлиять на размер базы данных.
Примечание.
- Для новых сред помните, что 100 000 пользователей в одном домене используют около 450 МБ пространства. Заполненные атрибуты могут оказать огромное влияние на общее количество потребляемого пространства. Атрибуты заполняются многими объектами как сторонних продуктов, так и продуктов Майкрософт, включая Microsoft Exchange Server и Lync. В результате мы рекомендуем оценить его на основе портфеля продуктов среды. Тем не менее, следует также помнить, что выполнение математических и тестовых вычислений для точных оценок для всех, но крупнейших сред может не стоило значительного времени или усилий.
- Убедитесь, что доступно свободное место составляет 110 % от размера NTDS.dit, чтобы включить автономную дефрагментацию. Это свободное пространство также позволяет планировать рост на протяжении трех-пятилетнего срока существования оборудования сервера. Если у вас есть хранилище для него, выделение достаточно свободного места на 300 % от DIT для хранилища является безопасным способом размещения роста и дефрикации.
Рекомендации по виртуализации хранилища
В сценариях, когда вы выделяете несколько файлов виртуального жесткого диска (VHD) в одном томе, следует использовать фиксированный диск состояния не менее 210 % размера DIT (100 % свободного пространства DIT + 110 % свободного пространства), чтобы обеспечить достаточно места, зарезервированного для ваших потребностей.
Пример сводки вычислений хранилища
В следующей таблице перечислены значения, используемые для оценки требований к пространству для сценария гипотетического хранилища.
| Данные, собранные на этапе оценки | Размер |
|---|---|
| Размер NTDS.dit | 35 ГБ |
| Модификатор, позволяющий включить автономную дефрагментацию | 2,1 ГБ |
| Общее необходимое хранилище | 73,5 ГБ |
Примечание.
Оценка хранилища также должна включать объем хранилища, необходимого для SYSVOL, ОС, файла страницы, временных файлов, локальных кэшированных данных, таких как файлы установщика и приложения.
Хранение и производительность
Как самый медленный компонент на любом компьютере, хранилище может оказать наибольшее негативное влияние на взаимодействие с клиентом. Для сред достаточно большого размера, что рекомендации по размеру ОЗУ в этой статье недоступны, последствия планирования емкости для хранения могут быть разрушительными для производительности системы. Сложности и разновидности доступных технологий хранения повышают риск, так как типичная рекомендация поставить ОС, журналы и базу данных на отдельных физических дисках не применяется универсально во всех сценариях.
В старых рекомендациях по дискам предполагается, что диск был выделенным спинделем, который позволил изолированным ввода-выводам. Это предположение больше не верно из-за внедрения следующих типов хранилища:
- RAID
- Новые типы хранилища и сценарии виртуализированного и общего хранилища
- Общие спиндели в сети зоны хранения (SAN)
- VHD-файл в хранилище, подключенном к сети или san
- Твердотельные накопители (SSD)
- Многоуровневые архитектуры хранилища, такие как кэширование уровня хранилища SSD с большим объемом хранилища на основе спинdle
Общее хранилище, например RAID, SAN, NAS, JBOD, дисковые пространства и VHD, может быть перегружено другими рабочими нагрузками, которые вы размещаете в серверном хранилище. Эти типы хранилища также представляют дополнительную проблему: проблемы с SAN, сетью или драйвером между физическим диском и приложением AD могут вызвать регулирование и задержки. Чтобы уточнить, это не плохие конфигурации, но они являются более сложными, что означает, что необходимо обратить дополнительное внимание, чтобы убедиться, что каждый компонент работает должным образом. Более подробные объяснения см . в приложении C и приложении D далее в этой статье. Кроме того, в то время как диски SSD не ограничены жесткими дисками, которые могут обрабатывать только один ввод-вывод за раз, они по-прежнему имеют ограничения ввода-вывода, которые могут быть перегружены.
В итоге цель всего планирования производительности хранилища независимо от архитектуры хранилища заключается в том, чтобы обеспечить всегда доступное количество операций ввода-вывода и что они происходят в течение приемлемого периода времени. Сценарии с локально подключенным хранилищем см . в приложении C для получения дополнительных сведений о проектировании и планировании. Принципы в приложении можно применить к более сложным сценариям хранения, а также беседам с поставщиками, поддерживающими решения внутреннего хранилища.
Из-за того, сколько вариантов хранения доступны сегодня, мы рекомендуем обратиться к группам поддержки оборудования или поставщикам, планируя, чтобы решение соответствовало потребностям развертывания AD DS. Во время этих бесед можно найти следующие счетчики производительности, особенно если база данных слишком велика для ОЗУ:
LogicalDisk(*)\Avg Disk sec/Read(например, если NTDS.dit хранится на диске D, полный путь будет )LogicalDisk(D:)\Avg Disk sec/ReadLogicalDisk(*)\Avg Disk sec/WriteLogicalDisk(*)\Avg Disk sec/TransferLogicalDisk(*)\Reads/secLogicalDisk(*)\Writes/secLogicalDisk(*)\Transfers/sec
При предоставлении данных необходимо убедиться, что выборка выполняется в интервалах от 15, 30 или 60 минут, чтобы получить наиболее точное представление о текущей среде.
оценка результатов;
В этом разделе основное внимание уделяется считываниям из базы данных, так как база данных обычно является наиболее требовательным компонентом. Вы можете применить ту же логику для записи в файл журнала, подставив <NTDS Log>)\Avg Disk sec/Write и LogicalDisk(<NTDS Log>)\Writes/sec).
Счетчик LogicalDisk(<NTDS>)\Avg Disk sec/Read показывает, правильно ли размер текущего хранилища. Если значение примерно равно ожидаемому времени доступа к диску для типа диска, LogicalDisk(<NTDS>)\Reads/sec счетчик является допустимой мерой. Если результаты примерно равны времени доступа к диску для типа диска, LogicalDisk(<NTDS>)\Reads/sec счетчик является допустимой мерой. Хотя это может измениться в зависимости от того, какие спецификации изготовителя имеет внутреннее хранилище, но хорошие диапазоны для LogicalDisk(<NTDS>)\Avg Disk sec/Read примерно:
- 7200 rpm: 9 до 12,5 миллисекунда (мс)
- 10 000 rpm: 6 до 10 мс
- 15 000 rpm: 4–6 мс
- SSD — от 1 до 3 мс
Вы можете услышать от других источников, что производительность хранилища снижается на 15 мс до 20 мс. Разница между этими значениями и значениями в предыдущем списке заключается в том, что значения списка показывают обычный рабочий диапазон. Другие значения предназначены для устранения неполадок, которые помогают определить, когда взаимодействие с клиентом снизилось достаточно, чтобы он стал заметным. Дополнительные сведения см . в приложении C.
LogicalDisk(<NTDS>)\Reads/sec— это объем операций ввода-вывода, который в настоящее время выполняет система.- Если
LogicalDisk(<NTDS>)\Avg Disk sec/Readнаходится в оптимальном диапазоне для внутреннего хранилища, вы можете напрямую использоватьLogicalDisk(<NTDS>)\Reads/secдля размера хранилища. - Если
LogicalDisk(<NTDS>)\Avg Disk sec/Readв пределах оптимального диапазона для внутреннего хранилища требуется дополнительное число операций ввода-вывода в соответствии со следующей формулой:LogicalDisk(<NTDS>)\Avg Disk sec/Read÷ время доступа к диску физического носителя ×LogicalDisk(<NTDS>)\Avg Disk sec/Read
- Если
При выполнении этих вычислений ниже приведены некоторые аспекты, которые следует учитывать:
- Если сервер имеет подоптималный объем ОЗУ, полученные значения будут слишком высокими и не будут достаточно точными, чтобы быть полезными для планирования. Однако их можно использовать для прогнозирования худших сценариев.
- При добавлении или оптимизации ОЗУ также уменьшается объем операций ввода-вывода
LogicalDisk(<NTDS>)\Reads/Sec. Это снижение может привести к тому, что решение хранилища не будет столь надежным, как первоначальное вычисление, догадалось. К сожалению, мы не можем дать более конкретные сведения о том, что это означает, так как вычисления зависят от отдельных сред, особенно клиентской нагрузки. Однако рекомендуется настроить размер хранилища после оптимизации ОЗУ.
Рекомендации по виртуализации для производительности
Как и в предыдущих разделах, наша цель заключается в том, чтобы убедиться, что общая инфраструктура может поддерживать общую нагрузку всех потребителей. При планировании следующих сценариев необходимо учитывать эту цель:
- Физический компакт-диск совместно использует один и тот же носитель в инфраструктуре SAN, NAS или iSCSI, что и другие серверы или приложения.
- Пользователь, использующий сквозной доступ к инфраструктуре SAN, NAS или iSCSI, которая использует носитель.
- Пользователь, использующий VHD-файл на общем носителе локально или в локальной инфраструктуре SAN, NAS или iSCSI.
С точки зрения гостевого пользователя, необходимо пройти через узел для доступа к любой производительности хранилища, так как пользователь должен перемещаться по дополнительным путям кода для получения доступа. Тестирование производительности указывает, что виртуализация влияет на пропускную способность в зависимости от того, сколько процессор использует хост-система. Использование процессора также зависит от того, сколько ресурсов гостевого пользователя требует узла. Этот спрос способствует обработке рекомендаций по виртуализации, которые необходимо принять для обработки потребностей в виртуализированных сценариях. Дополнительные сведения см . в приложении A.
Дальнейшие проблемы заключается в том, сколько вариантов хранения доступны в настоящее время, каждый из которых влияет на производительность. К этим параметрам относятся сквозное хранилище, адаптеры SCSI и интегрированная среда разработки. При миграции с физической среды на виртуальную среду следует настроить различные параметры хранения для виртуализированных гостевых пользователей с помощью умножения 1.10. Однако при передаче между различными сценариями хранения не нужно учитывать корректировки, так как хранилище является локальным, SAN, NAS или iSCSI более важным.
Пример вычисления виртуализации
Определение количества операций ввода-вывода, необходимого для работоспособной системы в обычных условиях эксплуатации:
- ЛогическийDisk(
<NTDS Database Drive>) ÷ передачи в секунду в течение пикового периода 15 минут - Чтобы определить объем операций ввода-вывода, необходимого для хранения, в котором превышается емкость базового хранилища:
Необходимые операции ввода-вывода в секунду = (ЛогическийDisk(
<NTDS Database Drive>)) ÷ avg Disk Read/sec ÷ ) ×<Target Avg Disk Read/sec>ЛогическийDisk(<NTDS Database Drive>)\Read/sec
| Счетчик | Значение |
|---|---|
Фактический логическийdisk(<NTDS Database Drive>)\Avg Disk sec/Transfer |
.02 секунды (20 миллисекунд) |
Target LogicalDisk(<NTDS Database Drive>)\Avg Disk sec/Transfer |
.01 секунды |
| Умножение для изменения доступных операций ввода-вывода | 0.02 ÷ 0.01 = 2 |
| Value name | Значение |
|---|---|
LogicalDisk(<NTDS Database Drive>)\Transfer/sec |
400 |
| Умножение для изменения доступных операций ввода-вывода | 2 |
| Общее количество операций ввода-вывода в секунду, необходимое во время пикового периода | 800 |
Чтобы определить скорость, с которой следует прогреть кэш:
- Определите максимально допустимое время, которое можно потратить на потепление кэша. В типичных сценариях допустимое количество времени — сколько времени потребуется для загрузки всей базы данных с диска. В сценариях, когда ОЗУ не может загрузить всю базу данных, используйте время, необходимое для заполнения всей ОЗУ.
- Определите размер базы данных, за исключением пространства, которое вы не планируете использовать. Дополнительные сведения см. в разделе "Оценка для хранилища".
- Разделите размер базы данных на 8 КБ, чтобы получить общее количество операций ввода-вывода, необходимое для загрузки базы данных.
- Разделите общее число операций ввода-вывода по количеству секунд в определенном интервале времени.
