Устранение неполадок отработки отказа групп доступности AlwaysOn
Примечание.
Чтобы автоматизировать анализ вручную, описанный в этой статье, см. статью "Использование AGDiag для диагностики событий работоспособности группы доступности".
В этой статье приведены действия по устранению неполадок, которые помогут вам определить, почему отработка отказа группы доступности выполнена.
Последствия проблем со работоспособностью AlwaysOn или отработки отказа
AlwaysOn реализует надежный мониторинг работоспособности с помощью различных механизмов, чтобы обеспечить работоспособность экземпляра Microsoft SQL Server, на котором размещена основная реплика, базовый кластер и работоспособность системы. Рабочая нагрузка на рабочую нагрузку мгновенно прерывается при обнаружении проблемы с работоспособностью кластера Windows или AlwaysOn.
При обнаружении состояния работоспособности обычно происходит следующая последовательность событий. На протяжении всего этого средства устранения неполадок события работоспособности упоминаются в ссылке на следующие события:
Реплики групп доступности и базы данных переход с первичной роли на разрешение роли.
Базы данных группы доступности переходят в автономный режим и больше не доступны.
Кластер Windows помечает кластеризованный ресурс группы доступности как неудачный.
Кластер Windows пытается вернуть роль группы доступности в сети (в исходной или автоматической реплике партнера отработки отказа).
Роль группы доступности успешно подключена, если она обнаружена для работоспособности alwaysOn и мониторинга работоспособности кластера Windows.
В случае успешного выполнения реплики и базы данных группы доступности переходят на основную роль и базы данных группы доступности приходят в сеть и доступны приложению.
Приложения не могут получить доступ к базам данных группы доступности
При обнаружении состояния работоспособности реплика группы доступности и базы данных переходят на роль "Разрешение", а базы данных группы доступности выполняются в автономном режиме. После подключения реплики к первичной роли (на исходном сервере реплики или сервере реплики партнера отработки отказа) реплика и базы данных снова переходит в режим "в сети". Хотя реплика и базы данных разрешаются и находятся в автономном режиме, все приложения, которые пытаются получить доступ к этим базам данных группы доступности, завершаются ошибкой и создают сообщение об ошибке 983: Unable to access availability database... Эта ошибка также записывается в журнал ошибок Microsoft SQL Server, если SQL Server настроен на запись неудачных попыток входа:
Logon Error: 983, Severity: 14, State: 1.
Logon Unable to access availability database '<databasename>' because the database replica is not in the PRIMARY or SECONDARY role. Connections to an availability database is permitted only when the database replica is in the PRIMARY or SECONDARY role. Try the operation again later.
Период, в течение которого группа доступности находится в роли "Разрешение", прежде чем она возвращается в режим "в сети" в основной роли, обычно длится всего несколько секунд или даже менее секунды.
Определение и диагностика событий работоспособности группы доступности AlwaysOn или отработка отказа
1. Определение тенденций работоспособности AlwaysOn
Вы можете исследовать одно событие работоспособности AlwaysOn, или может возникнуть недавняя или продолжающаяся тенденция проблем со здоровьем, которые периодически прерывают рабочую среду. Следующие вопросы помогут сузить и сопоставить последние изменения в рабочей среде, которые могут быть связаны с этими проблемами работоспособности:
- Когда началось тенденция событий работоспособности alwaysOn или кластера?
- Происходят ли события работоспособности в определенный день?
- Происходят ли события работоспособности в определенное время дня?
- Происходят ли события работоспособности в определенный день или неделю месяца?
Если вы обнаружите тенденцию, проверьте запланированное обслуживание системы (хост-система в виртуальной среде), пакеты ETL и другие задания, которые могут сопоставить с этими событиями работоспособности. Если система является виртуальной машиной, изучите систему узла для изменений, которые, возможно, были введены во время сбоя.
Рассмотрим нерегламентированные рабочие нагрузки, которые могут соотноситься с временем проблем со работоспособностью (например, при первом входе пользователей в систему или после возвращения пользователей из обеда).
Примечание.
Это хорошее время, чтобы рассмотреть план сбора данных о производительности в течение недели и месяца. Чтобы лучше понять, когда система является самой загруженной, можно измерить счетчики монитора производительности Windows, такие как Processor Information::% Processor Time, Memory::Available MBytesи MSSQLServer:SQL Statistics::Batch Requests/sec.
