Устранение неполадок с медленными запросами, затронутыми временем ожидания оптимизатора запросов
Применяется к: SQL Server
В этой статье описывается время ожидания оптимизатора, как это может повлиять на производительность запросов и как оптимизировать производительность.
Что такое время ожидания оптимизатора?
SQL Server использует оптимизатор запросов на основе затрат (QO). Дополнительные сведения о QO см . в руководстве по архитектуре обработки запросов. Оптимизатор запросов на основе затрат выбирает план выполнения запроса с наименьшей стоимостью после его создания и оценки нескольких планов запросов. Одной из целей оптимизатора запросов SQL Server является разумное время оптимизации запросов по сравнению с выполнением запроса. Оптимизация запроса должна быть гораздо быстрее, чем выполнение. Для достижения этого целевого объекта QO имеет встроенное пороговое значение задач, которые необходимо рассмотреть перед остановкой процесса оптимизации. Когда пороговое значение достигается до того, как QO рассмотрит все возможные планы, оно достигает предела времени ожидания оптимизатора. Событие timeout оптимизатора сообщается в плане запроса в качестве timeOut по причине раннего завершения оптимизации инструкций. Важно понимать, что это пороговое значение не основано на времени часов, а на количестве возможностей, рассмотренных оптимизатором. В текущих версиях QO SQL Server более полумиллиона задач рассматриваются до достижения времени ожидания.
Время ожидания оптимизатора предназначено для SQL Server, и во многих случаях это не является фактором, влияющим на производительность запросов. Однако в некоторых случаях выбор плана запроса SQL может негативно повлиять на время ожидания оптимизатора, и производительность запросов может привести к снижению производительности запросов. При возникновении таких проблем ознакомьтесь с механизмом времени ожидания оптимизатора и тем, как могут повлиять сложные запросы, которые помогут вам устранить неполадки и повысить скорость запроса.
Результат достижения порогового значения времени ожидания оптимизатора заключается в том, что SQL Server не рассмотрел весь набор возможностей для оптимизации. То есть это может пропустить планы, которые могут привести к более короткому времени выполнения. QO остановится на пороговом значении и рассмотрите план запросов по крайней мере затрат на этом этапе, даже если возможны лучшие варианты. Помните, что план, выбранный после достижения времени ожидания оптимизатора, может привести к разумной продолжительности выполнения запроса. Однако в некоторых случаях выбранный план может привести к выполнению запроса, который является неоптимальным.
Как определить время ожидания оптимизатора?
Ниже приведены симптомы, указывающие время ожидания оптимизатора:
Сложный запрос
У вас есть сложный запрос, который включает в себя множество присоединенных таблиц (например, восемь или более таблиц присоединяются).
Медленный запрос
Запрос может выполняться медленно или медленнее, чем он выполняется в другой версии ИЛИ системе SQL Server.
