Устранение неполадок при отправке журналов в очереди в группе доступности AlwaysOn
В этой статье приводятся решения проблем, связанных с очередью отправки журналов.
Что такое очередь отправки журналов?
Изменения, внесенные в базу данных группы доступности на первичной реплике (напримерINSERTUPDATE, и DELETE) записываются в журнал транзакций и отправляются в вторичные реплики группы доступности. Очередь отправки журналов определяет количество записей журналов в файлах журнала базы данных-источника, которые не были отправлены в вторичные реплики.
Симптомы и влияние очереди отправки журналов
Очередь отправки журналов хранит все уязвимые данные
Если первичная реплика теряется в внезапной аварии и выполняется отработка отказа на вторичную реплику, в которой эти изменения еще не прибыли, эти изменения не будут отображаться в новой копии первичной реплики базы данных. Это исключает любые изменения, хранящиеся при выполнении полной резервной копии базы данных и журналов.
Растущая очередь отправки журналов приводит к растущему росту файла журнала транзакций
Для базы данных, определенной в группе доступности, Microsoft SQL Server должен храниться в первичной реплике всех транзакций в журнале транзакций, которые еще не были доставлены во вторичные реплики. Очередь отправки журнала представляет количество зарегистрированных изменений в первичной реплике, которая не может быть усечена во время обычных событий усечения журнала (например, во время резервного копирования журнала базы данных). Большая очередь отправки журналов может исчерпать свободное место на диске, в котором размещен файл журнала базы данных или может превышать настроенный максимальный размер файла журнала транзакций. Дополнительные сведения см. в статье об ошибке 9002 при большом размере журнала транзакций.
Различные диагностические функции, сообщающие о том, что журнал отправки журналов доступности групп доступности
Панель мониторинга AlwaysOn в sql Server Management Studio сообщает о очереди отправки журналов. Он может сообщить о том, что группа доступности неработоспособна.
Как проверить очередь отправки журналов
Очередь отправки журналов — это измерение для каждой базы данных. Это значение можно проверить с помощью панели мониторинга AlwaysOn на первичной реплике или с помощью sys.dm_hadr_database_replica_states динамических административных представлений (DMV) на первичной или вторичной реплике. счетчики Монитор производительности используются для проверки очереди отправки журналов на вторичную реплику.
В следующих нескольких разделах содержатся методы для активного мониторинга очереди отправки журнала базы данных группы доступности.
Запрос sys.dm_hadr_database_replica_state
DmV sys.dm_hadr_database_replica_states сообщает строку для каждой базы данных группы доступности. Один столбец в этом отчете.log_send_queue_size Это значение — размер очереди отправки журнала в килобайтах (КБ). Вы можете настроить запрос, например следующий запрос, чтобы отслеживать любую тенденцию в размере очереди отправки журнала. Запрос выполняется на первичной реплике. Он использует is_local=0 предикат для отчета о данных для вторичной реплики, где log_send_queue_size и log_send_rate являются релевантными.
WHILE 1=1
BEGIN
SELECT drcs.database_name, ars.role_desc, drs.log_send_queue_size, drs.log_send_rate,
ars.recovery_health_desc, ars.connected_state_desc, ars.operational_state_desc, ars.synchronization_health_desc, *
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.dm_hadr_database_replica_cluster_states drcs ON ars.replica_id=drcs.replica_id
JOIN sys.dm_hadr_database_replica_states drs ON drcs.group_database_id=drs.group_database_id
WHERE ars.role_desc='SECONDARY' AND drs.is_local=0
waitfor delay '00:00:30'
END
Эти выходные данные имеют следующий вид.

Просмотр очереди отправки журнала на панели мониторинга AlwaysOn
Чтобы просмотреть очередь отправки журнала, выполните следующие действия.
Откройте панель мониторинга AlwaysOn в SQL Server Management Studio (SSMS), щелкнув правой кнопкой мыши группу доступности в обозреватель объектов SSMS.
Выберите "Показать панель мониторинга".