2. Просмотр журнала кластера
Журнал кластера Windows — это самый полный журнал, используемый для определения типа события работоспособности AlwaysOn или кластера, а также обнаруженного состояния работоспособности, вызвавшего событие. Чтобы создать и открыть журнал кластера, выполните следующие действия.
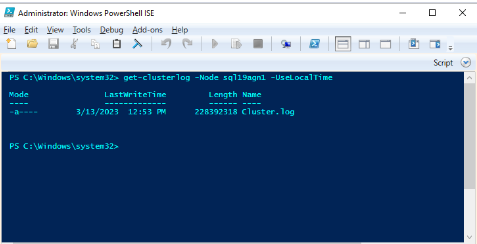
Используйте Windows PowerShell для создания журнала кластера Windows на узле кластера, на котором размещена первичная реплика во время события работоспособности. Например, выполните следующий командлет в окне PowerShell с повышенными привилегиями с помощью sql19agn1 в качестве имени сервера на основе SQL Server:
get-clusterlog -Node sql19agn1 -UseLocalTime
Примечание.
По умолчанию файл журнала создается в %WINDIR%\cluster\reports.
3. Поиск события работоспособности в журнале кластера
AlwaysOn использует несколько механизмов мониторинга работоспособности для мониторинга работоспособности группы доступности. Помимо события работоспособности кластера Windows (в котором кластер Windows обнаруживает проблему работоспособности между узлами кластера), AlwaysOn имеет четыре различных типа проверок работоспособности:
- Служба SQL Server не запущена
- Время ожидания аренды SQL Server
- Время ожидания проверки работоспособности SQL Server
- Внутренняя проблема работоспособности SQL Server
Вы можете найти любое из этих событий работоспособности AlwaysOn, выполнив поиск в журнале кластера для строки [hadrag] Resource Alive result 0. Эта строка сохраняется в журнале кластера при обнаружении любого из этих событий. Например:
00001334.00002ef4::2019/06/24-18:24:36.153 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
С помощью средства можно найти все события работоспособности в журнале кластера, чтобы создать сводный отчет о проблемах работоспособности AlwaysOn. Это может быть полезно для выявления хронологических тенденций и определения того, является ли конкретное условие работоспособности AlwaysOn повторяющимся. На следующем снимке экрана показано, как использовать текстовый редактор (NotePad++, в данном случае) для поиска всех строк в журнале кластера, содержащих [hadrag] Resource Alive result 0 строку:

Определение и устранение проблемы со работоспособностью, которая активировала отработку отказа
Чтобы определить проблемы работоспособности в журнале кластера основной реплики, сравните их с проблемами, описанными в следующих разделах. Ниже перечислены распространенные причины отработки отказа группы доступности:
- Событие работоспособности кластера
- Служба SQL Server отключена (событие работоспособности AlwaysOn)
- Время ожидания аренды (событие работоспособности AlwaysOn)
- Время ожидания проверки работоспособности (событие работоспособности AlwaysOn)
- Работоспособности SQL Server (событие работоспособности AlwaysOn)
События работоспособности кластера
Кластер Microsoft Windows отслеживает работоспособность серверов-членов в кластере. Если обнаружена проблема работоспособности, сервер-член кластера может быть удален из кластера. Кроме того, ресурсы кластера (включая роль группы доступности, размещенную на удаленном сервере-член кластера), будут перемещены в реплика партнера отработки отказа группы доступности, если она настроена для автоматической отработки отказа.
Симптомы
Ниже приведен пример события работоспособности кластера в журнале кластера. Чтобы найти его, можно искать Lost quorum или Cluster service has terminated из-за того, что во время изменения роли группы доступности или отработки отказа может присутствовать.
00000fe4.00001628::2022/12/15-14:26:02.654 WARN [QUORUM] Node 1: Lost quorum (1)
00000fe4.00001628::2022/12/15-14:26:02.654 WARN [QUORUM] Node 1: goingAway: 0, core.IsServiceShutdown: 0
00000fe4.00001628::2022/12/15-14:26:02.654 WARN lost quorum (status = 5925)
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [NETFT] Cluster Service preterminate succeeded.
00000fe4.00001628::2022/12/15-14:26:02.654 WARN lost quorum (status = 5925), executing OnStop
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [DM]: Shutting down, so unloading the cluster database.
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [DM] Shutting down, so unloading the cluster database (waitForLock: false).
000019cc.000019d0::2022/12/15-14:26:02.654 WARN [RHS] Cluster service has terminated. Cluster.Service.Running.Event got signaled.
