Оптимизация разностных таблиц
Spark — это платформа параллельной обработки с данными, хранящимися на одном или нескольких рабочих узлах. Кроме того, файлы Parquet неизменяемы, с новыми файлами, написанными для каждого обновления или удаления. Этот процесс может привести к хранению данных Spark в большом количестве небольших файлов, известных как проблема с небольшими файлами. Это означает, что запросы на большие объемы данных могут выполняться медленно или даже не завершаются.
Функция OptimizeWrite
OptimizeWrite — это функция Delta Lake, которая уменьшает количество файлов по мере их записи. Вместо записи большого количества небольших файлов он записывает меньше больших файлов. Это помогает предотвратить проблему с небольшими файлами и убедиться, что производительность не снижается.
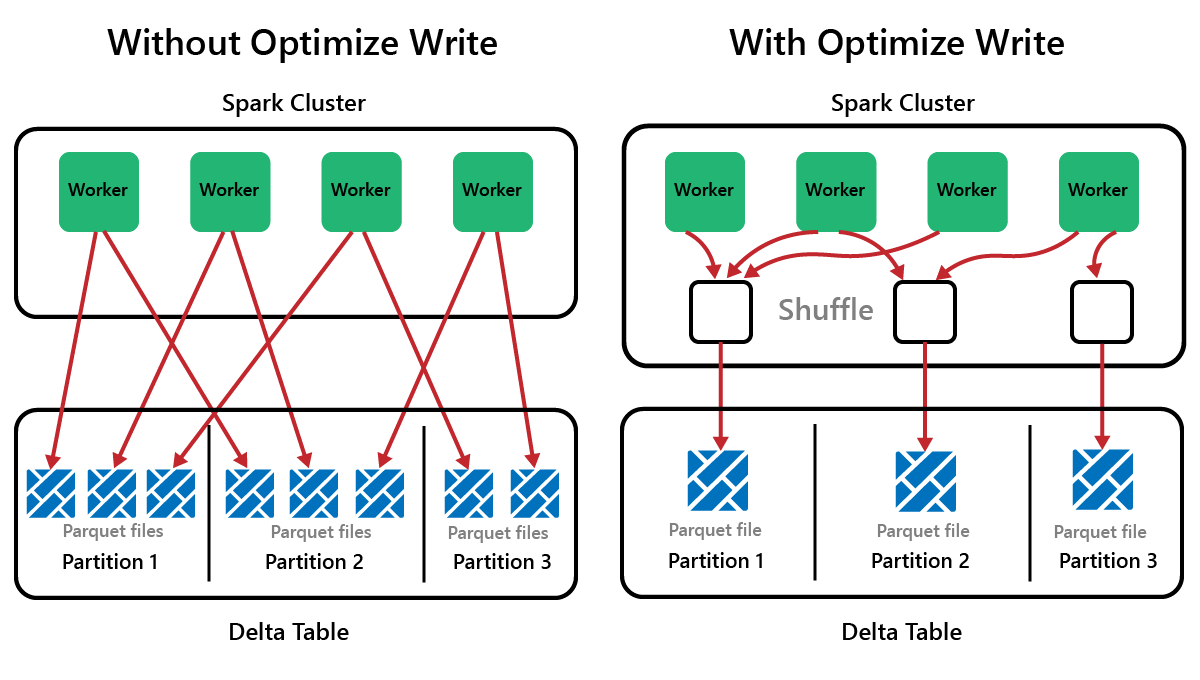
В Microsoft Fabric OptimizeWrite включена по умолчанию. Его можно включить или отключить на уровне сеанса Spark:
# Disable Optimize Write at the Spark session level
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", False)
# Enable Optimize Write at the Spark session level
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", True)
print(spark.conf.get("spark.microsoft.delta.optimizeWrite.enabled"))
Примечание.
OptimizeWrite также можно задать в свойствах таблицы и для отдельных команд записи.