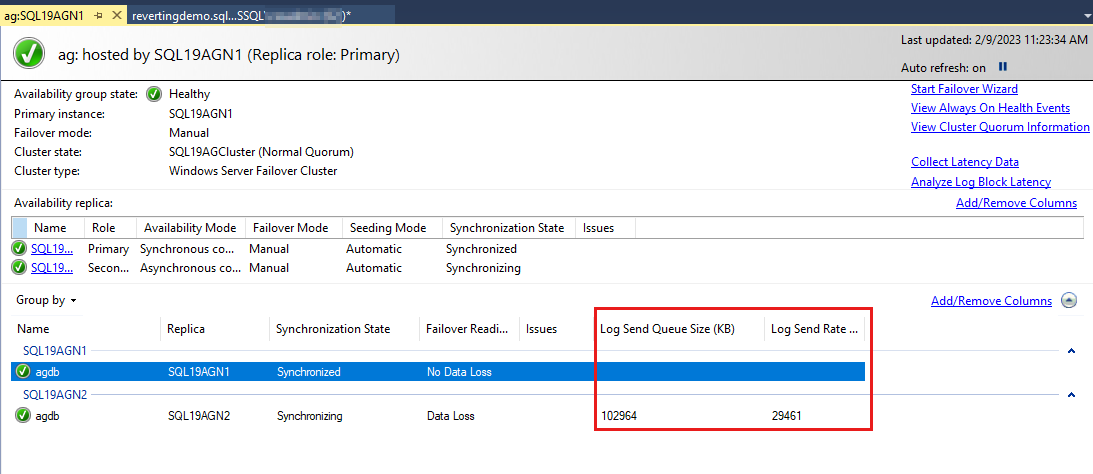
Базы данных группы доступности перечислены в последний раз, а в базах данных есть некоторые данные. Хотя размер очереди отправки журналов (КБ) и скорость отправки журналов (КБ/с) не указаны по умолчанию, их можно добавить в это представление, как показано на снимке экрана на следующем шаге.
Чтобы добавить эти столбцы, щелкните правой кнопкой мыши заголовок столбца базы данных группы доступности и выберите из списка доступных столбцов.
Чтобы добавить размер очереди отправки журналов, щелкните правой кнопкой мыши заголовок, который показан красным цветом на следующем снимке экрана.
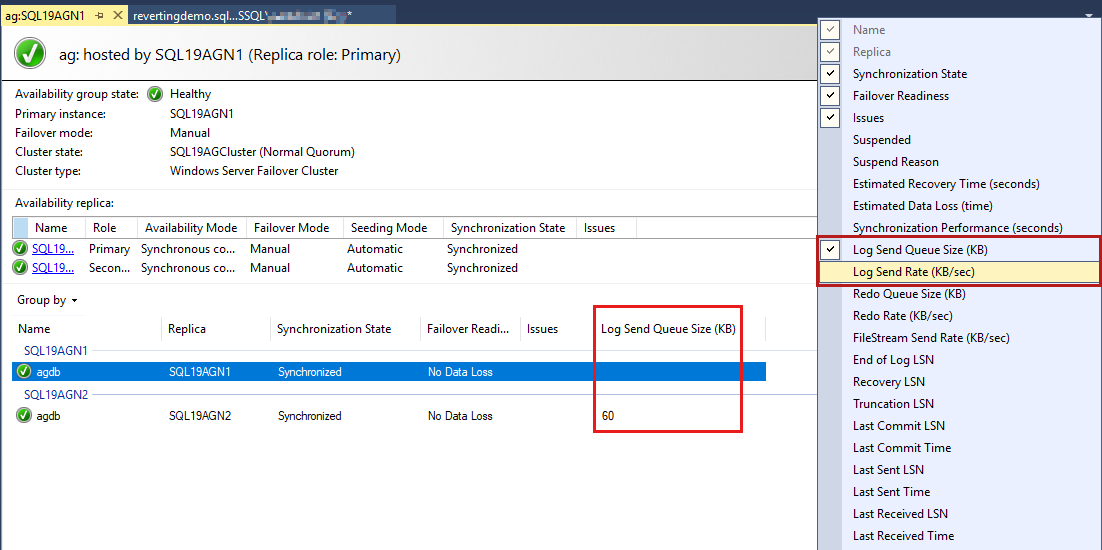
По умолчанию панель мониторинга AlwaysOn автоматически обновляет эти данные каждые 60 секунд.


