Устранение неполадок с очередью восстановления в группе доступности AlwaysOn
В этой статье приводятся решения проблем, связанных с очередью восстановления.
Что такое очередь восстановления?
Изменения, внесенные в первичную реплику в базе данных группы доступности, отправляются во все вторичные реплики, определенные в одной группе доступности. Когда эти изменения поступают во вторичные реплики, они сначала записываются в файл журнала транзакций базы данных группы доступности. Затем Microsoft SQL Server использует операцию восстановления или повтора для обновления файлов базы данных.
Если изменения в группе доступности прибывают и ужесточаются в файле журнала транзакций базы данных быстрее, чем их можно восстановить, формируется очередь восстановления. Эта очередь состоит из сохраненных транзакций журнала транзакций, которые не были восстановлены в базе данных.
Симптомы и эффект восстановления (повторная очередь)
Запросы первичных и вторичных реплик возвращают разные результаты
Рабочие нагрузки только для чтения, запрашивающие вторичные реплики, могут запрашивать устаревшие данные. Если происходит очередь восстановления, изменения данных базы данных первичной реплики могут не отражаться в базе данных-получателе при запросе одних и того же данных.
Хотя изменения приходят в базу данных-получатель и записываются в файл журнала базы данных, изменения не будут запрашиваться, пока они не будут восстановлены и восстановлены в файлы базы данных. Операция восстановления — это то, что делает эти изменения читаемыми.
Дополнительные сведения см . в разделе "Задержка данных во вторичной реплике " статьи "Различия между режимами доступности для группы доступности AlwaysOn".
Время отработки отказа больше или превышено значение RTO
Цель времени восстановления (RTO) — это максимальное время простоя базы данных, которую может обрабатывать организация. RTO также описывает, как быстро организация может восстановить доступ к базе данных после сбоя. Если в вторичной реплике присутствует существенная очередь восстановления при отработки отказа, восстановление может занять больше времени. После восстановления база данных перейдет к первичной роли и представляет состояние базы данных, которая существовала до отработки отказа. Более длительное время восстановления может отложить, как быстро рабочий процесс возобновляется после отработки отказа.
Очереди восстановления группы доступности различных диагностических функций
В случае очереди восстановления панель мониторинга AlwaysOn в SQL Server Management Studio (SSMS) может сообщить о неработоспособной группе доступности.
Как проверить очередь восстановления (повтор)
Очередь восстановления — это измерение для каждой базы данных, которое можно проверить с помощью панели мониторинга AlwaysOn на первичной реплике или с помощью sys.dm_hadr_database_replica_states динамического административного представления (DMV) на первичной или вторичной реплике. счетчики Монитор производительности проверяют скорость восстановления и очереди восстановления. Эти счетчики необходимо проверить на наличие вторичной реплики.
В следующих нескольких разделах содержатся методы для активного мониторинга очереди восстановления базы данных группы доступности.
Запрос sys.dm_hadr_database_replica_states
DmV sys.dm_hadr_database_replica_states сообщает строку для каждой базы данных группы доступности. Один столбец в отчете .redo_queue_size Это значение — размер очереди восстановления, измеряемый в килобайтах. Вы можете настроить запрос, похожий на следующий запрос, чтобы отслеживать любую тенденцию в размере очереди восстановления каждые 30 секунд. Запрос выполняется на первичной реплике. Он использует is_local=0 предикат для отчета о данных для вторичной реплики, где redo_queue_size и redo_rate являются релевантными.
WHILE 1=1
BEGIN
SELECT drcs.database_name, ars.role_desc, drs.redo_queue_size, drs.redo_rate,
ars.recovery_health_desc, ars.connected_state_desc, ars.operational_state_desc, ars.synchronization_health_desc, *
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.dm_hadr_database_replica_cluster_states drcs ON ars.replica_id=drcs.replica_id
JOIN sys.dm_hadr_database_replica_states drs ON drcs.group_database_id=drs.group_database_id
WHERE ars.role_desc='SECONDARY' AND drs.is_local=0
waitfor delay '00:00:30'
END
Вот как выглядит выходные данные.