Другим способом идентификации этого события является поиск в журнале событий системы Windows:
Critical SQL19AGN1.CSSSQL 1135 Microsoft-Windows-FailoverClusterin Node Mgr NT AUTHORITY\SYSTEM Cluster node 'SQL19AGN2' was removed from the active failover cluster membership. The Cluster service on this node may have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapters on this node. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Critical SQL19AGN1.CSSSQL 1177 Microsoft-Windows-FailoverClusterin Quorum Manager NT AUTHORITY\SYSTEM The Cluster service is shutting down because quorum was lost. This could be due to the loss of network connectivity between some or all nodes in the cluster, or a failover of the witness disk. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapter. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Диагностика события работоспособности кластера
Ошибки в журнале событий Windows (события 1135 и 1177) предполагают, что сетевое подключение является причиной события. Это наиболее распространенная причина обнаружения проблемы работоспособности кластера. В следующем примере показано, что другие серверы-члены кластера не могли взаимодействовать с этим сервером, на котором размещена первичная реплика группы доступности, и что эта проблема вызвала удаление узла кластера из кластера:
00000fe4.00001edc::2022/12/14-22:44:36.870 INFO [NODE] Node 1: New join with n3: stage: 'Attempt Initial Connection' status (10060) reason: 'Failed to connect to remote endpoint <endpoint address>'
00000fe4.00001620::2022/12/15-14:26:02.050 INFO [IM] got event: Remote endpoint <endpoint address> unreachable from <endpoint address>
00000fe4.00001620::2022/12/15-14:26:02.050 WARN [NDP] All routes for route (virtual) local <local address> to remote <remote address> are down
00000fe4.0000179c::2022/12/15-14:26:02.053 WARN [NODE] Node 1: Connection to Node 2 is broken. Reason GracefulClose(1226)' because of 'channel to remote endpoint <endpoint address> is closed'
Вы можете искать в журнале кластера доказательства сбоя подключения к узлу. В расположении в журнале кластера, где вы нашли Lost quorum, выполните поиск в обратном направлении для строк, таких как Failed to connect to remote endpoint, unreachableи is broken.
Решение
Убедитесь, что мониторинг работоспособности кластера подходит для среды узла. Дополнительные сведения о группах доступности SQL Server AlwaysOn, размещенных в Microsoft Azure, см. в обзоре отказоустойчивого кластера Windows Server — SQL Server на виртуальных машинах Azure.
Если это необходимо, обратитесь в службу поддержки высокого уровня доступности Microsoft Windows, чтобы открыть инцидент поддержки.
Служба SQL Server отключена: событие работоспособности AlwaysOn
Мониторинг работоспособности AlwaysOn может определить, не запущена ли служба SQL Server, на котором размещена первичная реплика группы доступности.
Симптомы
Ниже приведен пример отчета журнала кластера для роли группы доступности ag, которая указывает на сбой, так как QueryServiceStatusEx возвращает идентификатор 0процесса:
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] QueryServiceStatusEx returned a process id 0
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] SQL server service is not alive
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] Resource Alive result 0.
00001898.0000185c::2023/02/27-13:27:41.121 WARN [RHS] Resource ag IsAlive has indicated failure.
Диагностика событий завершения работы службы SQL
Проверьте журнал событий системы Windows и журнал ошибок SQL Server для неожиданного завершения работы SQL Server.
Если SQL Server был выключен системой или административным завершением работы, вы увидите следующую запись в журнале ошибок SQL Server:
2023-03-10 09:38:46.73 spid9s SQL Server is terminating in response to a 'stop' request from Service Control Manager. This is an informational message only. No user action is required.
В журнале событий системы Windows отображается следующая запись ошибки:
Information 3/10/2023 9:41:06 AM Service Control Manager 7036 None The SQL Server (MSSQLSERVER) service entered the stopped state.
В журнале событий системы Windows отображается следующая запись ошибки, если SQL Server неожиданно завершает работу:
Error 3/10/2023 8:37:46 AM Service Control Manager 7034 None The SQL Server (MSSQLSERVER) service terminated unexpectedly. It has done this 1 time(s).
Проверьте конец журнала ошибок SQL Server, чтобы найти подсказки. Если журнал ошибок резко заканчивается, это означает, что оно было завершено принудительно. Например, если SQL Server был завершен с помощью диспетчера задач, отчет об ошибке SQL Server не покажет никаких сведений о внутренних проблемах, которые могли вызвать завершение процесса.