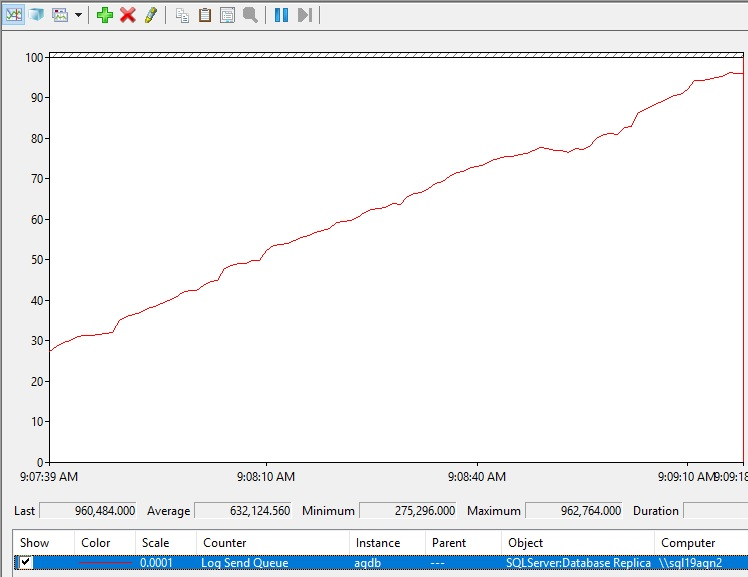
Просмотрите очередь отправки журналов в Монитор производительности
Очередь отправки журнала зависит от каждой базы данных-получателя реплики. Таким образом, чтобы просмотреть очередь отправки журнала базы данных группы доступности, выполните следующие действия.
Откройте Монитор производительности на вторичной реплике.
Нажмите кнопку "Добавить (счетчик").
В разделе "Доступные счетчики" выберите счетчики SQLServer:Database Replica и Log Send Queue.
В списке экземпляров выберите базу данных группы доступности, которую требуется проверить для очереди отправки журналов.
Нажмите кнопку "Добавить" и "ОК".
Вот как может выглядеть увеличение очереди отправки журналов.

Интерпретация значений очереди отправки журнала
В этом разделе объясняется, как интерпретировать значения размера очереди отправки журнала.
Когда происходит отправка журнала в очередь? Сколько сообщений о очереди отправки журналов должно быть разрешено?
Предположим, что если очередь отправки журнала сообщает значение 0, это означает, что очередь отправки журнала не выполняется во время этого отчета. Однако при занятой рабочей среде следует ожидать, что очередь отправки журналов часто сообщает о значении, отличном от нуля, даже в работоспособной среде AlwaysOn. Во время типичной рабочей среды следует ожидать, что это значение изменяется в диапазоне от 0 до ненулевых значений.
Если вы наблюдаете увеличение очереди отправки журналов с течением времени, то для дальнейшего исследования требуется выполнить дальнейшее исследование. Это дополнительное действие указывает на то, что что-то изменилось. Если вы наблюдаете внезапный рост очереди отправки журналов, для устранения неполадок полезны следующие измерения:
- Скорость отправки журналов (КБ/с) (панель мониторинга AlwaysOn)
- sys.dm_hadr_database_replica_states (DMV)
- Реплика базы данных::Зеркальные транзакции/с (Монитор производительности)
Получение базовых ставок для скорости отправки журналов и зеркальных транзакций/с
Во время работоспособной производительности AlwaysOn отслеживайте частоту отправки журналов и зеркальные транзакции/с для баз данных группы доступности. Что они выглядят в течение обычно занятых рабочих часов? Что они выглядят в периоды обслуживания, когда большие транзакции управляют более высокой пропускной способностью транзакций в системе? Эти значения можно сравнить при наблюдении за ростом очереди отправки журналов, чтобы определить, что изменилось. Рабочая нагрузка может быть больше обычной. Если скорость отправки журнала меньше обычной, для определения причин может потребоваться дальнейшее исследование.
Объемы рабочей нагрузки имеют значение
При наличии больших рабочих нагрузок (например UPDATE , инструкции с 1 миллионами строк, перестроение индекса в 1-терабайтовой таблице или даже пакет ETL, вставляющий миллионы строк), вы должны ожидать, что некоторый рост очереди отправки журналов выполняется немедленно или с течением времени. Ожидается, что при внезапном внесении большого количества изменений в базу данных группы доступности.