Вычисляемое число является в основном точным, но может быть не точным, так как вы не настроили (расширяемый модуль хранилища) ESE с фиксированным размером кэша, то AD DS вытесняет ранее загруженные страницы, так как использует размер кэша переменной по умолчанию.
| Точки данных для сбора | Значения |
|---|---|
| Максимально допустимое время для теплого | 10 минут (600 секунд) |
| Размер базы данных | 2 ГБ |
| Шаг вычисления | Формула | Результат |
|---|---|---|
| Вычисление размера базы данных на страницах | (2 ГБ × 1024 × 1024) = размер базы данных в КБ | 2 097 152 КБ |
| Вычисление количества страниц в базе данных | 2 097 152 КБ ÷ 8 КБ = количество страниц | 262 144 страниц |
| Вычисление операций ввода-вывода в секунду, необходимое для полного нагрева кэша | 262 144 страницы ÷ 600 секунд = необходимые операции ввода-вывода в секунду | 437 операций ввода-вывода в секунду |
Обработка
Оценка использования процессора Active Directory
Для большинства сред управление емкостью обработки является компонентом, который заслуживает наибольшего внимания. При оценке объема ресурсов ЦП, необходимых для развертывания, следует учитывать следующие две вещи:
- Работают ли приложения в вашей среде как предназначенные в инфраструктуре общих служб на основе критериев, описанных в отслеживании дорогостоящих и неэффективных поисковых запросов? В более крупных средах плохо закодированные приложения могут сделать нагрузку ЦП нестабильной, занять неупорядоченное время ЦП за счет других приложений, повысить потребности в емкости и неравномерно распределять нагрузку на контроллеры домена.
- AD DS — это распределенная среда со многими потенциальными клиентами, потребности в обработке которых отличаются широко. Предполагаемые затраты для каждого клиента могут отличаться из-за шаблонов использования и количества приложений, использующих AD DS. Как и в сети, следует оценить как оценку общей необходимой емкости в среде, а не одновременно смотреть на каждого клиента.
Вы должны сделать эту оценку только после завершения оценки хранилища , так как вы не сможете сделать точное предположение без допустимых данных о нагрузке процессора. Кроме того, важно убедиться, что все узкие места не вызваны хранилищем перед устранением неполадок процессора. При удалении состояний ожидания процессора загрузка ЦП увеличивается, так как она больше не должна ждать данных. Таким образом, счетчики производительности, к которых следует обратить самое внимание, относятся Logical Disk(<NTDS Database Drive>)\Avg Disk sec/Read и Process(lsass)\ Processor Time. Logical Disk(<NTDS Database Drive>)\Avg Disk sec/Read Если счетчик превышает 10 или 15 миллисекунд, данные в Process(lsass)\ Processor Time ней искусственно низки и проблема связана с производительностью хранилища. Рекомендуется задать интервалы выборки 15, 30 или 60 минут для наиболее точных данных.
Обзор обработки
Для планирования планирования емкости для контроллеров домена вычислительные мощности требуют наибольшего внимания и понимания. При изменении размера систем для обеспечения максимальной производительности всегда существует компонент, который является узким местом, и в правильном размере контроллер домена этот компонент является процессором.
Аналогично разделу сети, в котором требуется проверка спроса на среду на основе сайта, то же самое необходимо сделать для вычислительной емкости. В отличие от раздела сети, где доступные сетевые технологии значительно превышают обычный спрос, обратите больше внимания на размер емкости ЦП. Как любая среда даже умеренного размера; все, что более нескольких тысяч одновременных пользователей может поставить значительную нагрузку на ЦП.
К сожалению, из-за огромной дисперсии клиентских приложений, использующих AD, общая оценка пользователей на ЦП неувно применима ко всем средам. В частности, требования к вычислениям зависят от поведения пользователей и профиля приложения. Таким образом, каждая среда должна быть по отдельности.
Профиль поведения целевого сайта
При планировании емкости для всего сайта ваша цель должна быть проектированием емкости N + 1. В этой структуре, даже если одна система завершается сбоем в течение пикового периода, служба по-прежнему может продолжаться на приемлемых уровнях качества. В сценарии N загрузка во всех полях должна быть меньше 80%-100% во время пиковых периодов.
Кроме того, приложения и клиенты сайта используют рекомендуемый метод функции DsGetDcName для поиска контроллеров домена, они уже должны равномерно распределяться только с незначительными временными пиками.
Теперь мы рассмотрим два примера сред, которые находятся в целевом и отключенном целевом объекте. Во-первых, мы рассмотрим пример среды, которая работает как предназначенная и не превышает целевой целевой объект планирования емкости.
В первом примере мы делаем следующие предположения:
- Каждый из пяти ЦП на сайте имеет четыре ЦП.
- Общее целевое использование ЦП в рабочее время составляет 40 % в обычных условиях эксплуатации (N + 1) и 60 % в противном случае (N). В нерабочие часы целевое использование ЦП составляет 80 %, так как мы ожидаем, что программное обеспечение резервного копирования и другие процессы обслуживания будут использовать все доступные ресурсы.
Теперь давайте рассмотрим диаграмму (Processor Information(_Total)\% Processor Utility) для каждого из контроллеров домена, как показано на следующем рисунке.
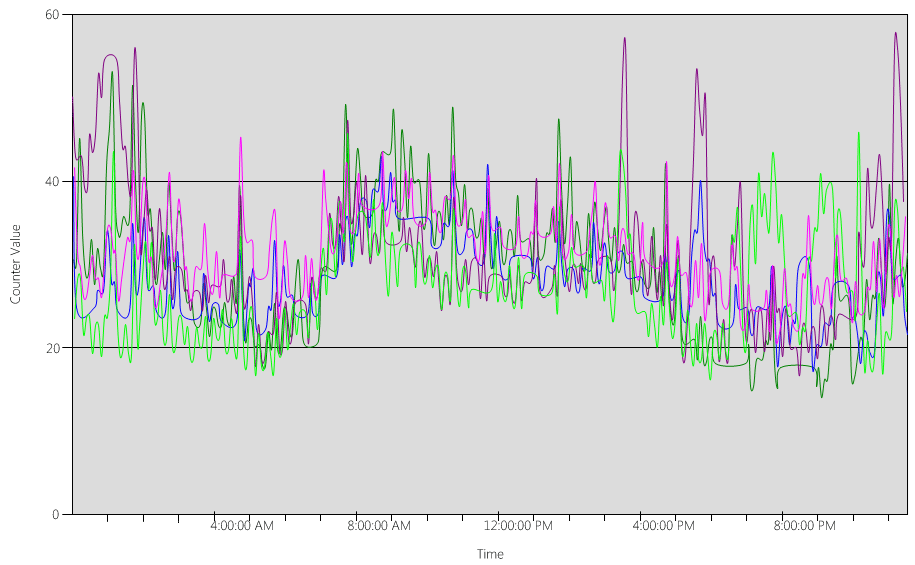
Нагрузка относительно равномерно распределяется. Это то, что мы ожидаем, когда клиенты используют указатель контроллера домена и хорошо написанные поисковые запросы.
В нескольких пятиминутных интервалах есть пики на 10%, иногда даже на 20%. Однако если эти пики не приводят к превышению целевого объекта плана загрузки ЦП, их не нужно исследовать.
Пиковый период для всех систем составляет от 8:00 до 9:15. Средний рабочий день длится с 5:00 до 5:00 вечера. Таким образом, любые случайные пики использования ЦП, которые происходят в период от 5:00 до 4:00, находятся за пределами рабочих часов, и поэтому вам не нужно включать их в задачи планирования емкости.
Примечание.
В хорошо управляемой системе пиковые нагрузки, которые происходят во время вне пикового периода, обычно вызваны программным обеспечением резервного копирования, полными антивирусными средствами, инвентаризацией оборудования или программного обеспечения, развертыванием программного обеспечения или исправлений и т. д. Так как эти пики происходят за пределами рабочих часов, они не учитываются в направлении превышения целевых показателей планирования емкости.
Так как каждая система составляет около 40%, и все они имеют одинаковое количество ЦП, если один из них переходит в автономный режим, остальные системы выполняются примерно на 53%. Система D имеет 40 % нагрузки, которая равномерно разделяется и добавляется в существующую нагрузку System A и C. Это линейное предположение не является совершенно точным, но обеспечивает достаточную точность для датчика.
Далее рассмотрим пример среды, которая не имеет хорошего использования ЦП и превышает целевой объект планирования емкости.
В этом примере у нас есть два контроллера домена, работающих на 40 %. Один контроллер домена переходит в автономный режим, что приводит к предполагаемому использованию ЦП на оставшемся контроллере домена до 80 %. Этот уровень использования ЦП гораздо превышает пороговое значение плана емкости и начинает ограничивать объем головного помещения для 10% до 20% профиля нагрузки. В результате каждый пик может потенциально привести контроллер домена к 90% или даже 100 % во время сценария N , что снижает скорость реагирования.
Вычисление требований ЦП
Счетчик Process\% Processor Time производительности отслеживает общее время всех потоков приложений, потраченных на ЦП, а затем делит эту сумму на общий объем пройденного системного времени. Многопоточное приложение в системе с несколькими ЦП может превышать 100 % времени ЦП, и вы интерпретируете свои данные очень иначе, чем Processor Information\% Processor Utility счетчик. На практике счетчик Process(lsass)\% Processor Time отслеживает, сколько ЦП работает в 100 % системы, требуется для поддержки требований процесса. Например, если счетчик имеет значение 200 %, это означает, что системе требуется два ЦП, работающих на 100 % для поддержки полной загрузки AD DS. Хотя ЦП, работающий в 100 % емкости, является наиболее экономичным с точки зрения потребления энергии и энергии, по причинам, описанным в приложении A, многопоточность системы более быстродействует, если ее система не работает на 100 %.
Чтобы обеспечить временные пики нагрузки клиента, рекомендуется использовать пиковый период ЦП от 40% до 60 % емкости системы. Например, в первом примере в профиле поведения целевого сайта для поддержки загрузки AD DS потребуется от 3,33 ЦП (60 % целевого объекта) до 5 ЦП (40 %. Вы должны добавить дополнительную емкость в соответствии с требованиями ОС и любых других необходимых агентов, таких как антивирусная программа, резервное копирование, мониторинг и т. д. Хотя вы должны оценить влияние агентов на агенты ЦП на основе среды, обычно можно выделить от 5 до 10 % для процессов агента на одном ЦП. Чтобы вернуться к нашему примеру, нам потребуется от 3,43 (60 % целевого объекта) до 5,1 (40 % целевых процессоров) для поддержки нагрузки во время пиковых периодов.
Теперь рассмотрим пример вычисления для определенного процесса. В этом случае мы рассмотрим процесс LSASS.
Вычисление использования ЦП для процесса LSASS
В этом примере система представляет собой сценарий N + 1, где один сервер несет нагрузку AD DS, а дополнительный сервер существует для избыточности.
На следующей диаграмме показано время процессора для процесса LSASS во всех процессорах для этого примера сценария. Эти данные были собраны из счетчика Process(lsass)\% Processor Time производительности.