Решение
Убедитесь, что авторизованные базы данных и системные администраторы имеют доступ к системе, чтобы свести к минимуму непредвиденные прерывания службы SQL Server. После изучения журналов событий изучите, почему служба должна быть неожиданно завершена.
Если внутренняя проблема работоспособности SQL Server вызвала неожиданное завершение SQL Server, в конце журнала ошибок SQL могут возникнуть подсказки о возможном неустранимом исключении (включая созданный файл диагностики дампа памяти). Просмотрите подсказки и выполните необходимые действия. Если вы найдете файл дампа, обратитесь в службу поддержки Microsoft SQL Server и укажите журнал ошибок SQL Server и содержимое файла дампа для дальнейшего изучения.
Время ожидания аренды: событие работоспособности AlwaysOn
AlwaysOn использует механизм аренды для мониторинга работоспособности компьютера, на котором установлен SQL Server. Время ожидания аренды по умолчанию — 20 секунд.
Симптомы
Ниже приведен пример выходных данных времени ожидания аренды AlwaysOn из журнала кластера. Эти строки можно искать, чтобы найти время ожидания аренды в журнале кластера.
00001a0c.00001c5c::2023/01/04-15:36:54.762 ERR [RES] SQL Server Availability Group : [hadrag] Availability Group lease is no longer valid
00001a0c.00001c5c::2023/01/04-15:36:54.762 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] Lease timeout detected, logging perf counter data collected so far
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:35:57.0, 98.068572, 509227008.000000, 0.000395, 0.000350 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:7.0, 12.314941, 451817472.000000, 0.000278, 0.000266 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:17.0, 17.270742, 416096256.000000, 0.000376, 0.000292 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:27.0, 38.399895, 416301056.000000, 0.000446, 0.000304 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:37.0, 100.000000, 417517568.000000, 0.001292, 0.000666
Дополнительные сведения об истечении времени ожидания аренды см . в разделе "Механизм аренды" в разделе "Механика" и "Рекомендации по аренде", кластеру и времени ожидания проверки работоспособности для групп доступности AlwaysOn.
Диагностика и разрешение событий времени ожидания аренды AlwaysOn
Существует два основных проблемы, которые могут активировать время ожидания аренды:
Дамп памяти SQL Server: когда SQL Server обнаруживает определенные внутренние события работоспособности, такие как нарушение доступа, утверждение или взаимоблокировка планировщика, он создает файл диагностического дампа (MDMP) в папке SQL Server \LOG . Процесс создания дампа памяти приостанавливает выполнение SQL Server на короткий период. В этом периоде механизм аренды может обнаружить отсутствие ответа на обслуживание и действие триггера. Дополнительные сведения см. в разделе "Влияние создания дампа".
Проблема с производительностью всей системы: время ожидания аренды не обязательно указывает на проблему работоспособности SQL Server. Вместо этого он может указывать на проблему работоспособности на уровне системы, которая также влияет на работоспособность сервера на основе SQL Server.
- Высокая загрузка ЦП в системе (около 100%).
- Условия вне памяти — низкая виртуальная память и /или один из процессов выстраиваются.
- WSFC идет в автономном режиме из-за потери кворума
- Регулирование виртуальной машины влияет на производительность и приводит к истечении срока действия аренды.
Решение
Подробные инструкции по устранению неполадок см. в MSSQLSERVER_19407. Ниже приведены два наиболее распространенных вопроса:
диагностика файла дампа сервера 1. SQL
SQL Server может обнаружить внутреннюю проблему работоспособности, например нарушение доступа, утверждение или взаимоблокированные планировщики. В этом случае программа создает мини-файл дампа (MDMP) в папке SQL Server \LOG процесса SQL Server для диагностики. Процесс SQL Server завис в течение нескольких секунд, пока мини-файл дампа записывается на диск. В это время все потоки в процессе SQL Server находятся в замороженном состоянии, который включает поток аренды, отслеживаемый мониторингом работоспособности AlwaysOn. Таким образом, AlwaysOn может обнаружить время ожидания аренды.
**Dump thread - spid = 0, EC = 0x0000000000000000
***Stack Dump being sent to C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\LOG\SQLDump0001.txt
* *******************************************************************************
*
* BEGIN STACK DUMP:
* 11/02/14 21:21:10 spid 1920
*
* Deadlocked Schedulers
*
* *******************************************************************************
* -------------------------------------------------------------------------------
* Short Stack Dump
Stack Signature for the dump is 0x00000000000002BA
Error: 19407, Severity: 16, State: 1.