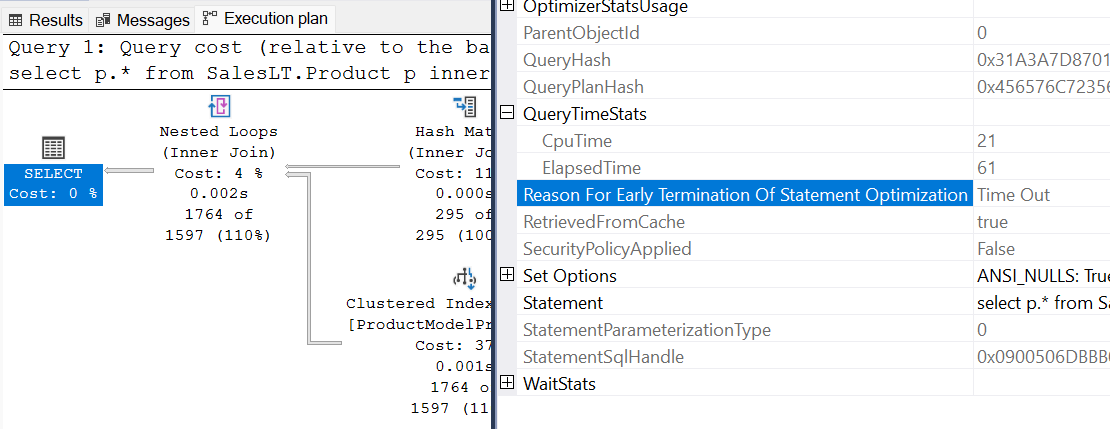
План запроса показывает ОператорOptmEarlyAbortReason=Timeout
План запроса отображается
StatementOptmEarlyAbortReason="TimeOut"в плане XML-запроса.<?xml version="1.0" encoding="utf-16"?> <ShowPlanXML xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" Version="1.518" Build="13.0.5201.2" xmlns="http://schemas.microsoft.com/sqlserver/2004/07/showplan"> <BatchSequence> <Batch> <Statements> <StmtSimple ..." StatementOptmLevel="FULL" StatementOptmEarlyAbortReason="TimeOut" ......> ... <Statements> <Batch> <BatchSequence>Проверьте свойства оператора плана слева в Microsoft SQL Server Management Studio. Вы можете увидеть значение причины раннего завершения оптимизации инструкций — TimeOut.
Что вызывает время ожидания оптимизатора?
Нет простого способа определить, какие условия могут привести к достижении или превышению порогового значения оптимизатора. Ниже приведены некоторые факторы, влияющие на количество планов, которые рассматриваются ВО при поиске лучшего плана.
В каком порядке должны быть присоединены таблицы?
Ниже приведен пример параметров выполнения трех табличных соединений (
Table1,Table2, ):Table3- Присоединение
Table1иTable2результат с помощьюTable3 - Присоединение
Table1иTable3результат с помощьюTable2 - Присоединение
Table2иTable3результат с помощьюTable1
Примечание. Чем больше число таблиц, тем больше возможностей.
- Присоединение
Какая структура доступа кучи или двоичное дерево (HoBT) используется для получения строк из таблицы?
- Кластеризованный индекс
- Некластеризованный индекс1
- Некластеризованный индекс2
- Кучи таблицы
Какой метод физического доступа следует использовать?
- Поиск в индексе
- Сканирование по индексу
- Сканирование таблиц
Какой оператор физического соединения следует использовать?
- Соединение вложенных циклов (NJ)
- Хэш-соединение (HJ)
- Объединение слиянием (MJ)
- Адаптивное соединение (начиная с SQL Server 2017 (14.x))
Дополнительные сведения см. в статье о соединениях.
Выполнение частей запроса параллельно или последовательно?
Дополнительные сведения см. в разделе "Параллельная обработка запросов".
В то время как следующие факторы сокращают количество рассмотренных методов доступа и, следовательно, возможные возможности:
- Предикаты запросов (фильтры в предложении
WHERE) - Существование ограничений
- Сочетания хорошо разработанных и актуальных статистических данных
Примечание. Тот факт, что QO достигает порогового значения, не означает, что он будет в конечном итоге более медленным запросом. В большинстве случаев запрос будет работать хорошо, но в некоторых случаях может возникнуть более медленное выполнение запроса.
Пример того, как учитываются факторы
Чтобы проиллюстрировать, давайте рассмотрим пример соединения между тремя таблицами (t1, t2и t3) и каждой таблицей с кластеризованным индексом и некластеризованным индексом.
Во-первых, рассмотрим типы физических соединений. Здесь участвуют два соединения. И, поскольку существует три возможности физического соединения (NJ, HJ и MJ), запрос может выполняться в 32 = 9 способов.