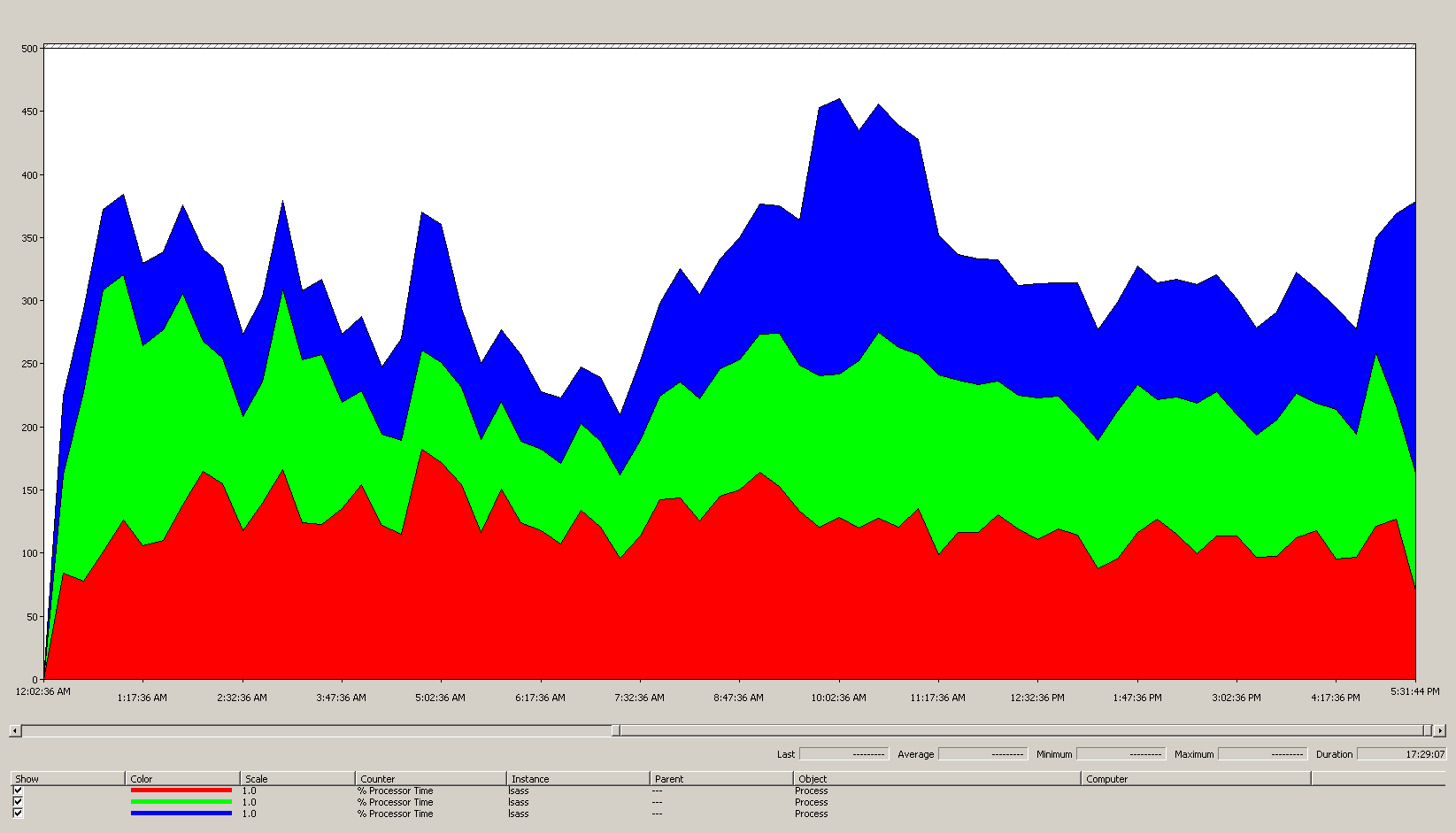
Вот что эта диаграмма рассказывает нам о среде сценария:
- На сайте есть три контроллера домена.
- Рабочий день начинается наращивать около 7:00 утра, а затем нарастает вниз в 5:00 вечера.
- Самый оживленный период дня — от 9:30 до 11:00.
Примечание.
Все данные о производительности являются историческими. Точка пиковых данных в 9:15 указывает нагрузку с 9:00 до 9:15.
- Пики до 7:00 могут указывать на дополнительную нагрузку из разных часовых поясов или фоновых действий инфраструктуры, таких как резервные копии. Однако, поскольку этот пик ниже пиковой активности в 9:30, это не причина для беспокойства.
При максимальной нагрузке процесс lsass потребляет около 4,85 ЦП, работающих на 100 %, что будет 485 % на одном ЦП. Эти результаты показывают, что сайту сценария требуется около 12/25 ЦП для обработки AD DS. При добавлении рекомендуемой 5%-10% дополнительной емкости для фоновых процессов серверу требуется 12,30 до 12,25 ЦП для поддержки текущей нагрузки. Оценки, ожидающие будущего роста, делают это число еще выше.
Настройка весов LDAP
Существуют определенные сценарии, в которых следует рассмотреть возможность настройки LdapSrvWeight. В контексте планирования емкости вы настраиваете его, когда приложения, пользовательские нагрузки или базовые возможности системы не распределяются равномерно.
В следующих разделах описаны два примера сценариев, в которых следует настроить вес протокола LDAP.
Пример 1. Среда эмулятора PDC
Если вы используете эмулятор основного контроллера домена (PDC), поведение пользователей или приложений с неравномерно распределенным распределением может повлиять на несколько сред одновременно. Ресурсы ЦП в эмуляторе PDC часто чаще требуются, чем в другом месте развертывания, так как в нем используются несколько средств и действий, таких как средства управления групповыми политиками, вторая попытка проверки подлинности, создание доверия и т. д.
- Необходимо настроить эмулятор PDC только в том случае, если есть заметное различие в использовании ЦП. Настройка должна снизить нагрузку на эмулятор PDC и увеличить нагрузку на другие контроллеры домена, что позволяет более равномерно распределять нагрузку.
- В этих случаях задайте значение от
LDAPSrvWeight50 до 75 для эмулятора PDC.
| Системные | Использование ЦП с значениями по умолчанию | Новый ldapSrvWeight | Оценка нового использования ЦП |
|---|---|---|---|
| DC 1 (эмулятор PDC) | 53 % | 57 | 40% |
| DC 2 | 33% | 100 | 40% |
| DC 3 | 33% | 100 | 40% |
Уловка заключается в том, что если роль эмулятора PDC передается или захватывается, особенно другому контроллеру домена на сайте, то использование ЦП значительно увеличивается на новом эмуляторе PDC.
В этом примере предполагается, что на основе профиля поведения целевого сайта все три контроллера домена на этом сайте имеют четыре ЦП. В обычных условиях, что произойдет, если один из этих ЦП имел восемь ЦП? Было бы два контроллера домена при использовании 40 % и один при 20% использовании. Хотя эта конфигурация не обязательно плоха, здесь есть возможность использовать настройку веса LDAP для балансировки нагрузки лучше.
Пример 2. Среда с разными счетчиками ЦП
Если у вас есть серверы с разными счетчиками ЦП и скоростью на одном сайте, необходимо убедиться, что они равномерно распределены. Например, если на вашем сайте есть два восьмиядерных сервера и один четырехядерный сервер, четырехядерный сервер имеет только половину мощности обработки других двух серверов. Если нагрузка клиента равномерно распределена, это означает, что четырехядерный сервер должен работать в два раза сложнее, чем два восьми основных сервера для управления загрузкой ЦП. Поверх этого, если один из восьми основных серверов переходит в автономный режим, четырехядерный сервер перегружается.
| Системные | Сведения о процессоре\ служебная программа процессора (_Total) Использование ЦП с значениями по умолчанию |
Новый ldapSrvWeight | Оценка нового использования ЦП |
|---|---|---|---|
| 4-ЦП DC 1 | 40 | 100 | 30% |
| 4-ЦП DC 2 | 40 | 100 | 30% |
| 8-ЦП DC 3 | 20 | 200 | 30% |
Планирование сценария "N + 1" имеет первостепенное значение. Влияние одного контроллера домена в автономном режиме должно быть рассчитано для каждого сценария. В приведенном выше сценарии, где распределение нагрузки даже, чтобы обеспечить 60 % нагрузки во время сценария N, с равномерной балансировкой нагрузки на всех серверах, распределение отлично, так как коэффициенты остаются согласованными. При просмотре сценария настройки эмулятора PDC или любого общего сценария, в котором нагрузка пользователя или приложения не сбалансирована, эффект очень отличается:
| Системные | Настройка использования | Новый ldapSrvWeight | Предполагаемое использование новых данных |
|---|---|---|---|
| DC 1 (эмулятор PDC) | 40% | 85 | 47 % |
| DC 2 | 40% | 100 | 53 % |
| DC 3 | 40% | 100 | 53 % |
Рекомендации по виртуализации для обработки
При планировании емкости для виртуализированной среды необходимо учитывать два уровня: уровень узла и гостевой уровень. На уровне узла необходимо определить пиковые периоды бизнес-цикла. Так как планирование гостевых потоков на ЦП для виртуальной машины аналогично получению потоков AD DS на ЦП физического компьютера, мы по-прежнему рекомендуем использовать 40% до 60% базового узла. На гостевом уровне, так как базовые принципы планирования потоков не изменяются, мы также рекомендуем сохранить использование ЦП в диапазоне от 40 до 60 %.
В сценарии с прямым сопоставлением с одним гостем на узел необходимо принести все оценки планирования емкости, выполненные в предыдущих разделах, чтобы сделать оценку. Для сценария общего узла около 10 % влияет на эффективность базовых процессоров, что означает, что если сайту требуется 10 ЦП в целевой показатель 40%, рекомендуемое количество виртуальных ЦП, которые следует выделить для всех гостей N , будет 11. На сайтах с смешанным распределением физических и виртуальных серверов этот модификатор применяется только к виртуальным машинам (виртуальным машинам). Например, в сценарии N + 1 физический или прямой сопоставленный сервер с 10 ЦП почти равен одному гостьу с 11 ЦП на узле с 11 процессорами, зарезервированными для контроллера домена.
При анализе и вычислении количества ЦП, необходимых для поддержки загрузки AD DS, помните, что если вы планируете приобрести физическое оборудование, типы оборудования, доступные на рынке, могут не сопоставляться точно с оценками. Однако при использовании виртуализации у вас нет этой проблемы. Использование виртуальных машин уменьшает усилия, необходимые для добавления вычислительной емкости на сайт, так как можно добавить столько ЦП с точными спецификациями, которые требуется для виртуальной машины. Однако виртуализация не устраняет вашу ответственность за точное вычисление вычислительных ресурсов, необходимых для обеспечения доступности базового оборудования, если гостям требуется больше ЦП. Как всегда, не забудьте заранее планировать рост.
Пример сводки вычислений виртуализации
| Системные | Пиковый ЦП |
|---|---|
| DC 1 | 120 % |
| DC 2 | 147% |
| DC 3 | 218% |
| Общее использование ЦП | 485% |
| Число целевых систем | Общая пропускная способность (из выше) |
|---|---|
| ЦП, необходимые в целевом объекте 40 % | 4.85 ÷ .4 = 12.25 |
При планировании роста в этом сценарии, если предположить, что спрос будет расти на 50% в течение следующих трех лет, необходимо убедиться, что к тому времени он имеет 18,375 ЦП (12,25 × 1,5). Кроме того, вы можете просмотреть спрос после первого года, а затем добавить дополнительную емкость в зависимости от того, какие результаты говорят вам.
Загрузка проверки подлинности клиента с перекрестным доверием для NTLM
Оценка нагрузки проверки подлинности клиента с перекрестным доверием
Во многих средах может быть один или несколько доменов, подключенных к доверию. Запросы проверки подлинности для удостоверений в других доменах, которые не используют Kerberos, должны проходить проверку доверия с помощью безопасного канала между двумя контроллерами домена. Контроллер домена, который пользователь пытается получить доступ к сайту, подключается к другому контроллеру домена, расположенному в целевом домене или где-то дальше по пути к целевому домену. Сколько вызовов контроллер домена может выполнять к другому контроллеру домена в доверенном домене, управляется параметром *MaxConcurrentAPI . Чтобы обеспечить защиту канала, можно обрабатывать объем нагрузки, необходимый для взаимодействия между контроллерами домена, можно настроить MaxConcurrentAPI или, если вы находитесь в лесу, создайте ярлыки доверия. Дополнительные сведения о том, как определить объем трафика в довериях, см. в разделе "Как настроить производительность для проверки подлинности NTLM" с помощью параметра MaxConcurrentApi.
Как и в предыдущих сценариях, необходимо собирать данные в периоды пиковой нагрузки дня, чтобы он был полезным.
Примечание.
Сценарии внутрифорестных и межфорестных сценариев могут привести к проверке подлинности для прохождения нескольких доверий, что означает, что необходимо настроить на каждом этапе процесса.
Планирование виртуализации
При планировании емкости для виртуализации следует учитывать несколько действий.
- Многие приложения используют проверку подлинности диспетчера доверия (NTLM) по умолчанию или в определенных конфигурациях.