Диагностика очереди отправки журналов
После идентификации очереди отправки журналов для определенной базы данных группы доступности необходимо проверить наличие нескольких различных возможных первопричин проблемы, как описано в следующих разделах.
Внимание
Для получения значимых выходных данных типа ожидания проверьте увеличение очереди отправки журнала с помощью одного из методов, описанных в предыдущих разделах при отслеживании следующих условий.
Система слишком занята
Проверьте, перегружена ли рабочая нагрузка основной реплики ЦП системы. Если вы видите увеличение очереди отправки журнала, запросите sys.dm_os_schedulers dmV и отслеживайте его.high runnable_tasks_count Это число указывает на невыполненные задачи, которые выполнялись в то время.
SELECT scheduler_address, scheduler_id, cpu_id, status, current_tasks_count, runnable_tasks_count, current_workers_count, active_workers_count
FROM sys.dm_os_schedulers
В следующей таблице приведен пример результатов. Увеличение runnable_tasks_count значения означает, что большое количество задач ожидает времени ЦП.
| scheduler_address | scheduler_id | cpu_id | статус | current_tasks_count | runnable_tasks_count | current_workers_count | active_workers_count |
|---|---|---|---|---|---|---|---|
| 0x000002778D 200040 | 0 | 0 | ВИДИМЫЙ АВТОНОМНЫЙ РЕЖИМ | 1 | 0 | 2 | 1 |
| 0x000002778D 220040 | 1 | 1 | VISIBLE ONLINE | 108 | 12 | 115 | 107 |
| 0x000002778D 240040 | 2 | 2 | VISIBLE ONLINE | 113 | 2 | 123 | 113 |
| 0x000002778D 260040 | 3 | 3 | VISIBLE ONLINE | 105 | 11 | 116 | 105 |
| 0x000002778D 480040 | 4 | 4 | VISIBLE ONLINE | 108 | 15 | 117 | 108 |
| 0x000002778D 4A0040 | 5 | 5 | VISIBLE ONLINE | 100 | 25 | 110 | 99 |
| 0x000002778D 4C0040 | 6 | 6 | VISIBLE ONLINE | 105 | 23 | 113 | 105 |
| 0x000002778D 4E0040 | 7 | 7 | VISIBLE | 109 | 25 | 116 | 109 |
| 0x000002778D 700040 | 8 | 8 | VISIBLE ONLINE | 98 | 10 | 112 | 98 |
| 0x000002778D 720040 | 9 | 9 | VISIBLE ONLINE | 114 | 1 | 130 | 114 |
| 0x000002778D 740040 | 10 | 10 | VISIBLE ONLINE | 110 | 25 | 120 | 110 |
| 0x000002778D 760040 | 11 | 11 | VISIBLE ONLINE | 83 | 8 | 93 | 83 |
| 0x000002778D A00040 | 12 | 12 | VISIBLE ONLINE | 104 | 4 | 117 | 104 |
| 0x000002778D A20040 | 13 | 13 | VISIBLE ONLINE | 108 | 32 | 118 | 108 |
| 0x000002778D A40040 | 14 | 14 | VISIBLE ONLINE | 102 | 12 | 113 | 102 |
| 0x000002778D A60040 | 15 | 15 | VISIBLE ONLINE | 104 | 16 | 116 | 103 |
Решение. Если вы обнаружите высокий runnable_task_countуровень, уменьшите рабочую нагрузку в системе или увеличьте количество ЦП, доступных в системе.
Задержка в сети
Это условие особенно распространено, если вторичная реплика физически удалена от основной реплики. Группы доступности с несколькими сайтами позволяют клиентам развертывать копии бизнес-данных на нескольких сайтах для аварийного восстановления и создания отчетов. Это делает практически в реальном времени изменения, доступные для копий рабочих данных в удаленных расположениях.
Если вторичная реплика размещена далеко от первичной реплики, очередь отправки журналов может быть вызвана задержкой сети и неспособностью отправлять изменения в удаленную вторичную как быстро, так как они создаются в базе данных первичной реплики.