- NJ - NJ
- NJ - HJ
- NJ - MJ
- HJ - NJ
- HJ - HJ
- HJ - MJ
- MJ - NJ
- MJ - HJ
- MJ - MJ
Затем рассмотрим порядок соединения, который вычисляется с помощью permutations: P (n, r). Порядок первых двух таблиц не имеет значения, поэтому может быть P(3,1) = 3 возможности:
- Присоединение
t1кt2и затем с помощьюt3 - Присоединение
t1кt3и затем с помощьюt2 - Присоединение
t2кt3и затем с помощьюt1
Затем рассмотрим кластеризованные и некластеризованные индексы, которые можно использовать для извлечения данных. Кроме того, для каждого индекса у нас есть два метода доступа, поиск или сканирование. Это означает, что для каждой таблицы имеется 22 = 4 варианта. У нас есть три таблицы, поэтому можно выбрать 43 = 64.
Наконец, учитывая все эти условия, может быть 9*3*64 = 1728 возможных планов.
Теперь предположим, что в запросе есть n таблиц, а каждая таблица содержит кластеризованный индекс и некластеризованный индекс. Обратите внимание на следующие факторы:
- Заказы на присоединение: P(n-2) = n!/2
- Типы соединения: 3n-1
- Различные типы индексов с методами поиска и сканирования: 4n
Умножьте все эти выше, и мы можем получить количество возможных планов: 2*n!*12n-1. Если n = 4, число равно 82 944. Если n = 6, число равно 358 318 080. Таким образом, при увеличении числа таблиц, участвующих в запросе, число возможных планов увеличивается геометрически. Кроме того, если включить возможность параллелизма и других факторов, можно представить, сколько возможных планов будет рассматриваться. Таким образом, запрос с большим количеством соединений, скорее всего, достигнет порогового значения времени ожидания оптимизатора, чем один с меньшим количеством соединений.
Обратите внимание, что приведенные выше вычисления иллюстрируют худший сценарий. Как мы указали, существуют факторы, которые сокращают количество возможностей, таких как предикаты фильтров, статистика и ограничения. Например, предикат фильтра и обновленная статистика уменьшит количество методов физического доступа, так как это может быть более эффективным для использования поиска индекса, чем сканирование. Это также приведет к меньшему выбору соединений и т. д.
Почему отображается время ожидания оптимизатора с простым запросом?
Ничего с оптимизатором запросов просто. Существует множество возможных сценариев, и степень сложности настолько высока, что трудно понять все возможности. Оптимизатор запросов может динамически задать порог времени ожидания на основе стоимости плана, найденного на определенном этапе. Например, если обнаруживается относительно эффективный план, ограничение задачи для поиска лучшего плана может быть сокращено. Поэтому недооценная оценка кратности (CE) может быть одним из сценариев для достижения времени ожидания оптимизатора в начале. В этом случае основное внимание в расследовании уделяется CE. Это редкий случай по сравнению с сценарием выполнения сложного запроса, который обсуждается в предыдущем разделе, но это возможно.
Разрешения
Время ожидания оптимизатора, отображаемое в плане запроса, не обязательно означает, что это причина низкой производительности запросов. В большинстве случаев вам не нужно ничего делать об этой ситуации. План запроса, с которым SQL Server заканчивается, может быть разумным, и выполняемый запрос может выполняться хорошо. Возможно, вы никогда не знаете, что вы столкнулись со временем ожидания оптимизатора.
Выполните следующие действия, если вам нужно настроить и оптимизировать.
Шаг 1. Создание базового плана
Проверьте, можно ли выполнить тот же запрос с одинаковым набором данных в другой сборке SQL Server, используя другую конфигурацию CE или в другой системе (спецификации оборудования). Руководящий принцип настройки производительности — "нет проблем с производительностью без базовых показателей". Поэтому важно установить базовые показатели для того же запроса.
Шаг 2. Поиск скрытых условий, которые приводят к времени ожидания оптимизатора
Подробно изучите запрос, чтобы определить его сложность. При первоначальном рассмотрении может быть не очевидно, что запрос является сложным и включает в себя множество соединений. Распространенный сценарий заключается в том, что используются представления или функции с табличным значением. Например, на поверхности запрос может оказаться простым, так как он объединяет два представления. Но при проверке запросов внутри представлений можно обнаружить, что каждое представление присоединяется к семи таблицам. В результате при присоединении двух представлений вы в конечном итоге с 14-табличным соединением. Если запрос использует следующие объекты, выполните детализацию по каждому объекту, чтобы увидеть, как выглядят базовые запросы внутри него:
- Представления
- Функции с табличным значением (TFVs)
- Вложенные запросы или производные таблицы
- Распространенные табличные выражения (CTEs)
- Операторы UNION
Для всех этих сценариев наиболее распространенным решением будет переписать запрос и разбить его на несколько запросов. См . шаг 7. Уточнение запроса для получения дополнительных сведений.