Просмотр очереди восстановления на панели мониторинга AlwaysOn
Чтобы просмотреть очередь восстановления, выполните следующие действия.
Откройте панель мониторинга AlwaysOn в SSMS, щелкнув правой кнопкой мыши группу доступности в обозреватель объектов SSMS.
Выберите "Показать панель мониторинга".
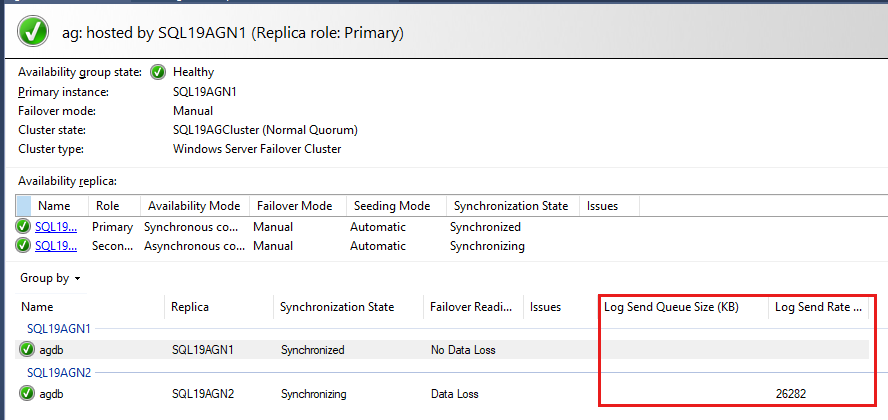
Базы данных группы доступности перечислены в последний раз, а в базах данных есть некоторые данные. Хотя размер очереди повтора (КБ) и частота повтора (КБ/с) не указаны по умолчанию, их можно добавить в это представление, как показано на снимке экрана на следующем шаге.
Чтобы добавить эти счетчики, щелкните правой кнопкой мыши заголовок над отчетами базы данных и выберите из списка доступных столбцов.
Чтобы добавить размер очереди Redo (КБ) и частоту повтора (КБ/с), щелкните правой кнопкой мыши заголовок, который показан красным цветом на следующем снимке экрана.
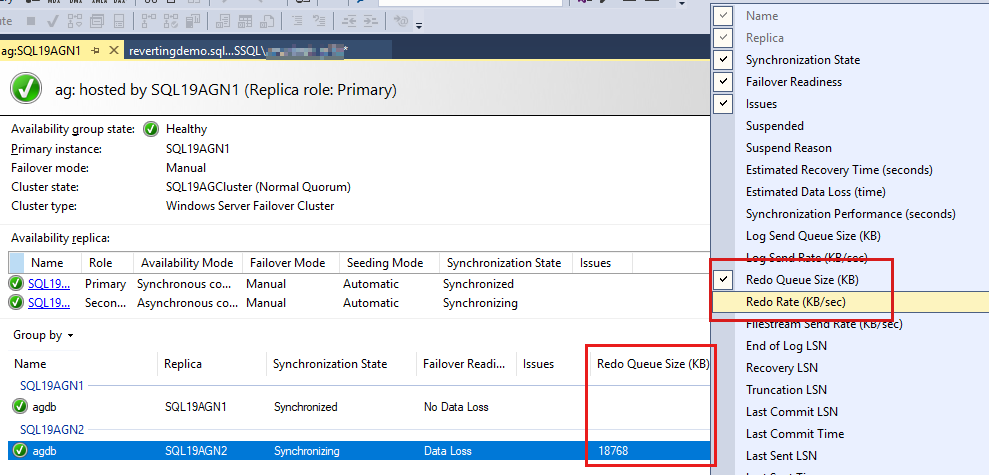
По умолчанию панель мониторинга AlwaysOn автоматически обновляет размер очереди Redo (КБ) и частоту повтора (КБ/с) каждые 60 секунд.


Просмотрите очередь восстановления в Монитор производительности
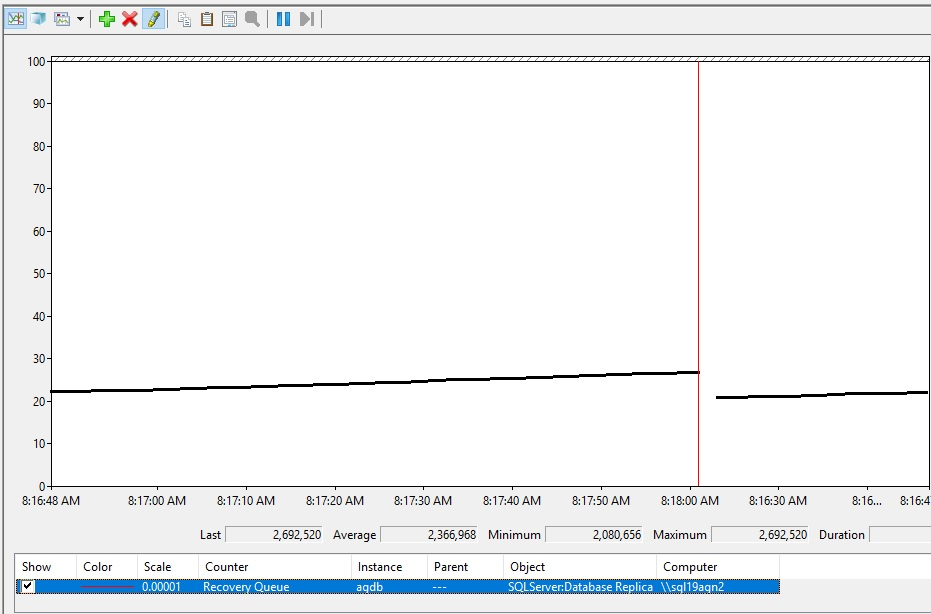
Размер очереди восстановления является уникальным для каждой вторичной реплики и базы данных. Таким образом, чтобы просмотреть очередь восстановления базы данных группы доступности, выполните следующие действия.
Откройте Монитор производительности на вторичной реплике.
Нажмите кнопку "Добавить (счетчик").
В разделе "Доступные счетчики" выберите sqlServer:Database Replica, а затем выберите очередь восстановления и счетчики повтора байт/с.
В списке экземпляров выберите базу данных группы доступности, которую требуется отслеживать для очереди восстановления.
Нажмите кнопку "Добавить>ОК".
Вот как может выглядеть увеличение очереди восстановления.