Внимание
SQL Server использует одно подключение для синхронизации изменений с первичной на вторичные реплики. Таким образом, если вторичная реплика удалена, ширина канала не повлияет на то, сколько данных SQL Server может отправлять. Вместо этого эта сумма больше зависит от задержки сети в канале (скорость подключения).
Проверка задержки сети
Проверка того, способствуют ли параметры управления потоками задержке сети
Группы доступности Microsoft SQL Server используют шлюзы управления потоками, чтобы избежать чрезмерного потребления сетевых ресурсов, памяти и других ресурсов во всех репликах доступности. Эти шлюзы управления потоками не влияют на состояние работоспособности синхронизации реплик доступности. Однако они могут повлиять на общую производительность баз данных доступности, включая RPO.
Более поздние версии SQL Server изменяют пороговые значения, при которых вводится элемент управления потоками. Это может помочь облегчить эффект управления потоком на симптомы, такие как очередь отправки журналов. Дополнительные сведения об управлении потоками и журнале изменений пороговых значений управления потоками см. в разделе "Шлюзы управления потоками".
Вы можете отслеживать управление потоками с помощью Монитор производительности для записи данных на первичной реплике. Чтобы отслеживать управление потоком базы данных, добавьте счетчики SQLServer:Database Replica и выберите счетчики "Задержка потока базы данных" и "Элементы управления потоками базы данных"/с . В диалоговом окне "Экземпляр" выберите базу данных группы доступности, которую требуется проверить для управления потоком базы данных. Чтобы обнаружить и отслеживать управление потоком реплики доступности, добавьте счетчики реплики доступности и выберите счетчики управления потоком (мс/с) и управления потоками/с.
Проверка того, способствует ли перезагрузка Windows с задержкой в сети
Проблемы с производительностью сети, которые вызывают очередь отправки журналов, могут быть активированы путем установки параметра "Перезапустить TCP", установленного в качестве значения True. Это был параметр по умолчанию в Windows Server 2016. Убедитесь, что перезагрузка окна перегрузки имеет значение False на серверах Windows, на которых размещаются реплики группы доступности, в которых наблюдается очередь отправки журналов.
PS C:\WINDOWS\system32> Get-NetTCPSetting | Select SettingName, CwndRestart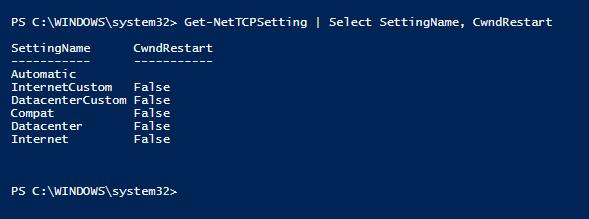
Дополнительные сведения о настройке свойства перезапуска Windows TCP на False см. в разделе Set-NetTCPSetting (NetTCPIP).
Дополнительные сведения о процессе синхронизации см. в разделе "Мониторинг производительности для групп доступности AlwaysOn". В этой статье также показано, как вычислить некоторые ключевые метрики и получить ссылки на некоторые распространенные сценарии устранения неполадок с производительностью.
Использование ping для получения примера задержки
В командной строке на узле 1 (первичная реплика), ping node2 (вторичная реплика):
C:\Users\customer>ping node2 Pinging node2.customer.corp.company.com [<ip address>] with 32 bytes of data: Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=94ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=97ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=94ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=119ms Ping statistics for 2<ip address>: Packets: Sent = 4, Received = 4, Lost = 0 (0% loss), Approximate round trip times in milli-seconds: Minimum = 94ms, Maximum = 119ms, Average = 101msТестирование пропускной способности сети от первичной до вторичной с помощью независимого средства
Используйте средство, например NTttcp, для независимого обнаружения пропускной способности сети между первичной и вторичной репликами с помощью одного подключения. Задержка в сети является распространенной причиной очереди отправки журналов. Ниже показано, как использовать независимое средство, например NTttcp, для измерения пропускной способности сети.
Внимание
SQL Server отправляет изменения из первичной реплики в вторичную реплику с помощью одного подключения. В следующем разделе мы настраиваем и запускаем NTttcp для использования одного подключения (таким же образом, как SQL Server) для точного сравнения пропускной способности.
Вы можете скачать NTttcp из Github — microsoft/ntttcp.