The lease between availability group 'ag' and the Windows Server Failover Cluster has expired. A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster. To determine whether the availability group is failing over correctly, check the corresponding availability group resource in the Windows Server Failover Cluster.
Чтобы устранить эту проблему, необходимо проверить диагностику файла дампа памяти для первопричины. Обратитесь в службу поддержки Microsoft SQL Server, чтобы предоставить журнал ошибок SQL Server и содержимое файла дампа для дальнейшего изучения.
2. Высокая производительность ЦП или другая проблема с производительностью системы
Время ожидания аренды указывает на проблему производительности, которая влияет на всю систему, включая SQL Server. Чтобы диагностировать системную проблему, alwaysOn работоспособность диагностика сообщает данные монитора производительности в журнале кластера и включает событие времени ожидания аренды. Данные о производительности охватывают примерно 50 секунд, что приводит к событию времени ожидания аренды, отчетности об использовании ЦП, свободной памяти и задержке диска.
Ниже приведен пример сообщаемых данных о производительности, показывающих время ожидания аренды в журнале кластера. В этом примере выходных данных высокая общая загрузка ЦП, которая может быть связана с временем ожидания аренды.
00000f90.000015c0::2020/08/07-14:16:41.378 WARN [RES] SQL Server Availability Group: [hadrag] Lease timeout detected, logging perf counter data collected so far
00000f90.000015c0::2020/08/07-14:16:41.382 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:20.0, 83.266073, 31700828160.000000, 0.018094, 0.015752
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:30.0, 93.653224, 31697063936.000000, 0.038590, 0.026897
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:40.0, 94.270691, 31696265216.000000, 0.166000, 0.038962
00000f90.000015c0::2020/08/07-14:16:41.434 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:50.0, 90.272016, 31695409152.000000, 0.215141, 0.106084
00000f90.000015c0::2020/08/07-14:16:41.434 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:16:1.0, 99.991336, 31695892480.000000, 0.046983, 0.035440
Если данные о производительности показывают высокую загрузку ЦП, низкое состояние памяти или высокую задержку диска во время ожидания аренды, начните собирать данные Монитор производительности в течение полного дня на первичной реплике для изучения этих симптомов. Записывая данные монитора производительности за более длительный период, вы можете лучше определить базовые и пиковые значения этих ресурсов и отслеживать изменения в этих ресурсах при истечении времени ожидания аренды. При сборе этих данных рассмотрите наличие определенных запланированных или нерегламентированных рабочих нагрузок в SQL Server, которые коррелируют с временем этих проблем ресурсов и событий работоспособности.
Также следует записывать счетчики, которые сообщают об использовании системных ресурсов, в том числе следующие:
Processor Information::% Processor TimeMemory::Available MBytesLogical Disk::Avg. Disk sec/ReadLogical Disk::Avg. Disk sec/WriteLogical Disk::Avg. Disk Read Queue LengthLogical Disk::Avg. Disk Write Queue LengthMSSQLServer:SQL Statistics::Batch Requests/sec
Время ожидания проверки работоспособности: событие работоспособности AlwaysOn
AlwaysOn использует механизм проверки работоспособности для мониторинга работоспособности SQL Server и возможности подключения клиентских приложений.
Симптомы
При переходе реплики группы доступности в основную роль мониторинг работоспособности AlwaysOn устанавливает локальное подключение ODBC к экземпляру SQL Server. Хотя AlwaysOn подключен и мониторинг, если SQL Server не отвечает на подключение ODBC в течение периода, установленного для времени ожидания проверки работоспособности группы доступности (по умолчанию — 30 секунд), запускается событие времени ожидания проверки работоспособности. В этой ситуации группа доступности переходит с основной роли на роль "Разрешение" и инициирует отработку отказа, если она настроена для этого.
Дополнительные сведения о времени ожидания проверки работоспособности см. в разделе "Операция времени ожидания проверки работоспособности" в разделе "Механика и рекомендации по аренде, кластеру и времени ожидания проверки работоспособности для групп доступности AlwaysOn".
Ниже приведено время ожидания проверки работоспособности AlwaysOn, как указано в журнале кластера:
0000211c.00002d70::2021/02/24-02:50:01.890 WARN [RES] SQL Server Availability Group: [hadrag] Failed to retrieve data column. Return code -1
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <AG>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <AG>: [hadrag] Resource Alive result 0.