- По мере увеличения числа активных клиентов требуется больше емкости серверов приложений.
- Клиенты иногда открывают сеансы в течение ограниченного времени и вместо этого регулярно подключаются для таких служб, как синхронизация по запросу электронной почты.
- Веб-прокси-серверы, требующие проверки подлинности для доступа к Интернету, могут вызвать высокую нагрузку NTLM.
Эти приложения могут создавать большую нагрузку для проверки подлинности NTLM, что значительно влияет на контроллеры домена, особенно если пользователи и ресурсы находятся в разных доменах.
Существует множество подходов, которые можно использовать для управления нагрузкой между отношениями доверия, которые часто можно использовать вместе:
- Уменьшите проверку подлинности клиента с перекрестным доверием, разместив службы, которые пользователь использует в домене, в который они находятся.
- Увеличьте количество доступных безопасных каналов. Эти каналы называются ярлыками доверия и относятся к внутрифорестному и межлесового трафика.
- Настройте параметры по умолчанию для MaxConcurrentAPI.
Чтобы настроить MaxConcurrentAPI на существующем сервере, используйте следующее уравнение:
New_MaxConcurrentApi_setting ≥ × average_semaphore_hold_time semaphore_acquires + × semaphore_time × ÷ time_collection_length
Дополнительные сведения см . в статье базы знаний 2688798. Как настроить производительность для проверки подлинности NTLM с помощью параметра MaxConcurrentApi.
Сведения о виртуализации
Нет особых соображений, которые необходимо учитывать, так как виртуализация является параметром настройки операционной системы.
Пример вычисления настройки виртуализации
| Тип данных | Значение |
|---|---|
| Семафор получает (минимум) | 6,161 |
| Семафор получает (максимум) | 6,762 |
| Время ожидания Семафора | 0 |
| Среднее время удержания Семафора | 0.012 |
| Длительность сбора (секунды) | 1:11 минут (71 секунды) |
| Формула (из базы знаний 2688798) | ((6762 - 6161) + 0) × 0,012 / |
| Минимальное значение maxConcurrentAPI | ((6762 - 6161) + 0) × 0,012 ÷ 71 = .101 |
Для этой системы в течение этого периода времени допустимы значения по умолчанию.
Мониторинг соответствия целям планирования емкости
В этой статье мы обсудили, как планирование и масштабирование направлены на целевые показатели использования. В следующей таблице приведены рекомендуемые пороговые значения, которые необходимо отслеживать, чтобы гарантировать, что системы работают должным образом. Имейте в виду, что это не пороговые значения производительности, а только пороговые значения планирования емкости. Сервер, работающий с превышением этих пороговых значений, по-прежнему будет работать, но перед началом просмотра проблем с производительностью по мере увеличения спроса пользователей необходимо проверить работу приложений. Если приложения в порядке, следует начать оценку обновлений оборудования или других изменений конфигурации.
| Категория | Счетчик производительности | Интервал или выборка | Назначение | Предупреждение |
|---|---|---|---|---|
| Процессор | Processor Information(_Total)\% Processor Utility |
60 мин | 40% | 60 % |
| ОЗУ (Windows Server 2008 R2 или более ранней версии) | Память\Доступно МБ | < 100 МБ | Н/П | < 100 МБ |
| ОЗУ (Windows Server 2012) | Память\долгосрочное время существования резервного кэша | 30 мин | Необходимо проверить | Необходимо проверить |
| Network | Сетевой интерфейс(*)\Байт Sent/sec Сетевой интерфейс(*)\Байт получено/с |
30 мин | 40% | 60 % |
| Хранилище | LogicalDisk()<NTDS Database Drive>\Avg Disk sec/ReadLogicalDisk(( |
60 мин | 10 мс | 15 мс |
| Службы AD | Netlogon(*)\Среднее время удержания Семафора | 60 мин | 0 | 1 с |
Приложение A. Критерии изменения размера ЦП
В этом приложении рассматриваются полезные термины и понятия, которые помогут оценить потребности в размерах ЦП вашей среды.
Определения: размер ЦП
Процессор (микропроцессор) — это компонент, который считывает и выполняет инструкции программы.
Процессор с несколькими ядрами имеет несколько ЦП в одном интегрированном канале.
Система с несколькими ЦП имеет несколько ЦП, которые не имеют одного интегрированного канала.
Логический процессор — это процессор , имеющий только один логический вычислительный модуль с точки зрения операционной системы.
К этим определениям относятся гиперпотоки, один ядро на многоядерный процессор или один основной процессор.
Так как в современных серверных системах имеется несколько процессоров, несколько многоядерных процессоров и гиперпотоков, эти определения обобщены для покрытия обоих сценариев. Мы используем логический процессор, так как представляет ос и перспективу приложения доступных вычислительных ядер.
Параллелизм на уровне потока
Каждый поток является независимой задачей, так как каждый поток имеет собственный стек и инструкции. AD DS является многопоточной, и вы можете настроить количество доступных потоков, следуя указаниям в разделе "Как просмотреть и задать политику LDAP в Active Directory с помощью Ntdsutil.exe", она хорошо масштабируется между несколькими логическими процессорами.
Параллелизм на уровне данных
Параллелизм на уровне данных заключается в том, что служба делится данными между несколькими потоками для одного процесса и совместного использования нескольких потоков в нескольких процессах. Процесс AD DS только подсчитывается как общий доступ к данным службы в нескольких потоках для одного процесса. Все изменения данных отражаются во всех выполняемых потоках во всех уровнях кэша, каждого ядра и любых обновлений общей памяти. Производительность может снизиться во время операций записи, так как все расположения памяти изменяются до продолжения обработки инструкций.
Рекомендации по скорости ЦП и нескольким ядрам
Как правило, более быстрые логические процессоры сокращают время, необходимое для обработки ряда инструкций. Более логические процессоры означают, что одновременно можно выполнять больше задач. Однако эти правила не применяются в сценариях, которые являются более сложными, например получение данных из общей памяти, ожидание параллелизма на уровне данных и затраты на управление несколькими потоками одновременно. В результате масштабируемость в многоядерных системах не является линейной.
Чтобы понять, почему это изменение происходит, это помогает подумать об этих сценариях, как шоссе. Каждый поток является отдельным автомобилем, каждая полоса является ядром, и ограничение скорости является скоростью часов.
Если на шоссе есть только одна машина, это не имеет значения, если есть две или 12 полос. Этот автомобиль идет так быстро, как разрешено ограничение скорости.
Если данные, необходимые потоку, не сразу доступны, поток не сможет обрабатывать инструкции, пока не извлекает соответствующие данные из памяти. Это как если сегмент шоссе закрывается. Даже если на шоссе есть только один автомобиль, ограничение скорости не повлияет на его способность путешествовать, потому что он не может идти куда-либо, пока дорога не вновь откроется.
По мере увеличения числа автомобилей, накладные расходы, необходимые шоссе для управления количеством автомобилей, также увеличивается. Водители должны сосредоточиться труднее, когда ездить на шоссе во время пик-часа движения, а не поздно вечером, когда дорога в основном пуста. Кроме того, вождение на двух полосе шоссе, где вам нужно только беспокоиться о одной другой полосе требует меньше внимания, чем вождения на шести полосе шоссе, где у вас есть пять других полос движения, чтобы обратить внимание на.
В итоге вопросы о том, следует ли добавлять более или более быстрые процессоры, становятся весьма субъективными и должны рассматриваться на основе регистра. Для AD DS, в частности, его потребности в обработке зависят от экологических факторов и могут отличаться от сервера до сервера в пределах одной среды. В результате предыдущие разделы в этой статье не вкладывайте значительные средства в создание супер точных вычислений. При принятии решений по покупке на основе бюджета рекомендуется сначала оптимизировать использование процессора на 40 % или в зависимости от того, что требуется для конкретной среды. Если ваша система не оптимизирована, вы не получаете выгоду от покупки дополнительных процессоров.
Примечание.
Закон Амдала и закон Густафсона являются соответствующими понятиями здесь.
Время отклика и влияние уровней действий системы на производительность
Теория очередей — это математическое исследование очередей или очередей. В теории очередей для вычислений закон использования представлен формулой t:
U k = B ÷ T
Где U k является процентом использования, B — это время, затрачиваемое на занятое время, и T — общее время, затрачиваемое на наблюдение за системой. В контексте Майкрософт это означает количество потоков интервала 100-nanosecond (ns), разделенных на количество интервалов 100-ns в заданном интервале времени. Это та же формула, которая вычисляет процент использования процессора, показанный в объекте процессора и PERF_100NSEC_TIMER_INV.
Теория очереди также предоставляет формулу: N U k ÷ (1 – U k) для оценки количества ожидающих элементов на основе использования, где N = — длина очереди. Диаграмма этого уравнения по всем интервалам использования предоставляет следующие оценки того, сколько времени очередь для получения на процессоре находится в любой заданной нагрузке ЦП.
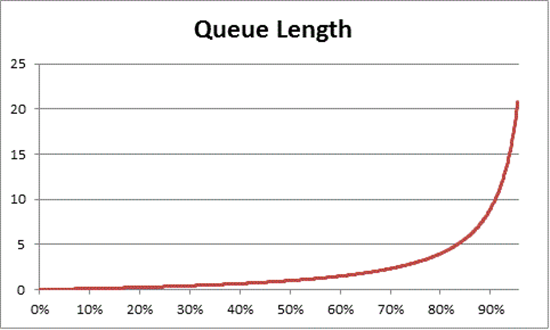
На основе этой оценки мы можем наблюдать, что после 50% загрузки ЦП среднее ожидание обычно включает один другой элемент в очереди и быстро увеличивается до 70 % использования ЦП.
Чтобы понять, как теория очередей применяется к развертыванию AD DS, давайте вернемся к метафоре шоссе, которую мы использовали в скорости ЦП и в нескольких ядрах.
Автобусные времена в середине дня упали бы где-то на 40% до 70% диапазона емкости. Есть достаточно трафика, что ваша способность выбирать полосу для езды не сильно ограничена. Хотя шанс другого водителя попасть на ваш путь высокий, он не требует того же уровня усилий, что вам потребуется найти безопасный разрыв между другими автомобилями в полосе, как во время пик-часа.
По мере приближения часа пиков система дорог приближается к 100% емкости. Смена полос во время пик-часа становится очень сложной, потому что автомобили настолько близки вместе, что у вас нет столько места для маневра при изменении полос.
Именно поэтому оценка долгосрочных средних значений для емкости на 40 % позволяет больше головы для аномальных пиков нагрузки, будь то временные пики, такие как с плохо закодированных запросов, которые занимает некоторое время для выполнения, или аномальные всплески общей нагрузки, как пик активности утром после выходных праздников.
Предыдущее заявление относится к проценту вычисления процессорного времени так же, как и уравнение законодательства об использовании. Эта упрощенная версия предназначена для внедрения концепции для новых пользователей. Однако для более сложных математических вычислений можно использовать следующие ссылки в качестве руководства:
- Преобразование PERF_100NSEC_TIMER_INV
- B = количество интервалов 100-ns, которые расходуется потоком простоя на логический процессор. Изменение переменной X в вычислении PERF_100NSEC_TIMER_INV
- T = общее число интервалов 100-ns в заданном диапазоне времени. Изменение переменной Y в вычислении PERF_100NSEC_TIMER_INV.
- U k = процент использования логического процессора в потоке простоя или % времени простоя.
- Разработка математики:
- U k = 1 – %Processor Time
- %Processor Time = 1 – U k
- %Processor Time = 1 – B / T
- %Processor Time = 1 – X1 – X0 / Y1 – Y0
Применение этих концепций к планированию емкости
Математика в предыдущем разделе, вероятно, делает определение количества логических процессоров, необходимых в системе, кажется очень сложным. В результате подход к определению размера системы должен сосредоточиться на определении максимального целевого использования на основе текущей нагрузки, а затем вычисление количества логических процессоров, необходимых для достижения этого целевого объекта. Кроме того, ваша оценка не должна быть совершенно точной. Хотя скорость логического процессора оказывает значительное влияние на синхронизацию, производительность также может повлиять на другие области:
- Эффективность кэша
- Требования к согласованности памяти
- Планирование потоков и синхронизация
- Несовершенные нагрузки клиента
Так как вычислительная мощность относительно низкая стоимость, это не стоит инвестировать слишком много времени в вычислении идеально точного количества ЦП, необходимых вам.