Интерпретация значений очередей восстановления
В этом разделе объясняется, как интерпретировать значения, связанные с очередью восстановления, определенной в предыдущем разделе.
Когда возникает проблема в очереди восстановления? Сколько очередей восстановления следует терпеть?
Предположим, что если очередь восстановления сообщает значение 0, это означает, что в момент выполнения этого отчета очередь восстановления не выполняется. Однако при занятой рабочей среде следует ожидать, что очередь восстановления часто сообщает о значении, отличном от нуля, даже в работоспособной среде AlwaysOn. Во время типичной рабочей среды следует ожидать, что это значение изменяется в диапазоне от 0 до ненулевых значений.
Если вы наблюдаете увеличение очереди восстановления с течением времени, то для дальнейшего изучения требуется. Это дополнительное действие указывает на то, что что-то изменилось. Если вы наблюдаете внезапный рост очереди восстановления, для устранения неполадок полезны следующие измерения:
- Частота повтора журнала (КБ/с) (панель мониторинга AlwaysOn)
- Redo_rate в sys.dm_hadr_database_replica_states dmV
Получение базовых ставок для частоты повтора
Во время работоспособной производительности AlwaysOn отслеживайте частоту повтора в базах данных группы доступности. Что они выглядят в течение обычно занятых рабочих часов? Каковы эти ставки в периоды обслуживания, когда большие транзакции (перестроение индексов, процессы ETL) управляют более высокой пропускной способностью транзакций в системе? Эти значения можно сравнить при наблюдении за ростом очереди восстановления, чтобы определить, что изменилось. Рабочая нагрузка может быть больше обычной. Если частота повтора ниже, для определения причины может потребоваться дальнейшее исследование.
Объемы рабочей нагрузки имеют значение
Если у вас есть большие рабочие нагрузки (например, инструкция UPDATE для одной миллиона строк, перестроение индекса в 1 терабайтовой таблице или даже пакет ETL, вставляющий миллионы строк), вы должны ожидать, что некоторые очереди восстановления будут расти сразу или с течением времени. Ожидается, что при внезапном внесении большого количества изменений в базу данных группы доступности.
Диагностика очередей восстановления (повторная версия)
После идентификации очереди восстановления для определенной базы данных группы доступности вторичной реплики подключитесь к вторичной реплике, а затем запросите sys.dm_exec_requests , чтобы определить wait_type потоки восстановления и wait_time для потоков восстановления. Ниже приведен запрос, который может выполняться в цикле. Вы ищете высокую частоту одного или нескольких типов ожидания и даже время ожидания для этих типов ожидания. Ниже приведен пример запроса, который выполняется каждую секунду и сообщает типы ожидания и время ожидания для группы доступности agdb:
WHILE (1=1)
BEGIN
SELECT db_name(database_id) AS dbname, command, session_id, database_id, wait_type, wait_time,
os.runnable_tasks_count, os.pending_disk_io_count FROM sys.dm_exec_requests der JOIN sys.dm_os_schedulers os
ON der.scheduler_id=os.scheduler_id
WHERE command IN('PARALLEL REDO HELP TASK', 'PARALLEL REDO TASK', 'DB STARTUP')
AND database_id= db_id('agdb')
waitfor delay '00:00:05.000'
END
Внимание
Для значимых выходных данных типа ожидания следует наблюдать увеличение очереди восстановления при использовании одного из методов, описанных ранее для отслеживания этого условия.
В этом примере сообщаются некоторые типы ожидания, связанные с вводом-выводом (PAGEIOLATCH_UP, PAGEIOATCH_EX). Чтобы проверить, продолжают ли эти типы ожидания иметь самые большие wait_times значения, как показано в следующем столбце.