Чтобы запустить NTttcp, выполните следующие действия.
Скачайте и скопируйте средство на первичные и вторичные серверы SQL Server.
На сервере-получателе реплики откройте окно командной строки с повышенными привилегиями, измените каталог на папку средства NTttcp и выполните следующую команду:
ntttcp.exe -r -m 1,0,<secondaryipaddress>-a 16 -t 60Примечание.
В этой команде
<secondaryipaddress>заполнитель для фактического IP-адреса сервера-получателя реплики.На сервере первичной реплики откройте окно командной строки с повышенными привилегиями, измените каталог на папку средства NTttcp, а затем снова выполните следующую команду, указав фактический IP-адрес сервера вторичной реплики:
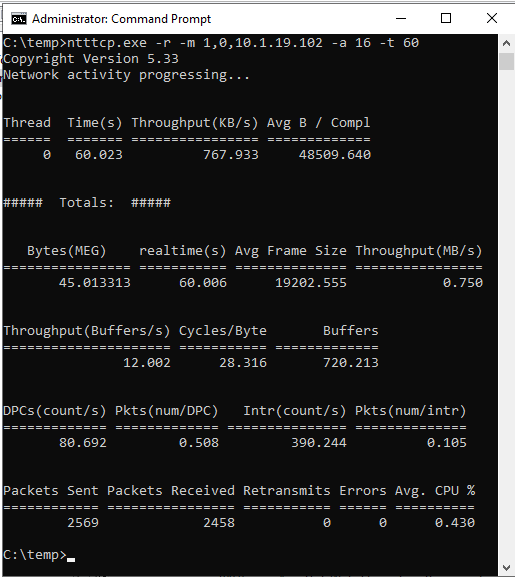
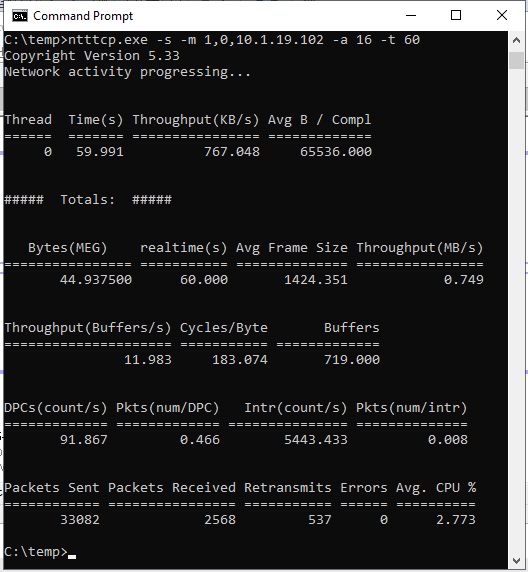
ntttcp.exe -s -m 1,0,<secondaryipaddress>-a 16 -t 60На следующих снимках экрана показаны NTttcp, работающие на вторичных и первичных репликах. Из-за задержки в сети средство может отправлять только 739 КБ/с данных. Это то, что вы можете ожидать, что SQL Server сможет отправлять.
NTttcp на вторичной реплике
NTttcp на первичной реплике
Проверка счетчиков Монитор производительности
Проверьте, какие отчеты NTttcp. Большая транзакция выполняется в SQL Server на первичной реплике. После запуска Монитор производительности на первичной реплике добавьте счетчик Network Interface::Bytes Sent/sec. Этот счетчик подтверждает, что первичная реплика может отправлять около 777 КБ/с данных. Это похоже на значение 739 КБ/с, которое сообщается тестом NTttcp.

Кроме того, полезно сравнить значение SQL Server::D atabases::Log Bytes Flushed/sec на первичной реплике с SQL Server::D atabase Replica::Log Bytes Received/sec для той же базы данных во вторичной реплике. В среднем мы наблюдаем около 20 МБ/с изменений, созданных в базе данных agdb. Однако в среднем вторичная реплика получает только 5,4 МБ изменений. Это приведет к тому, что очередь отправки журнала в первичной реплике невыполненных изменений в журнале транзакций базы данных, которая еще не была отправлена в вторичную реплику.
Запись в журнал байтов первичной реплики в секунду для базы данных agdb

Журнал вторичной реплики получен/с для группы доступности базы данных