Также важно помнить, что рекомендация 40% в данном случае не является обязательным требованием. Мы используем его в качестве разумного начала для вычисления. Для различных типов пользователей AD требуются различные уровни реагирования. Существуют даже сценарии, в которых среды могут работать на уровне 80% или даже 90% использования в устойчивом среднем без увеличения времени ожидания доступа к процессору, заметно влияющего на производительность клиента.
В системе также есть другие области, которые гораздо медленнее, чем логический процессор, который также следует настроить, включая доступ к ОЗУ, доступ к диску и передачу ответов по сети. Например:
Если вы добавляете процессоры в систему с 90% использованием, привязанной к диску, это, вероятно, не значительно улучшит производительность. Если вы более внимательно посмотрите на систему, есть много потоков, которые даже не входят в процессор, потому что они ожидают завершения операций ввода-вывода.
Устранение проблем, связанных с диском, может означать, что потоки, ранее застрявшие в состоянии ожидания, застряли, создавая больше конкуренции на время ЦП. В результате использование 90 % будет переходить на 100 %. Чтобы вернуть использование к управляемым уровням, необходимо настроить оба компонента.
Примечание.
Счетчик
Processor Information(*)\% Processor Utilityможет превышать 100 % с системами с режимом Turbo. Режим turbo позволяет ЦП превышать скорость процессора с оценкой в течение коротких периодов. Если вам нужна дополнительная информация, ознакомьтесь с документацией производителей ЦП и описаниями счетчиков.
Обсуждение вопросов использования всей системы также включает контроллеры домена в качестве виртуализированных гостей. Время отклика и то, как уровни действий системы влияют на производительность как узла, так и гостя в виртуализированном сценарии. В узле только с одним гостем контроллер домена или система имеет почти ту же производительность, что и на физическом оборудовании. Добавление дополнительных гостей к узлам увеличивает использование базового узла, а также увеличивает время ожидания, чтобы получить доступ к процессорам. Поэтому необходимо управлять использованием логического процессора как на уровне узла, так и на гостевых уровнях.
Давайте вернемся к метафоре шоссе из предыдущих разделов, только на этот раз мы представим гостевую виртуальную машину как экспресс-автобус. Экспресс-автобусы, в отличие от общественного транспорта или школьных автобусов, идут прямо к месту назначения всадника без каких-либо остановок.
Теперь рассмотрим четыре сценария:
- Системы вне пиковые часы, как езда на экспресс-автобус поздно вечером. Когда всадник попадает, почти нет других пассажиров, и дорога почти пуста. Потому что нет движения для автобуса, чтобы бороться, поездка легко и так же быстро, как если бы всадник ехал там в своей собственной машине. Однако время движения всадника также ограничено местным ограничением скорости.
- Вне пиковые часы, когда загрузка ЦП системы слишком высока, как поздние ночные поездки, когда большинство полос на шоссе закрыты. Несмотря на то, что сам автобус в основном пуст, дорога по-прежнему перегружена от левого движения, который имеет дело с ограниченными полосами движения. Хотя всадник свободен сидеть где угодно, их фактическое время поездки определяется движением за пределами автобуса.
- Система с высокой загрузкой ЦП в часы пиковой нагрузки похожа на переполненный автобус во время пик-часа. Не только поездка занимает больше времени, но и добраться до автобуса сложнее, потому что автобус заполнен другими пассажирами. Добавление дополнительных логических процессоров в гостевую систему, чтобы попытаться ускорить время ожидания, будет похоже на попытку решить проблему движения, добавив больше автобусов. Проблема не в количестве автобусов, а в том, сколько времени занимает поездка.
- Система с высокой загрузкой ЦП в нерабочие часы похожа на ту же переполненную автобусную шину в основном пустой дороге ночью. В то время как всадники могут иметь проблемы с поиском мест или попасть на автобус и от автобуса, поездка довольно гладко, как только автобус берет всех своих пассажиров. Этот сценарий является единственным, где производительность улучшится путем добавления дополнительных автобусов.
На основе предыдущих примеров можно увидеть, что существует множество сценариев от 0% до 100% использования, которые имеют различные степени влияния на производительность. Кроме того, добавление дополнительных логических процессоров не обязательно повышает производительность за пределами очень конкретных сценариев. Это должно быть довольно просто, чтобы применить эти принципы к рекомендуемой цели использования ЦП на 40 % для узлов и гостей.
Приложение B. Рекомендации по различным скоростям процессора
В процессе обработки предполагается, что процессор работает на скорости 100 % при сборе данных и что все системы замены имеют одинаковую скорость обработки. Несмотря на то, что эти предположения не являются точными, особенно для Windows Server 2008 R2 и более поздних версий, где план питания по умолчанию сбалансирован, эти предположения по-прежнему работают для консервативных оценок. В то время как возможные ошибки могут увеличиться, это только увеличивает предел безопасности по мере увеличения скорости процессора.
- Например, в сценарии, требующего 11,25 ЦП, если процессоры работали на половину скорости при сборе данных, то более точную оценку их спроса будет составлять 5,125 ÷ 2.
- Невозможно гарантировать, что удвоение скорости часов увеличивает объем обработки, которая происходит в течение записанного периода времени. Время, затраченное процессорами на ожидание ОЗУ или других компонентов, остается примерно таким же. Таким образом, более быстрые процессоры могут тратить больший процент времени простоя во время ожидания получения данных системой. Мы рекомендуем придерживаться наименьшего общего знаменателя, держать оценки консервативными и избегать линейного сравнения скоростей процессора, которые могут сделать ваши результаты неточными.
Если скорость процессора в заменяемом оборудовании ниже текущего оборудования, следует пропорционально увеличить оценку количества необходимых процессоров. Например, рассмотрим сценарий, в котором вы вычисляете 10 процессоров для поддержания нагрузки сайта. Текущие процессоры выполняются в 3,3 ГГц, а процессоры, которые планируется заменить на 2,6 ГГц. Замена только 10 исходных процессоров даст вам 21% снижение скорости. Чтобы увеличить скорость, необходимо получить по крайней мере 12 процессоров вместо 10.
Однако эта переменная не изменяет целевые показатели использования процессора управления емкостью. Скорость процессора настраивается динамически на основе спроса на нагрузку, поэтому выполнение системы под более высокими нагрузками приводит к тому, что ЦП тратит больше времени в более высоком состоянии скорости часов. Конечная цель заключается в том, чтобы ЦП был на уровне 40 % использования в состоянии скорости 100 % в течение пиковых рабочих часов. Что-нибудь меньшее приведет к экономии энергии путем регулирования скоростей ЦП во время сценариев вне пиковой нагрузки.
Примечание.
Вы можете отключить управление питанием на процессорах во время сбора данных, установив план питания на высокий уровень производительности. Отключение управления питанием обеспечивает более точное чтение потребления ЦП на целевом сервере.
Чтобы настроить оценки для разных процессоров, рекомендуется использовать SPECint_rate2006 эталонный тест от корпорации оценки производительности уровня "Стандартный". Чтобы использовать этот тест, выполните указанные ниже действия.
Перейдите на веб-сайт Standard Performance Evaluation Corporation (SPEC).
Выберите Результаты.
Введите CPU2006 и выберите "Поиск".
В раскрывающемся меню для доступных конфигураций выберите все CPU2006 SPEC.
В поле "Запрос формы поиска" выберите "Простой", а затем нажмите кнопку Go!.
В разделе "Простой запрос" введите условия поиска для целевого процессора. Например, если вы ищете процессор ES-2630, в раскрывающемся меню выберите обработчик, а затем введите имя процессора в поле поиска. По завершении нажмите кнопку "Выполнить простую выборку".
Найдите конфигурацию сервера и процессора в результатах поиска. Если поисковая система не возвращает точное совпадение, найдите ближайшее совпадение.
Запишите значения в столбцах Result и #Cores .
Определите модификатор с помощью следующего уравнения:
((Значение оценки целевой платформы на ядро) × (МГц на ядро базовой платформы)) ÷ ((базовое значение оценки на ядро) × (МГц на ядро целевой платформы))
Например, вот как найти модификатор для процессора ES-2630:
(35.83 × 2000) ÷ (33,75 × 2300) = 0,92
Умножьте количество процессоров, которые вы оцениваете, на этот модификатор.
Для примера процессора ES-2630 0.92 × 10.3 = 10,35 процессоров.
Приложение C. Взаимодействие операционной системы с хранилищем
Концепции очереди, которые мы обсуждали во время отклика и как уровни действий системы влияют на производительность также применяются к хранилищу. Чтобы эффективно применять эти понятия, необходимо ознакомиться с тем, как операционная система обрабатывает операции ввода-вывода. В ос Windows операционная система создает очередь, в которой хранятся запросы ввода-вывода для каждого физического диска. Однако физический диск не обязательно является одним диском. ОС также может зарегистрировать агрегирование спинделей на контроллере массива или SAN в качестве физического диска. Контроллеры массива и saN также могут объединять несколько дисков в один набор массивов, разделяя их на несколько секций, а затем использовать каждую секцию в качестве физического диска, как показано на следующем рисунке.
На этом рисунке два шпинделя зеркально отражаются и разделяются на логические области для хранения данных, помеченных как Data 1 и Data 2. ОС регистрирует каждую из этих логических областей в виде отдельных физических дисков.
Теперь, когда мы уточнили, что определяет физический диск, вы также должны ознакомиться со следующими терминами, чтобы лучше понять информацию в этом приложении.
- Спиндл — это устройство, физическое установленное на сервере.
- Массив представляет собой коллекцию спинделей, агрегированных контроллером.
- Секционирование массива — это секционирование агрегированного массива.
- Логический номер единицы (LUN) — это массив устройств SCSI, подключенных к компьютеру. В этой статье используются эти термины при разговоре о SAN.
- Диск включает в себя любой спинд или секцию, регистрируемую ОС в качестве одного физического диска.
- Секция — это логическая секционирование того, что ОС регистрирует как физический диск.
Рекомендации по архитектуре операционной системы
ОС создает очередь ввода-вывода первого входа (FIFO) для каждого диска, который он регистрирует. Эти диски могут быть спинделями, массивами или секциями массивов. Когда дело доходит до того, как ОС обрабатывает операции ввода-вывода, чем больше активных очередей, тем лучше. Когда ОС сериализует очередь FIFO, она должна обрабатывать все запросы FIFO ввода-вывода, выданные подсистеме хранения в порядке прибытия. При сопоставлении каждого диска с спиндлом или массивом оси сохраняет очередь ввода-вывода для каждого уникального набора дисков, устраняя конкуренцию за ограниченные ресурсы ввода-вывода на разных дисках и изоляцию требований ввода-вывода к одному диску. Однако Windows Server 2008 представила исключение в виде приоритета ввода-вывода. Приложения, предназначенные для использования низкоприоритетных операций ввода-вывода, перемещаются в спину очереди независимо от того, когда ОС получила их. Вместо этого приложения не кодируются для использования параметра низкого приоритета по умолчанию для нормального приоритета.
Знакомство с простыми подсистемами хранения
В этом разделе описаны простые подсистемы хранения. Начнем с примера: один жесткий диск на компьютере. Если мы разбиим эту систему на основные компоненты подсистемы хранения, вот что мы получаем:
- Один из 10 000 RPM Ultra Fast SCSI HD (Ультра Fast SCSI имеет скорость передачи 20 МБИТ/с)
- Одна шина SCSI (кабель)
- Один адаптер fast SCSI
- Одна 32-разрядная шина PCI 33 МГц
Примечание.
Этот пример не отражает кэш диска, в котором система обычно хранит данные одного цилиндра. В этом случае первый ввод-вывод должен иметь 10 мс, а диск считывает весь цилиндр. Все остальные последовательные ввода-вывода удовлетворены кэшем. В результате кэши на диске могут повысить производительность последовательного ввода-вывода.