Вложенные запросы или производные таблицы
Следующий запрос представляет собой пример, который объединяет два отдельных набора запросов (производных таблиц) с 4-5 соединениями в каждом. Однако после синтаксического анализа SQL Server он будет скомпилирован в один запрос с восемью таблицами, присоединенными к ним.
SELECT ...
FROM
( SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
WHERE ...
) AS derived_table1
INNER JOIN
( SELECT ...
FROM t5
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
WHERE ...
) AS derived_table2
ON derived_table1.Co1 = derived_table2.Co10
AND derived_table1.Co2 = derived_table2.Co20
Обобщенные табличные выражения
Использование нескольких распространенных выражений таблиц (CTEs) не является подходящим решением для упрощения запроса и предотвращения времени ожидания оптимизатора. Несколько ТСЗ повышают сложность запроса. Поэтому при решении времени ожидания оптимизатора оптимизатора используется контрпродуктивно. CTEs выглядят так, как логически прервать запрос, но они будут объединены в один запрос и оптимизированы как одно большое соединение таблиц.
Ниже приведен пример CTE, который будет скомпилирован в виде одного запроса с множеством соединений. Может показаться, что запрос к my_cte является двумя объектами простого соединения, но на самом деле в CTE присоединяются семь других таблиц.
WITH my_cte AS (
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
JOIN t5 ON ...
JOIN t6 ON ...
JOIN t7 ON ...
WHERE ... )
SELECT ...
FROM my_cte
JOIN t8 ON ...
Представления
Убедитесь, что вы проверили определения представления и получили все таблицы. Как и в производных таблицах, соединения могут быть скрыты внутри представлений. Например, соединение между двумя представлениями может в конечном итоге быть одним запросом с восемью таблицами:
CREATE VIEW V1 AS
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
WHERE ...
GO
CREATE VIEW V2 AS
SELECT ...
FROM t5
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
WHERE ...
GO
SELECT ...
FROM V1
JOIN V2 ON ...
Функции с табличным значением (TVFs)
Некоторые соединения могут быть скрыты внутри TFV. В следующем примере показано, что отображается как соединение между двумя TFV, а таблица может быть девятью таблицами.
CREATE FUNCTION tvf1() RETURNS TABLE
AS RETURN
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
WHERE ...
GO
CREATE FUNCTION tvf2() RETURNS TABLE
AS RETURN
SELECT ...
FROM t5
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
WHERE ...
GO
SELECT ...
FROM tvf1()
JOIN tvf2() ON ...
JOIN t9 ON ...
Объединение
Операторы объединения объединяют результаты нескольких запросов в один результирующий набор. Они также объединяют несколько запросов в один запрос. Затем вы можете получить один сложный запрос. В следующем примере будет указан один план запроса, который включает в себя 12 таблиц.
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
UNION ALL
SELECT ...
FROM t5
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
UNION ALL
SELECT ...
FROM t9
JOIN t10 ON ...
JOIN t11 ON ...
JOIN t12 ON ...
Шаг 3. Если у вас есть базовый запрос, который выполняется быстрее, используйте его план запроса.