0000211c.00002594::2021/02/24-02:50:02.453 WARN [RHS] Resource AG IsAlive has indicated failure.
00001278.00002ed8::2021/02/24-02:50:02.453 INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'AG', gen(0) result 1/0.
Диагностика и разрешение события времени ожидания проверки работоспособности AlwaysOn
В следующем разделе показано, как просмотреть журналы SQL Server для событий хлеба, которые можно найти и сопоставить со временем ожидания проверки работоспособности AlwaysOn, обнаруженные и сообщаемые. Журналы, которые проверяются здесь, включают журнал кластера (где подтверждено время ожидания проверки работоспособности), system_health расширенные журналы событий и журналы ошибок SQL Server (как найденные в папке SQL Server \LOG ), так и журнал событий системы Windows. Используйте эти и другие журналы для поиска сопоставлений событий, которые могут помочь вам определить причину истечения времени ожидания проверки работоспособности.
1. Проверка наличия событий планировщика без получения
Время ожидания проверки работоспособности AlwaysOn часто вызывается событиями, не предоставляющимися в SQL Server. Когда SQL Server обнаруживает, что поток не предоставил планировщику, он сообщит о том, что произошло событие планировщика, не выполняющееся. Если вы видите другие задачи на том же планировщике, который не получает время ЦП, это основной признак неурожающего планировщика. Это может привести к задержке выполнения этих задач и "нехватке" рабочих нагрузок, назначенных определенному планировщику времени ЦП.
Чтобы проверить наличие событий планировщика без получения, выполните следующие действия.
Проверьте журналы расширенных событий SQL Server
system_health, чтобы определить, было ли событие планировщика, не возвращающееся планировщиком, в течение времени ожидания проверки работоспособности AlwaysOn. Неурожающие события, которые могут быть указаны ниже.scheduler_monitor_non_yielding_ring_buffer_recordedscheduler_monitor_non_yielding_iocp_ring_buffer_recordedscheduler_monitor_stalled_dispatcher_ring_buffer_recordedscheduler_monitor_non_yielding_rm_ring_buffer_recorded
Откройте журналы событий работоспособности системы SQL Server в основной реплике до времени ожидания проверки работоспособности.
В SQL Server Management Studio (SSMS) перейдите в раздел "Открыть файл>" и выберите "Объединить расширенные файлы событий".
Нажмите кнопку Добавить.
В диалоговом окне "Открыть файл" перейдите к файлам в каталоге SQL Server \LOG.
Нажмите и удерживайте элемент управления, а затем выберите файлы, имена которых начинаются с
system_health_xxx.xel.Нажмите кнопку "Открыть".>
Отфильтруйте результаты. Щелкните правой кнопкой мыши событие в столбце имени и выберите "Фильтр по этому значению".
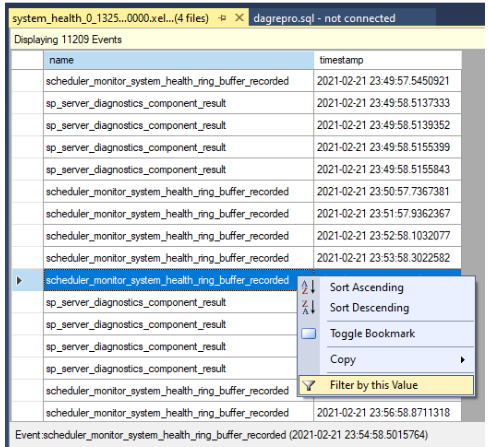
Определите фильтр для сортировки строк, в которых содержатся
yieldзначения в столбце имен, как показано на следующем снимке экрана. При этом возвращаются все виды событий, которые могут быть записаны вsystem_healthжурналах.
Сравните метки времени, чтобы узнать, были ли события, не возвращающие данные во время ожидания проверки работоспособности. Ниже приведено время ожидания проверки работоспособности, как указано в журнале кластера:
0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost 0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group < SQL19AGN1>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel 0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group < SQL19AGN1: [hadrag] Resource Alive result 0.Вы можете увидеть, что в момент истечения времени ожидания проверки работоспособности произошли неопродавляющие события.