После идентификации компонентов вы можете получить представление о том, сколько данных система может передавать и сколько операций ввода-вывода она может обрабатывать. Объем операций ввода-вывода и количества данных, которые могут транзитировать систему, связаны друг с другом, но не одинаковым значением. Эта корреляция зависит от размера блока и того, является ли диск операцией ввода-вывода случайным или последовательным. Система записывает все данные на диск в виде блока, но разные приложения могут использовать разные размеры блоков.
Далее давайте рассмотрим эти элементы на основе компонента.
Время доступа к жесткому диску
Средний жесткий диск с скоростью 10 000 RPM имеет время поиска 7 мс и время доступа в 3 мс. Время поиска — это среднее время, которое занимает время чтения или записи, чтобы переместиться в расположение на тарелке. Время доступа — это среднее время, необходимое для чтения или записи данных на диск после того, как он находится в правильном расположении. Таким образом, среднее время чтения уникального блока данных в 10 000-RPM HD включает время поиска и доступа в общей сложности около 10 мс или 010 секунд на блок данных.
При каждом доступе к диску требуется перемещение головы в новое расположение на диске, поведение чтения или записи вызывается случайным образом. Если все операции ввода-вывода являются случайными, 10 000-RPM HD может обрабатывать примерно 100 операций ввода-вывода в секунду (операций ввода-вывода в секунду).
Когда все операции ввода-вывода происходят из смежных секторов на жестком диске, мы называем его последовательным вводом-выводом. Последовательный ввод-вывод не имеет времени поиска, так как после завершения первого ввода-вывода головка чтения или записи находится в начале места хранения следующего блока данных. Например, 10 000-RPM HD может обрабатывать примерно 333 операций ввода-вывода в секунду на основе следующего уравнения:
1000 мс в секунду ÷ 3 мс на ввод-вывод
До сих пор скорость передачи жесткого диска не относится к нашему примеру. Независимо от размера жесткого диска фактический объем операций ввода-вывода в секунду, который может обрабатывать 10 000 RPM HD, всегда составляет около 100 случайных или 300 последовательных операций ввода-вывода. Так как размеры блоков изменяются в зависимости от того, какое приложение записывает на диск, объем данных, извлекаемых на ввод-вывод, также изменяется. Например, если размер блока составляет 8 КБ, операции ввода-вывода 100 будут считываться или записываться на жесткий диск в общей сложности 800 КБ. Однако если размер блока составляет 32 КБ, 100 операций ввода-вывода считывают или записывают 3200 КБ (3,2 МБ) на жесткий диск. Если скорость передачи SCSI превышает общий объем передаваемых данных, то скорость передачи быстрее не меняется. Дополнительные сведения см. в следующих таблицах:
| Description | 7200 RPM 9 ms seek, 4 мс доступа | 10 000 RPM 7 мс искать, 3 мс доступа | 15 000 RPM 4 мс искать, 2 мс доступа |
|---|---|---|---|
| Случайный ввод-вывод | 80 | 100 | 150 |
| Последовательный ввод-вывод | 250 | 300 | 500 |
| 10 000 дисков RPM | Размер блока 8 КБ (Active Directory Jet) |
|---|---|
| Случайный ввод-вывод | 800 КБ/с |
| Последовательный ввод-вывод | 2400 КБ/с |
Серверная планка SCSI
Как серверная планка SCSI, которая в этом примере является кабелем ленты, влияет на пропускную способность подсистемы хранения зависит от размера блока. Сколько операций ввода-вывода может обрабатывать шина, если ввода-вывода находится в блоках 8 КБ? В этом сценарии шина SCSI составляет 20 МБИТ/с или 20480 КБ/с. 20480 КБ/с, разделенных на 8 КБ блоков, дает максимум 2500 операций ввода-вывода в секунду, поддерживаемых шиной SCSI.
Примечание.
Цифры в следующей таблице представляют пример сценария. Большинство подключенных устройств хранения в настоящее время используют PCI Express, что обеспечивает гораздо более высокую пропускную способность.
| Ввод-вывод, поддерживаемый шиной SCSI на размер блока | Размер блока 2 КБ | Размер блока 8 КБ (AD Jet) (SQL Server 7.0/SQL Server 2000) |
|---|---|---|
| 20 Мбит/с | 10,000 | 2500 |
| 40 Мбит/с | 20,000 | 5,000 |
| 128 МБИТ/с | 65 536 | 16,384 |
| 320 Мбит/с | 160 000 | 40 000 |
Как показано в предыдущей таблице, в нашем примере шина никогда не является узким местом, так как максимальное число операций ввода-вывода составляет 100 операций ввода-вывода, так как ниже любого из перечисленных пороговых значений.
Примечание.
В этом сценарии предполагается, что шина SCSI эффективна на 100 %.
Адаптер SCSI
Чтобы определить, сколько операций ввода-вывода система может обрабатывать, необходимо проверить спецификации производителя. Для перенаправления запросов ввода-вывода на соответствующее устройство требуется мощность обработки, поэтому объем операций ввода-вывода в системе зависит от адаптера SCSI или процессора контроллера массива.
В этом примере предполагается, что система может обрабатывать 1000 операций ввода-вывода.
Шина PCI
Шина PCI — это неучтаемый компонент. В этом примере шина PCI не является узким местом. Однако по мере увеличения масштаба систем она может стать узким местом в будущем.
Мы видим, сколько шина PCI может передавать данные в нашем примере с помощью следующего уравнения:
32 бита ÷ 8 бит в байтах × 33 МГц = 133 МБИТ/с
Поэтому можно предположить, что 32-разрядная шина PCI, работающая в 33 МГц, может передавать 133 Мбит/с данных.
Примечание.
Результат этого уравнения представляет теоретический предел передаваемых данных. В действительности большинство систем достигают только 50% максимального ограничения. В некоторых сценариях всплеска система может достичь 75% ограничения в течение коротких периодов.
66 МГц 64-разрядная шина PCI может поддерживать теоретический максимум 528 МБИТ/с на основе этого уравнения:
64 бита ÷ 8 бит на байт × 66 МГц = 528 МБИТ/с
При добавлении любого другого устройства, например сетевого адаптера или второго контроллера SCSI, она уменьшает пропускную способность, доступную для системы, так как все устройства совместно используют пропускную способность и могут конкурировать друг с другом за ограниченные ресурсы обработки.
Анализ подсистем хранения для поиска узких мест
В этом сценарии спиндел является фактором ограничения количества операций ввода-вывода, которые можно запросить. В результате это узкое место также ограничивает объем данных, которые система может передавать. Так как наш пример является сценарием AD DS, объем передаваемых данных составляет 100 случайных операций ввода-вывода в секунду в 8 КБ приращении к 8 КБ в общей сложности 800 КБ в секунду при доступе к базе данных Jet. В отличие от этого, максимальная пропускная способность для спинделя, настроенного исключительно для выделения файлов журналов, будет ограничена 300 последовательными ввода-выводами в секунду в 8 КБ, что составляет 2400 КБ или 2,4 МБ в секунду.
Теперь, когда мы проанализировали компоненты нашей конфигурации примера, давайте рассмотрим таблицу, демонстрирующую, где узкие места могут произойти при добавлении и изменении компонентов в подсистеме хранения.
| Примечания. | Анализ узких мест | Диск | Шина | Адаптер | Шина PCI |
|---|---|---|---|---|---|
| Это конфигурация контроллера домена после добавления второго диска. Конфигурация диска представляет узкие места в 800 КБ/с. | Добавление 1 диска (Total=2) Операции ввода-вывода являются случайными Размер блока 4 КБ 10 000 RPM HD |
Общее число операций ввода-вывода в 200 Всего 800 КБ/с. |
|||
| После добавления 7 дисков конфигурация диска по-прежнему представляет узкие места в 3200 КБ/с. | Добавление 7 дисков (Total=8) Операции ввода-вывода являются случайными Размер блока 4 КБ 10 000 RPM HD |
Всего 800 операций ввода-вывода. Всего 3200 КБ/с |
|||
| После изменения ввода-вывода на последовательный сетевой адаптер становится узким местом, так как он ограничен 1000 операций ввода-вывода в секунду. | Добавление 7 дисков (Total=8) Последовательный ввод-вывод Размер блока 4 КБ 10 000 RPM HD |
2400 операций ввода-вывода в секунду можно считывать и записывать на диск, контроллер ограничен 1000 операций ввода-вывода в секунду | |||
| После замены сетевого адаптера адаптером SCSI, поддерживающим 10 000 операций ввода-вывода в секунду, узкие места возвращаются в конфигурацию диска. | Добавление 7 дисков (Total=8) Операции ввода-вывода являются случайными Размер блока 4 КБ 10 000 RPM HD Обновление адаптера SCSI (теперь поддерживает 10 000 операций ввода-вывода) |
Всего 800 операций ввода-вывода. Всего 3200 КБ/с |
|||
| После увеличения размера блока до 32 КБ шина становится узким местом, так как она поддерживает только 20 МБИТ/с. | Добавление 7 дисков (Total=8) Операции ввода-вывода являются случайными Размер блока 32 КБ 10 000 RPM HD |
Всего 800 операций ввода-вывода. 25 600 КБ/с (25 МБИТ/с) можно считывать и записывать на диск. Шина поддерживает только 20 МБИТ/с |
|||
| После обновления шины и добавления дополнительных дисков диск остается узким местом. | Добавление 13 дисков (Total=14) Добавление второго адаптера SCSI с 14 дисками Операции ввода-вывода являются случайными Размер блока 4 КБ 10 000 RPM HD Обновление до 320 МБИТ/с SCSI |
2800 I/Os 11 200 КБ/с (10,9 МБИТ/с) |
|||
| После изменения последовательного ввода-вывода диск остается узким местом. | Добавление 13 дисков (Total=14) Добавление второго адаптера SCSI с 14 дисками Последовательный ввод-вывод Размер блока 4 КБ 10 000 RPM HD Обновление до 320 МБИТ/с SCSI |
8400 I/Os 33600 КБ\s (32,8 МБ\с) |
|||
| После добавления более быстрых жестких дисков диск остается узким местом. | Добавление 13 дисков (Total=14) Добавление второго адаптера SCSI с 14 дисками Последовательный ввод-вывод Размер блока 4 КБ 15 000 RPM HD Обновление до 320 МБИТ/с SCSI |
14 000 I/Os 56 000 КБ/с (54,7 мб/с) |
|||
| После увеличения размера блока до 32 КБ шина PCI становится узким местом. | Добавление 13 дисков (Total=14) Добавление второго адаптера SCSI с 14 дисками Последовательный ввод-вывод Размер блока 32 КБ 15 000 RPM HD Обновление до 320 МБИТ/с SCSI |
14 000 I/Os 448 000 КБ/с (437 МБИТ/с) — это ограничение на чтение и запись в спинделе. Шина PCI поддерживает теоретические максимум 133 МБИТ/с (75 % эффективно в лучшем случае). |
Знакомство с RAID
При вводе контроллера массива в подсистему хранения он не значительно изменяет его характер. Контроллер массива заменяет только адаптер SCSI в вычислениях. Однако затраты на чтение и запись данных на диск при использовании различных уровней массива изменяются.
В RAID 0 запись данных распределяет их по всем дискам в наборе RAID. Во время операции чтения или записи система извлекает данные из каждого диска или отправляет их на каждый диск, увеличив объем данных, которые система может передавать в течение этого определенного периода времени. Таким образом, в этом примере мы используем 10 000 дисков RPM, используя RAID 0, позволит выполнять 100 операций ввода-вывода. Общее количество операций ввода-вывода, которое поддерживает система, составляет N spindles раз 100 1/O в секунду в спинделе, или N спиндели × 100 операций ввода-вывода в секунду в секунду на спиндел.