Типы ожидания повтора SQL Server
При определении типа ожидания просмотрите следующую статью SQL Server 2016/2017: модель повторного повтора и производительность вторичной реплики группы доступности — Microsoft Tech Community в качестве перекрестной ссылки на распространенные типы ожидания, вызывающие очередь восстановления, и для устранения проблемы.
Заблокированные потоки повтора на вторичных серверах отчетов
Если решение направляет отчеты (запросы) к базам данных группы доступности на вторичной реплике, эти запросы только для чтения получают блокировки стабильности схемы (Sch-S). Эти блокировки Sch-S могут блокировать потоки повтора от получения блокировок изменения схемы (Sch-M) (также известных как "блокировки изменения схемы" или LCK_M_SCH_M) для внесения любых изменений языка определения данных (DDL), таких как ALTER TABLE или ALTER INDEX. Заблокированный поток повтора не может применять записи журнала до тех пор, пока он не разблокирован. Это может привести к очереди восстановления.
Чтобы проверить наличие исторических доказательств заблокированного повтора, откройте файлы трассировки Xevent AlwaysOn_health на вторичной реплике с помощью SSMS. lock_redo_blocked Найдите события.

Используйте Монитор производительности для активного мониторинга заблокированного влияния повторного входа в очередь восстановления. Добавьте счетчики SQL Server::D atabase Replica::Redo blocked/sec и SQL Server::D atabase Replica::Recovery Queue counters. На следующем снимком экрана показана ALTER TABLE ALTER COLUMN команда, которая выполняется в первичной реплике, пока длительный запрос выполняется в той же таблице на вторичной реплике. Счетчик повтора заблокирован/с указывает, что ALTER TABLE ALTER COLUMN выполняется команда. Хотя длительный запрос выполняется в той же таблице во вторичной реплике, все последующие изменения на первичной реплике вызывают увеличение очереди восстановления.

Отслеживайте тип ожидания изменения схемы, который поток повтора пытается получить. Для этого используйте запрос, описанный ранее, чтобы проверить типы ожидания, сообщаемые для операций sys.dm_exec_requestsповторного выполнения. Вы можете наблюдать за увеличением времени ожидания для LCK_M_SCH_M текущего блокировки повтора.

Однопотоковый повтор
SQL Server представил параллельное восстановление для баз данных-получателей реплик в Microsoft SQL Server 2016. Если при запуске SQL Server 2012 или Microsoft SQL Server 2014 возникает очередь восстановления, вы можете обновить ее до более поздней версии программы, чтобы повысить производительность повторного входа в рабочей среде.
Однопоточное повторение может выполняться даже в более поздних более сложных версиях SQL Server, в которых используется параллельная архитектура восстановления. В этих версиях экземпляр SQL Server может использовать до 100 потоков для параллельного повтора. В зависимости от количества процессоров и баз данных группы доступности параллельные потоки повтора выделяются не более 100 общих потоков. Если достигнуто ограничение повторного входа в 100 потоков, некоторые базы данных в группе доступности назначаются одному потоку повторного входа.
Чтобы определить, используется ли база данных группы доступности параллельное восстановление, подключитесь к вторичной реплике и используйте следующий запрос, чтобы определить количество строк (потоков), которые применяют восстановление для базы данных группы доступности. В следующем примере, если база данных agdb является одним потоком, а ее команда — DB STARTUPэто, рабочая нагрузка восстановления может воспользоваться параллельным восстановлением.
SELECT db_name(database_id) AS dbname, command, session_id, database_id, wait_type, wait_time,
os.runnable_tasks_count, os.pending_disk_io_count FROM sys.dm_exec_requests der JOIN sys.dm_os_schedulers os
ON der.scheduler_id=os.scheduler_id
WHERE command IN ('PARALLEL REDO HELP TASK', 'PARALLEL REDO TASK', 'DB STARTUP')
AND database_id= db_id('agdb')

Если вы убедитесь, что база данных использует однопоточный повтор, просмотрите алгоритм, описанный ранее, чтобы определить, превышает ли SQL Server число 100 рабочих потоков, выделенных для параллельного восстановления. Такое условие может быть причиной того, что база данных agdb использует только один поток для восстановления.
SQL Server 2022 теперь использует новый алгоритм параллельного восстановления, чтобы рабочие потоки были назначены для параллельного восстановления на основе рабочей нагрузки. Это устраняет вероятность того, что занятая база данных останется в однопоточном восстановлении. Дополнительные сведения см. в разделе "Использование потоков по группам доступности" статьи "Предварительные требования, ограничения и рекомендации для групп доступности AlwaysOn".