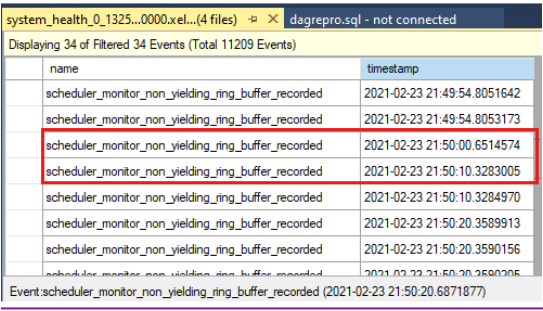
Если обнаружены события, не являющиеся результатом, проверьте причину события, не возвращающегося. Обратитесь в службу поддержки SQL Server, чтобы изучить события, не являющиеся источником.
2. Проверьте журнал ошибок SQL Server
Проверьте журнал ошибок SQL Server для сопоставления событий во время ожидания проверки работоспособности. Эти события могут предоставлять "хлебные крошки", которые предлагают дальнейшие шаги по области первопричины времени ожидания проверки работоспособности.
Например, в следующей записи журнала показано, что время ожидания проверки работоспособности произошло в журнале кластера:
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <SQL19AGN1>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <SQL19AGN1>: [hadrag] Resource Alive result 0.
В журнале ошибок SQL Server в течение нескольких секунд после истечения времени ожидания проверки работоспособности SQL Server сообщает, что она обнаружила серьезную задержку ввода-вывода:
2021-02-23 20:49:54.64 spid12s SQL Server has encountered 1 occurrence(s) of I/O requests taking longer than 15 seconds to complete on file [C:\Program Files\Microsoft SQL Server\MSSQL15.MSSQLSERVER\MSSQL\DATA\agdb_log.ldf] in database id 12. The OS file handle is 0x0000000000001594. The offset of the latest long I/O is: 0x000030435b0000. The duration of the long I/O is: 26728 ms.
Просмотрите журнал событий системы, чтобы получить возможные системные подсказки, которые могут быть связаны с событием времени ожидания проверки работоспособности. При просмотре журнала событий системы Windows может возникнуть проблема ввода-вывода, сообщаемая одновременно с тем же временем проверки работоспособности:
02/23/2021,08:50:16 PM,Warning,SQL19AGN1.CSSSQL.local.local,<...>,"Reset to device, \Device\<device ID>, was issued."
02/23/2021,08:50:16 PM,Warning,SQL19AGN1.CSSSQL.local.local,<...>,"The IO operation at logical block address <block address> for Disk 6 (PDO name: \Device\<device ID>) was retried."
Работоспособности SQL Server: событие работоспособности AlwaysOn
AlwaysOn отслеживает различные виды событий работоспособности SQL Server. Хотя она размещает первичную реплику группы доступности, SQL Server непрерывно выполняет sp_server_диагностика, которые сообщают о работоспособности SQL Server с помощью различных компонентов. При обнаружении sp_server_diagnostics проблем со работоспособностью сообщает об ошибке для этого конкретного компонента, а затем отправляет результаты обратно в процесс обнаружения работоспособности AlwaysOn. Когда сообщается об ошибке, роль группы доступности отображает состояние сбоя и возможную отработку отказа, если группа доступности настроена для этого.
Симптомы
Ниже приведен пример проблемы работоспособности SQL Server, как показано sp_server_diagnostics в журнале кластера. SQL Server сообщает о состоянии ошибки в системном компоненте в мониторинг работоспособности AlwaysOn, а группа доступности contoso-ag переходит в состояние сбоя.
Примечание.
Проблема работоспособности SQL Server создает аналогичный отчет о времени ожидания проверки работоспособности. Оба отчета о Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevelсобытиях работоспособности. Различие для события работоспособности SQL Server заключается в том, что он сообщает, что компонент SQL Server изменился с "предупреждения" на "error".
INFO [RES] SQL Server Availability Group: [hadrag] SQL Server component 'system' health state has been changed from 'warning' to 'error' at 2019-06-20 15:05:52.330
ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, the state of system component is error
ERR [RES] SQL Server Availability Group <contoso-ag>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
ERR [RES] SQL Server Availability Group <contoso-ag>: [hadrag] Resource Alive result 0.
ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, the state of system component is error
WARN [RHS] Resource contoso-ag IsAlive has indicated failure.
INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'contoso-ag', gen(0) result 1/0.
Диагностика событий работоспособности SQL Server
Тип проблемы работоспособности, сообщаемой службой работоспособности SQL Server, должен диктовать направление анализа первопричин.