В RAID 1 система зеркально или дублирует данные в паре спинделей для избыточности. Когда система выполняет операцию чтения операций ввода-вывода, она может считывать данные из обоих спинделей в наборе. Это зеркальное отображение делает емкость ввода-вывода для обоих дисков доступными во время операции чтения. Однако RAID 1 не дает никаких преимуществ производительности операций записи, так как система также должна зеркально отображать записанные данные в паре спинделей. Хотя зеркальное отображение не делает операции записи занимает больше времени, система не может одновременно выполнять несколько операций чтения. Поэтому каждая операция ввода-вывода записи стоит две операции чтения операций ввода-вывода.
Следующее уравнение вычисляет количество операций ввода-вывода в этом сценарии:
Чтение операций ввода-вывода + 2 × записи общего объема доступных дисков ввода-вывода =
Если вы знаете соотношение операций чтения с записью и числом спинделей в развертывании, вы можете использовать это уравнение для вычисления количества операций ввода-вывода, которые может поддерживать ваш массив:
Максимальное количество операций ввода-вывода в секунду для каждого спинделя × 2 спинделей × [(% операций + чтения% операций записи) ÷ (% операций чтения + 2 × % операций записи)] = общее количество операций ввода-вывода в секунду
Сценарий, использующий RAID 1 и RAID 0, ведет себя точно так же, как RAID 1 в затратах на чтение и запись операций. Однако операции ввода-вывода теперь чередуются между каждым зеркальным набором. Это означает, что уравнение изменится на следующее:
Максимальное количество операций ввода-вывода в секунду на спинделя × 2 спинделя × [(% операций + чтения% операций записи) ÷ (% операций чтения + 2 × % записи)] = общее число операций ввода-вывода
В наборе RAID 1 при полосе N числа наборов RAID 1 общий объем операций ввода-вывода, который может обрабатываться, становится N × ввода-вывода для каждого набора RAID 1:
N × {Максимальное число операций ввода-вывода в секунду на спиндели × 2 спинделя × [(% операций + чтения% операций записи) ÷ (% операций чтения + 2 × % записи)]} = общее число операций ввода-вывода в секунду
Иногда мы вызываем RAID 5 N + 1 RAID, так как система чередует данные по n spindles и записывает сведения о четности в спиндел + 1. Однако RAID 5 использует больше ресурсов при выполнении операций ввода-вывода записи, чем RAID 1 или RAID 1 + 0. RAID 5 выполняет следующий процесс каждый раз, когда операционная система отправляет ввод-вывод записи в массив:
- Чтение старых данных.
- Прочтите старое четность.
- Запись новых данных.
- Напишите новый четность.
Каждый запрос ввода-вывода записи, отправляемый ОС контроллеру массива, требует завершения четырех операций ввода-вывода. Таким образом, запросы на запись RAID N + 1 занимают четыре раза до завершения операций ввода-вывода. Иными словами, чтобы определить, сколько запросов ввода-вывода из ОС преобразуется в количество запросов, которые получают спиндели, используйте это уравнение:
Чтение операций ввода-вывода + 4 × записи операций ввода-вывода в общей сложности операций ввода-вывода =
Аналогичным образом, в наборе RAID 1, где вы знаете соотношение операций чтения и операций записи и сколько спинделей есть, вы можете использовать это уравнение, чтобы определить, сколько операций ввода-вывода может поддерживать ваш массив:
Операций ввода-вывода в секунду на × (Spindles – 1) × [(% операций + чтения% операций записи) ÷ (% операций чтения + 4 × % записи)] = общее количество операций ввода-вывода в секунду
Примечание.
Результат предыдущего уравнения не включает диск, потерянный для четности.
Общие сведения о SAN
При внедрении сети зоны хранения (SAN) в среду она не влияет на принципы планирования, описанные в предыдущих разделах. Однако следует учитывать, что san может изменить поведение ввода-вывода для всех систем, подключенных к нему. Одним из основных преимуществ использования SAN является то, что она обеспечивает более избыточность во внутреннем или внешнем присоединенном хранилище, но это также означает, что планирование емкости должно учитывать потребности в отказоустойчивости. Кроме того, при вводе дополнительных компонентов в систему также необходимо учитывать эти новые части в вычислениях.
Теперь давайте разберем SAN на его компоненты:
- Жесткий диск SCSI или Fibre Channel
- Обратная планка канала единиц хранения
- Сами единицы хранения
- Модуль контроллера хранилища
- Один или несколько коммутаторов SAN
- Один или несколько адаптеров шины узла (HBA)
- Шина взаимодействия периферийных компонентов (PCI)
При разработке системы избыточности необходимо включить дополнительные компоненты, чтобы обеспечить работу системы во время кризиса, когда один или несколько исходных компонентов перестают работать. Однако при планировании емкости необходимо исключить избыточные компоненты из доступных ресурсов, чтобы получить точную оценку базовой емкости вашей системы, так как эти компоненты обычно не подключены, если не существует чрезвычайной ситуации. Например, если в san есть два модуля контроллера, необходимо использовать только один при вычислении общей доступной пропускной способности ввода-вывода, так как другой не будет включаться, если исходный модуль не перестанет работать. Кроме того, не следует включать избыточный коммутатор SAN, единицу хранения или спиндели в вычисления ввода-вывода.
Кроме того, так как планирование емкости учитывает только периоды пикового использования, вы не должны учитывать избыточные компоненты в доступных ресурсах. Пиковое использование не должно превышать 80 % насыщенности системы, чтобы обеспечить всплески или другое необычное поведение системы.
При анализе поведения жесткого диска SCSI или Fibre Channel необходимо проанализировать его в соответствии с принципами, описанными в предыдущих разделах. Несмотря на то, что каждый протокол имеет свои собственные преимущества и недостатки, главное, что ограничивает производительность на каждом диске, — это механические ограничения жесткого диска.
При анализе канала в единице хранения следует использовать тот же подход, который вы сделали при вычислении количества ресурсов, доступных на шине SCSI: разделите пропускную способность по размеру блока. Например, если единица хранения имеет шесть каналов, которые поддерживают максимальную скорость передачи 20 МБИТ/с, общий объем доступных операций ввода-вывода и передачи данных составляет 100 МБИТ/с. Причина 100 МБИТ/с вместо 120 МБИТ/с заключается в том, что общая пропускная способность канала хранилища не должна превышать объем пропускной способности, которую он будет использовать, если один из каналов внезапно отключился, оставив его только пять работоспособных каналов. Конечно, в этом примере также предполагается, что система равномерно распределяет нагрузку и отказоустойчивость по всем каналам.
Можно ли преобразовать предыдущий пример в профиль ввода-вывода в зависимости от поведения приложения. Для операций ввода-вывода в Active Directory максимальное значение составляет около 12500 операций ввода-вывода в секунду или 100 МБИТ/с ÷ 8 КБ на операции ввода-вывода.
Чтобы понять, сколько пропускной способности поддерживает модули контроллера, также необходимо получить их спецификации производителя. В этом примере san имеет два модуля контроллера, поддерживающие 7500 операций ввода-вывода. Если вы не используете избыточность, общая пропускная способность системы составит 15 000 операций ввода-вывода в секунду. Однако в сценарии, где требуется избыточность, вы вычисляете максимальную пропускную способность на основе ограничений только одного из контроллеров, что составляет 7500 операций ввода-вывода в секунду. Предположим, что размер блока составляет 4 КБ, это пороговое значение значительно ниже максимального значения 12500 операций ввода-вывода в секунду, что каналы хранения могут поддерживаться и поэтому является узким местом в анализе. Однако в целях планирования необходимо планировать максимальное число операций ввода-вывода в 10 400 операций ввода-вывода.
Когда данные покидают модуль контроллера, он передает подключение Fibre Channel, оцененное на 1 ГБИТ/с, или 128 МБИТ/с. Так как эта сумма превышает общую пропускную способность 100 МБИТ/с во всех каналах единиц хранения, она не будет узким местом в системе. Кроме того, поскольку эта передача находится только на одном из двух каналов Fibre Channel из-за избыточности, если одно подключение Fibre Channel перестает работать, оставшееся подключение по-прежнему имеет достаточно емкости для обработки спроса на передачу данных.
Затем данные передают переключатель SAN на свой путь к серверу. Переключатель ограничивает объем операций ввода-вывода, который может обрабатываться, так как он должен обработать входящий запрос, а затем перенаправить его на соответствующий порт. Однако вы можете только знать, какой предел переключения имеется, если вы посмотрите на спецификации производителя. Например, если в системе есть два коммутатора, и каждый коммутатор может обрабатывать 10 000 операций ввода-вывода в секунду, общая пропускная способность будет составлять 20 000 операций ввода-вывода в секунду. В зависимости от правил отказоустойчивости, если один коммутатор перестает работать, общая пропускная способность системы будет составлять 10 000 операций ввода-вывода в секунду. Поэтому в обычных условиях не следует использовать более 80 % использования или 8000 операций ввода-вывода.
Наконец, HBA, устанавливаемая на сервере, также ограничивает количество операций ввода-вывода, которые он может обрабатывать. Как правило, вы устанавливаете второй HBA для избыточности, но как и с коммутатором SAN, при вычислении количества операций ввода-вывода система может обрабатывать, общая пропускная способность будет составлять N - 1 HBA.
Рекомендации по кэшированию
Кэши являются одним из компонентов, которые могут значительно повлиять на общую производительность в любой точке системы хранения. Однако подробный анализ алгоритмов кэширования выходит за рамки этой статьи. Вместо этого мы предоставим вам краткий список вещей, которые следует знать о кэшировании в подсистемах дисков.
- Кэширование улучшает устойчивый последовательный ввод-вывод, так как он буферизирует множество небольших операций записи в большие блоки ввода-вывода. Он также отменяет операции хранения в нескольких больших блоках вместо многих крошечных. Эта оптимизация уменьшает общий объем операций случайного и последовательного ввода-вывода, что делает больше ресурсов доступными для других операций ввода-вывода.
- Кэширование не улучшает устойчивую пропускную способность ввода-вывода записи в подсистеме хранения, так как только буферы записываются, пока не будут доступны спиндели для фиксации данных. Когда все доступные ввода-вывода из спинделей перегружены данными в течение длительного периода времени, кэш в конечном итоге заполняется. Чтобы очистить кэш, необходимо предоставить достаточно операций ввода-вывода для очистки кэша, предоставляя дополнительные спиндели или предоставляя достаточно времени между всплесками для системы.
- Большие кэши позволяют буферировать больше данных, что означает, что кэш может обрабатывать более длительные периоды насыщенности.
- В типичных подсистемах хранения ОПЕРАЦИОННая система улучшает производительность записи с кэшами, так как система должна записывать данные только в кэш. Однако после того, как базовый носитель перегружен операциями ввода-вывода, кэш заполняет и записывает производительность до обычной скорости диска.
- При кэшировании операций ввода-вывода кэш наиболее полезен при хранении данных последовательно на столе и позволяет кэшу считываться заранее. Считывание вперед, когда кэш может немедленно перейти к следующему сектору, как если следующий сектор содержит данные, которые система будет запрашивать далее.
- При чтении операций ввода-вывода происходит случайно, кэширование на контроллере диска не увеличивает объем данных, которые диск может считывать. Если размер кэша на основе ОС или приложения больше размера аппаратного кэша, то любые попытки повысить скорость чтения диска не изменяют ничего.
- В Active Directory кэш ограничен только объемом ОЗУ, который хранится в системе.
Рекомендации по SSD
Твердотельные накопители (SSD) принципиально отличаются от жестких дисков на основе спинделя. Диски SSD могут обрабатывать более высокие объемы операций ввода-вывода с меньшей задержкой. Хотя диски SSD могут быть дорогими на основе затрат на Гигабайт, они очень дешевы с точки зрения затрат на операции ввода-вывода. Однако планирование емкости с помощью SSD включает в себя вопросы, которые вы бы спросили о спинделях: сколько операций ввода-вывода в секунду они могут обрабатывать и что такое задержка этих операций ввода-вывода в секунду?
Ниже приведены некоторые аспекты, которые следует учитывать при планировании SSD:
- Оба операций ввода-вывода в секунду и задержки относятся к конструкциям производителя. В некоторых случаях некоторые конструкции SSD могут работать хуже, чем технологии на основе спинделя. При попытке решить, следует ли использовать SSD или спиндели, следует проверить и проверить диск изготовителя по диску, а не предполагать, что все технологии работают определенным образом.