Если определить, что определенный базовый план, полученный на шаге 1 , лучше всего подходит для запроса с помощью тестирования, используйте один из следующих параметров, чтобы принудительно выбрать этот план качества обслуживания:
- хранимая процедура хранилище запросов (QDS)
- Указание запроса: OPTION (USE PLAN N'XML_Plan<>')
- Руководства по планированию
Шаг 4. Уменьшение выбора планов
Чтобы уменьшить вероятность времени ожидания оптимизатора, попробуйте уменьшить возможности, которые необходимо учитывать при выборе плана. Этот процесс включает тестирование запроса с различными параметрами указания. Как и в большинстве решений с QO, выбор не всегда детерминирован на поверхности, потому что существует большое количество факторов, которые следует учитывать. Таким образом, существует не одна гарантированная успешная стратегия, и выбранный план может улучшить или уменьшить производительность выбранного запроса.
Принудительное применение порядка JOIN
Используется OPTION (FORCE ORDER) для устранения перемутации порядка:
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
OPTION (FORCE ORDER)
Сокращение возможностей JOIN
Если другие альтернативные варианты не помогли, попробуйте уменьшить сочетания планов запросов, ограничив варианты операторов физических соединений с указанием соединения. Например: OPTION (HASH JOIN, MERGE JOIN)OPTION (HASH JOIN, LOOP JOIN) или OPTION (MERGE JOIN).
Примечание. При использовании этих подсказок следует будьте осторожны.
В некоторых случаях ограничение оптимизатора с меньшим количеством вариантов соединения может привести к тому, что лучший вариант соединения недоступен и может на самом деле замедлить запрос. Кроме того, в некоторых случаях определенное соединение требуется оптимизатором (например, целью строки), и запрос может не создать план, если это соединение не является вариантом. Таким образом, после указания соединения для определенного запроса проверьте, есть ли сочетание, которое обеспечивает лучшую производительность и устраняет время ожидания оптимизатора.
Ниже приведены два примера использования таких подсказок:
Используйте
OPTION (HASH JOIN, LOOP JOIN)для разрешения только хэш-соединений и соединений циклов и избегайте объединения слиянием в запросе:SELECT ... FROM t1 JOIN t2 ON ... JOIN t3 ON ... JOIN t4 ON ... JOIN t5 ON ... OPTION (HASH JOIN, LOOP JOIN)Принудительное применение определенного соединения между двумя таблицами:
SELECT ... FROM t1 INNER MERGE JOIN t2 ON ... JOIN t3 ON ... JOIN t4 ON ... JOIN t5 ON ...
Шаг 5. Изменение конфигурации CE
Попробуйте изменить конфигурацию CE, переключившись между устаревшим CE и New CE. Изменение конфигурации CE может привести к выбору другого пути при вычислении и создании планов запросов SQL Server. Таким образом, даже если возникает проблема со временем ожидания оптимизатора, возможно, вы в конечном итоге будете иметь план, который выполняется более оптимально, чем выбранный с помощью альтернативной конфигурации CE. Дополнительные сведения см. в разделе "Как активировать лучший план запроса (оценка кратности)".
Шаг 6. Включение исправлений оптимизатора
Если вы не включили исправления оптимизатора запросов, попробуйте включить их с помощью одного из следующих двух методов:
- Уровень сервера: используйте флаг трассировки T4199.
- Уровень базы данных: использование
ALTER DATABASE SCOPED CONFIGURATION ..QUERY_OPTIMIZER_HOTFIXES = ONили изменение уровней совместимости базы данных для SQL Server 2016 и более поздних версий.
Исправления качества обслуживания могут привести к тому, что оптимизатор может получить другой путь в изучении плана. Поэтому он может выбрать более оптимальный план запроса. Дополнительные сведения см. в статье о модели обслуживания оптимизатора запросов SQL Server.
Шаг 7. Уточнение запроса
Рассмотрите возможность разбиения одного много табличного запроса на несколько отдельных запросов с помощью временных таблиц. Разбиение запроса — это всего лишь один из способов упрощения задачи для оптимизатора. См. следующий пример.
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
JOIN t5 ON ...
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
Чтобы оптимизировать запрос, попробуйте разбить один запрос на два запроса, вставив часть соединения в временную таблицу:
SELECT ...
INTO #temp1
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
GO
SELECT ...
FROM #temp1
JOIN t5 ON ...
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...