По умолчанию при развертывании группы FAILURE_CONDITION_LEVEL доступности устанавливается как три. Это активирует мониторинг некоторых, но не всех профилей работоспособности SQL Server. На уровне по умолчанию AlwaysOn активирует событие работоспособности, когда SQL Server создает слишком много файлов дампа, нарушение доступа к записи или потерянный спинлок. Установка группы доступности до четырех или пяти уровней расширит типы отслеживаемых проблем работоспособности SQL Server. Дополнительные сведения о мониторах AlwaysOn работоспособности SQL Server см. в статье Настройка гибкой политики автоматической отработки отказа для группы доступности — SQL Server AlwaysOn.
Чтобы определить конкретную проблему работоспособности AlwaysOn, выполните следующие действия.
Откройте журналы расширенных событий диагностики кластера SQL Server на первичной реплике до момента возникновения предполагаемого события работоспособности SQL Server.
В SSMS перейдите в раздел "Открыть файл>", а затем выберите "Объединить расширенные файлы событий".
Выберите Добавить.
В диалоговом окне "Открыть файл" перейдите к файлам в каталоге SQL Server \LOG.
Нажмите клавишу CONTROL, выберите файлы, имена которых совпадают
<servername>_<instance>_SQLDIAG_xxx.xel, а затем нажмите кнопку "Открыть>ОК".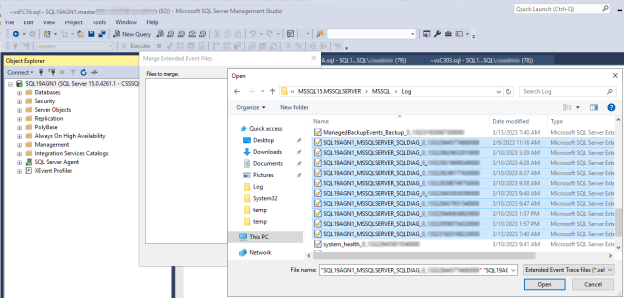
В SSMS появится новое окно с вкладками, включающее расширенные события, как показано на следующем снимке экрана.
Чтобы изучить проблему работоспособности SQL Server, найдите
component_health_resultзначение которогоstate_descимеет значениеerror. Ниже приведен пример события системного компонента, которое сообщило об ошибке в мониторинг работоспособности AlwaysOn: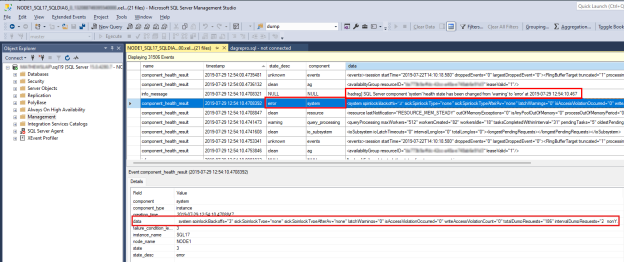
Дважды щелкните столбец данных в нижней области. Откроется подробные данные компонента в новой области окна SSMS для проверки. Вот как выглядят данные системного компонента:

Обратите внимание, что данные totalDumprequests=186 указывают, что на этом СЕРВЕРе SQL Server было создано слишком много событий диагностики файла дампа. Это причина, по которой системный компонент сообщил о состоянии ошибки. Когда мониторинг работоспособности AlwaysOn получает это состояние ошибки, он активирует событие работоспособности группы доступности. Кроме того, можно убедиться, что нарушения доступа к записи или потерянные спин-блокировки не обнаружены из данных, предоставленных в данных системного компонента.



Решение
В зависимости от типа обнаруженной проблемы необходимо соответствующим образом решить эту проблему. Как описано в статье "Настройка гибкой политики автоматической отработки отказа для группы доступности " SQL Server AlwaysOn ", могут возникнуть различные проблемы, которые приводят к этому. Вот некоторые примеры.
- Служба SQL Server отключена.
- Время ожидания аренды.
- Реплика доступности находится в неисправном состоянии.
- Дампы памяти, созданные потерянными спинблоками, нарушениями доступа или слишком большим количеством дампов памяти, созданных в течение короткого периода времени.
- Постоянное состояние вне памяти в внутреннем пуле ресурсов SQL Server.
- Обнаружение взаимоблокировки планировщика.
- Обнаружение неразрешимой взаимоблокировки.
Если это необходимо, обратитесь в службу поддержки SQL Server, чтобы открыть инцидент поддержки, чтобы получить дополнительную помощь в поиске первопричины этих внутренних проблем работоспособности SQL Server