- Типы операций ввода-вывода в секунду могут иметь разные значения в зависимости от того, считываются ли они или записываются. Службы AD DS преимущественно основаны на чтении и поэтому менее влияют на технологию записи, которую вы используете для сравнения dto других сценариев приложений.
- Напишите выносливость является предположение, что клетки SSD имеют ограниченный срок жизни и в конечном итоге будут носить после их использования много. Для дисков базы данных профиль ввода-вывода преимущественно считывает выносливость ячеек до точки, когда вам не нужно беспокоиться о выносливости записи так много.
Итоги
Представьте себе хранилище как как крытый сантехника дома. Операции ввода-вывода в секунду носителя, в которые хранятся данные, похожи на основной поток дома. Когда основной слив получает забитый или ограничен размером или сворачиванием трубы, то сливы резервное копирование и не работают должным образом, когда домашний дом использует много воды. Этот сценарий похож на то, что общая среда имеет одну или несколько систем с общим хранилищем в одной сети SAN, NAS или iSCSI с одним и тем же базовым носителем. Так как спрос на пользователей превышает способность системы поддерживаться, производительность страдает.
Аналогичным образом, в нашем мнимом сценарии сантехники вы можете использовать различные подходы к устранению ошибок и других проблем с производительностью:
- Чтобы устранить свернутую трубу или слив, слишком малую, необходимо заменить трубы работой и правильной размерами. В общих условиях хранения это так же, как добавление нового оборудования или распространение использования в общих системах во всей инфраструктуре.
- Отмена засорения слива требует определения базовых проблем и их расположений, а затем удаления их с помощью соответствующего средства. Например, относительно простой слог в раковине кухни требуется только погружение или очистка очистки, чтобы удалить, в то время как более сложные заготовки, которые включают в себя захваченный объект, может потребовать сливной змеи. Аналогичным образом, в общей системе хранилища определение причины проблем с производительностью помогает определить, нужно ли создавать резервную копию на уровне системы, синхронизировать антивирусную проверку на всех серверах или синхронизировать программное обеспечение дефрагментации, которое выполняется во время пиковых периодов.
В большинстве конструкций сантехники несколько сливов питаются в основной слив. Когда слив получает забитый, вода попадает только в ловушку за точку, где находится журнал. Если соединение засоряется, то все стоки за этой точкой соединения перестают стекаться. В сценарии хранения соединение, получающее засорение, похоже на перегруженный коммутатор, проблему совместимости драйверов или несинхронизованные задачи программного обеспечения. Необходимо измерять размер операций ввода-вывода и операций ввода-вывода, чтобы определить, может ли ваша система хранения обрабатывать нагрузку, а затем настраивать систему по мере необходимости.
Приложение D. Устранение неполадок с хранилищем в средах, где больше ОЗУ не является вариантом
Многие рекомендации по хранилищу перед виртуализированным хранилищем служили двумя целями:
- Изоляция операций ввода-вывода, чтобы предотвратить проблемы с производительностью в спинделе ОС, чтобы повлиять на производительность профилей базы данных и операций ввода-вывода.
- Используя преимущества повышения производительности, которые жесткие диски и кэши на основе шпинделя могут дать вашей системе при использовании с последовательными файлами журналов AD DS. Изоляция последовательного ввода-вывода к отдельному физическому диску также может увеличить пропускную способность.
С новыми вариантами хранения гораздо более фундаментальные предположения, лежащие в основе более ранних рекомендаций по хранилищу, больше не соответствуют действительности. Сценарии виртуализированного хранилища, такие как iSCSI, SAN, NAS и файлы образов виртуальных дисков, часто используют базовые носители хранилища на нескольких узлах. Это различие отрицает предположения, что необходимо изолировать ввод-вывод и оптимизировать последовательный ввод-вывод. Теперь другие узлы, обращаюющиеся к общему носителю, могут снизить скорость реагирования на контроллер домена.
При планировании емкости для производительности хранилища следует учитывать три аспекта:
- Состояние холодного кэша
- Состояние теплого кэша
- Резервное копирование и восстановление
Состояние холодного кэша происходит при первоначальной перезагрузке контроллера домена или перезапуске службы Active Directory, поэтому в ОЗУ нет данных Active Directory. Состояние теплого кэша заключается в том, что контроллер домена работает в стабильном состоянии и кэшировал базу данных. С точки зрения производительности, потепление холодного кэша похоже на спринт, в то время как запуск сервера с полностью теплым кэшем похож на марафон. Определение этих состояний и различных профилей производительности, которые они используют, важно, так как их необходимо учитывать при оценке емкости. Например, так как достаточно ОЗУ для кэширования всей базы данных во время состояния теплого кэша не помогает оптимизировать производительность во время состояния холодного кэша.
В обоих сценариях кэша самое главное — как быстро хранилище может перемещать данные с диска в память. При теплом кэше производительность с течением времени улучшается при повторном использовании данных запросов, скорость попадания кэша увеличивается, а частота переходов на диск для получения данных уменьшается. В результате негативное влияние на производительность от необходимости переходить на диск также уменьшается. Любые снижения производительности являются временными и обычно удаляются, когда кэш достигает его теплого состояния, и максимальный размер системы позволяет.
Вы можете оценить, насколько быстро система может получать данные с диска, измеряя доступные операции ввода-вывода в секунду в Active Directory. Количество доступных операций ввода-вывода в секунду также зависит от количества операций ввода-вывода в секунду в базовом хранилище. С точки зрения планирования, так как потепление кэша и резервного копирования или восстановления состояния являются исключительными событиями, которые обычно происходят вне часов пиковой нагрузки и подвержены нагрузке контроллера домена, мы не можем дать общие рекомендации за пределами только ввода этих состояний в нерабочие часы.
В большинстве случаев AD DS преимущественно считывает операции ввода-вывода с соотношением 90 % считывания до 10 % записи. Чтение ввода-вывода является типичным узким местом для взаимодействия с пользователем, а запись ввода-вывода — это узкое место, которое снижает производительность записи. Кэши, как правило, обеспечивают минимальное преимущество для чтения операций ввода-вывода, так как операции ввода-вывода для файла NTDS.dit являются преимущественно случайными. Поэтому основной приоритет заключается в том, чтобы убедиться, что вы правильно настраиваете хранилище профилей ввода-вывода для чтения.
В обычных условиях эксплуатации цель планирования хранилища — свести к минимуму время ожидания, чтобы система возвращала запросы из AD DS на диск. Количество невыполненных операций ввода-вывода и ожидающих операций ввода-вывода должно быть меньше или равно количеству путей на диске. В сценариях мониторинга производительности обычно рекомендуется, чтобы LogicalDisk((<NTDS Database Drive>))\Avg Disk sec/Read счетчик был меньше 20 мс. Необходимо задать максимально низкое пороговое значение операционной системы в диапазоне от двух до шести миллисекундах в зависимости от типа хранилища.
На следующем графике показано измерение задержки диска в системе хранения.
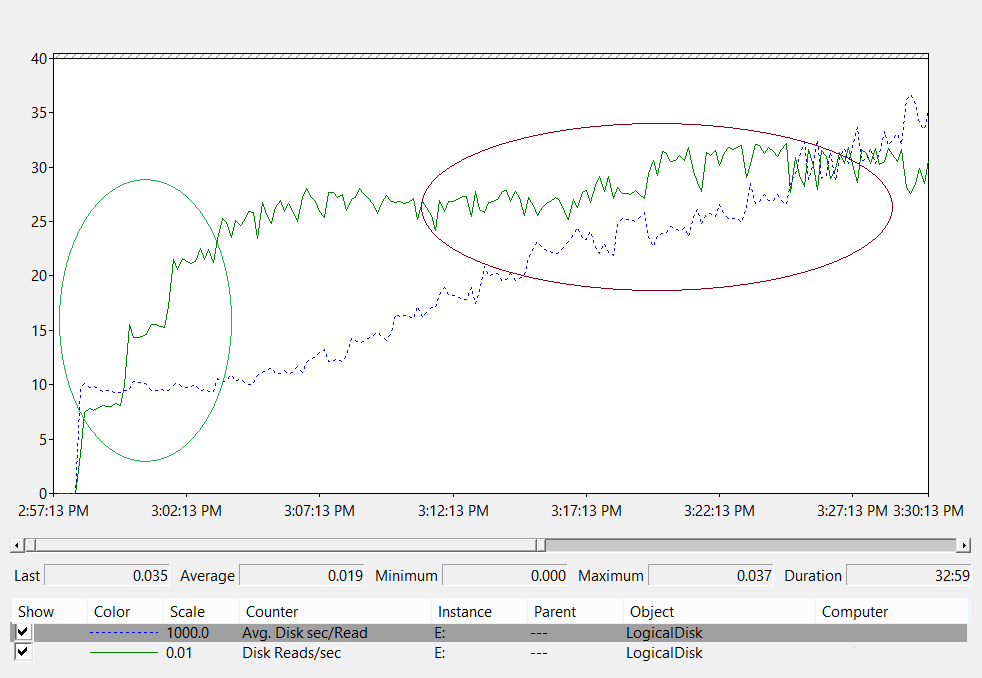
Давайте рассмотрим этот график строк:
- Область слева от диаграммы, обведенная зеленым цветом, показывает, что задержка согласована в 10 мс по мере увеличения нагрузки с 800 операций ввода-вывода в секунду до 2400 операций ввода-вывода в секунду. Эта область является базовым показателем того, как быстро базовое хранилище может обрабатывать запрос ввода-вывода. Однако этот базовый план зависит от используемого вами решения для хранения.
- Область справа от диаграммы, окружаемой в maroon, показывает системную пропускную способность между базовым и окончанием сбора данных. Сама пропускная способность не изменяется, но задержка увеличивается. В этой области показано, как запросы тратят больше времени на отправку в очередь подсистеме хранения, когда объемы запросов превышают физические ограничения базового хранилища.
Теперь давайте подумаем о том, что эти данные говорят нам.
Во-первых, предположим, что пользователю, запрашивающим членство в большой группе, требуется системное чтение 1 МБ данных с диска. Вы можете оценить необходимый объем операций ввода-вывода и время выполнения операций со следующими значениями:
- Размер каждой страницы базы данных Active Directory составляет 8 КБ.
- Минимальное количество страниц, необходимых системе для чтения, равно 128.
- Таким образом, в базовой области на схеме система должна занять не менее 1,28 секунд, чтобы загрузить данные с диска и вернуть его клиенту. На отметке 20 мс пропускная способность значительно превышает рекомендуемый максимум, процесс занимает 2,5 секунды.
На основе этих чисел можно вычислить, насколько быстро кэш будет нагреваться с помощью следующего уравнения:
2400 операций ввода-вывода в секунду × 8 КБ на операции ввода-вывода
После выполнения этого вычисления можно сказать, что скорость теплого кэша в этом сценарии составляет 20 МБИТ/с. Другими словами, система загружает около 1 ГБ базы данных в ОЗУ каждые 53 секунды.
Примечание.
Это нормально, чтобы увидеть задержку в течение коротких периодов, пока компоненты агрессивно считывают или записывают на диск. Например, задержка увеличивается при резервном копировании системы или в AD DS выполняется сборка мусора. Вы должны предоставить дополнительное место для этих периодических событий поверх исходных оценок использования. Ваша цель заключается в том, чтобы обеспечить достаточную пропускную способность для удовлетворения этих пиков, не влияя на общее функционирование.
Существует физическое ограничение на то, как быстро кэш нагревается в зависимости от того, как вы разрабатываете систему хранения. Единственное, что может разогреть кэш до скорости, которую может разместить базовое хранилище, — входящие запросы клиента. Выполнение скриптов для предварительного нагрева кэша во время пиковых часов конкурирует с реальными клиентскими запросами, увеличивает общую нагрузку, загружает данные, которые не относятся к клиентским запросам, и снижает производительность. Рекомендуется избегать использования искусственных мер для нагрева кэша.