Оптимизация
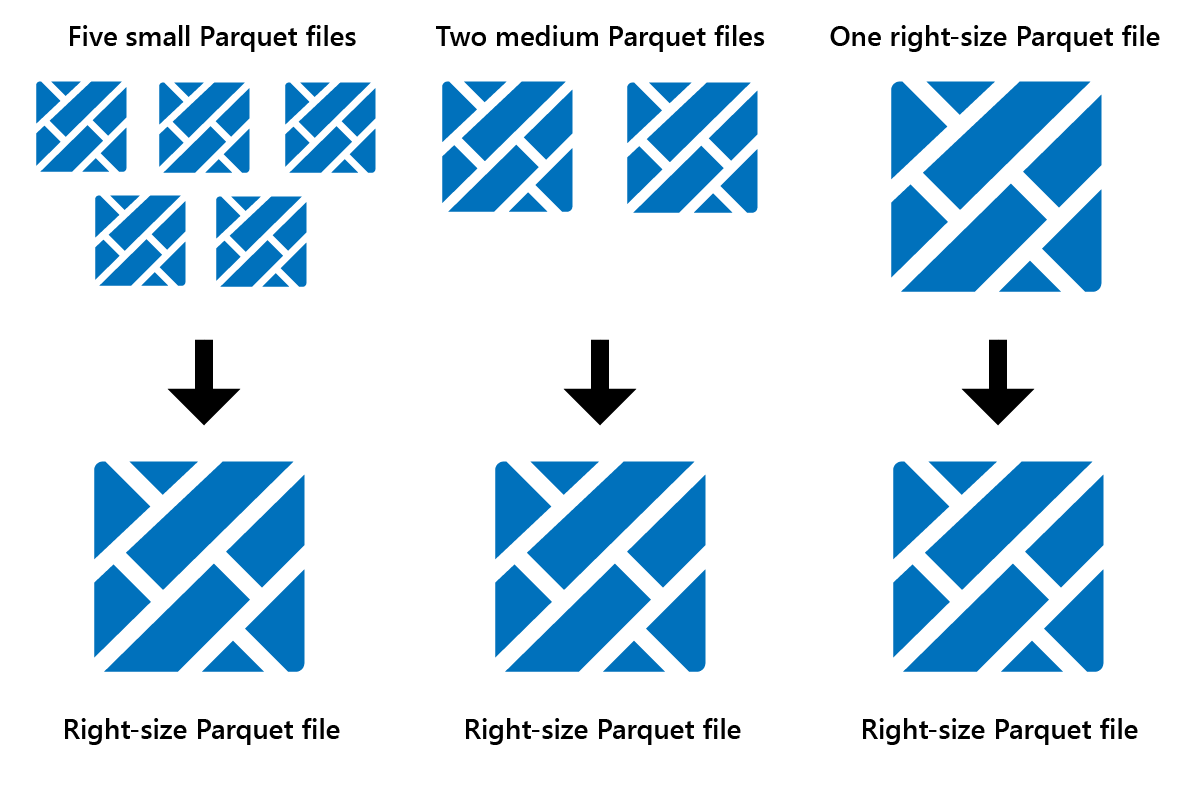
Оптимизация — это функция обслуживания таблиц, которая объединяет небольшие файлы Parquet в меньшее количество больших файлов. После загрузки больших таблиц вы можете запустить оптимизацию, в результате чего:
- меньше больших файлов
- лучшее сжатие
- эффективное распределение данных между узлами
Чтобы выполнить оптимизацию, выполните следующую команду:
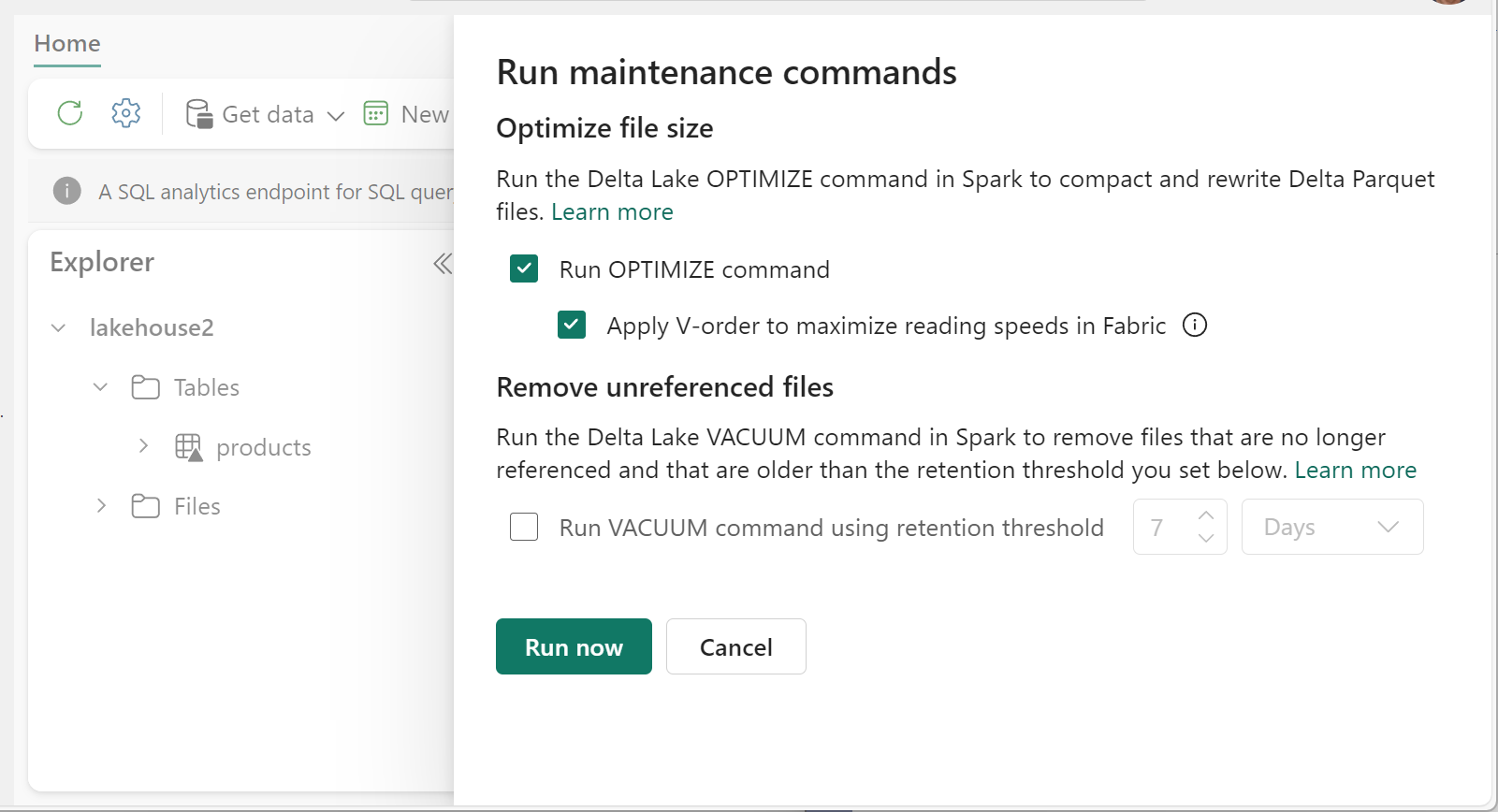
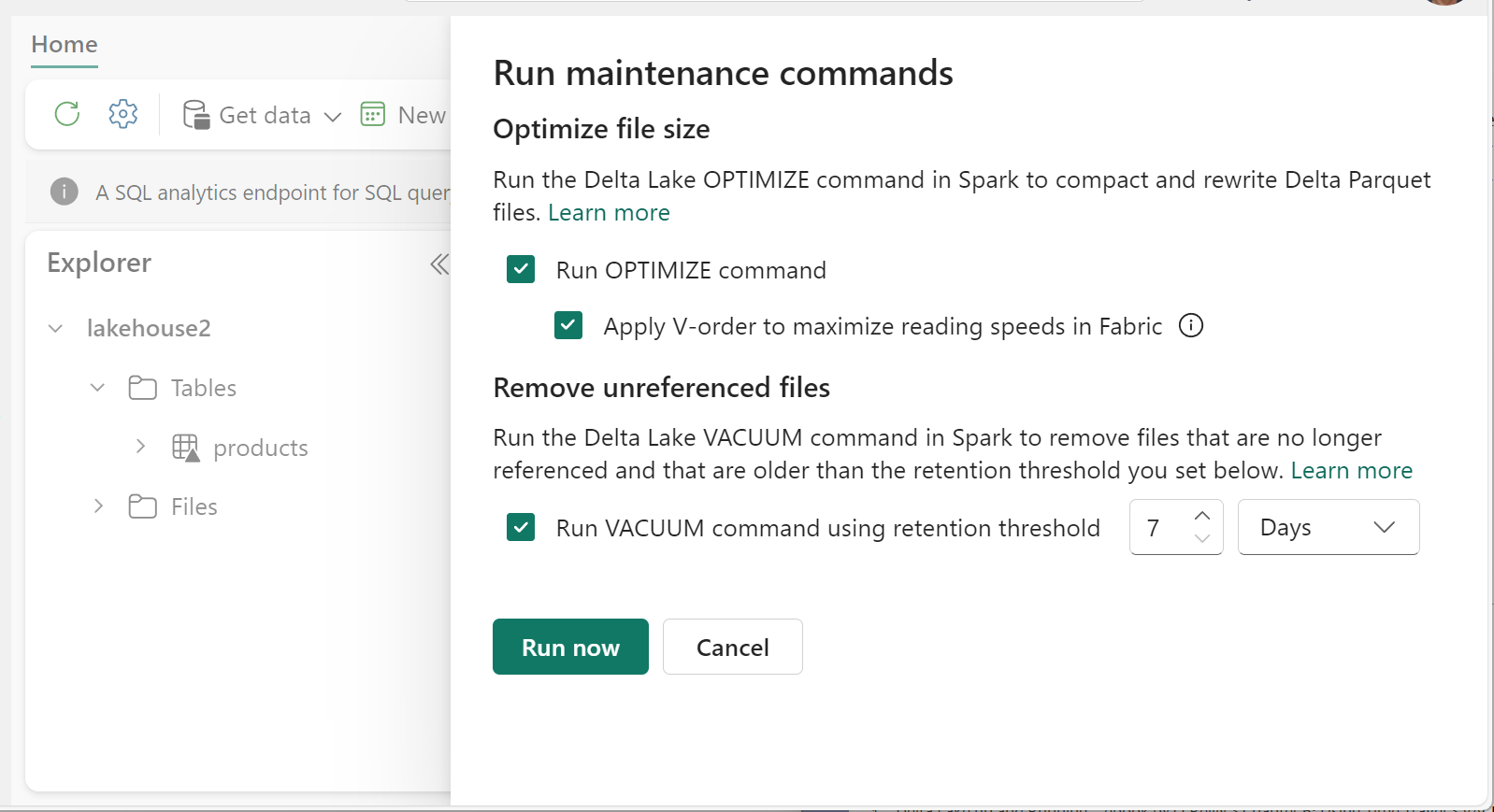
- В Lakehouse Explorer выберите ... меню рядом с именем таблицы и выберите "Обслуживание".
- Выберите команду Run OPTIMIZE. ( Выполнить оптимизацию).
- При необходимости выберите "Применить V-порядок", чтобы максимально увеличить скорость чтения в Fabric.
- Выберите Запустить сейчас.
Функция V-Order
При запуске Optimize можно при необходимости запустить V-Order, который предназначен для формата файла Parquet в Fabric. V-Order обеспечивает молниеносное чтение с использованием времени доступа к данным в памяти. Кроме того, она повышает эффективность затрат, так как она уменьшает сетевые ресурсы, диски и ресурсы ЦП во время чтения.
V-Order включен по умолчанию в Microsoft Fabric и применяется как данные записываются. Это вызывает небольшую нагрузку около 15% делает запись немного медленнее. Однако V-Order позволяет быстрее считывать данные из вычислительных подсистем Microsoft Fabric, таких как Power BI, SQL, Spark и другие.
В Microsoft Fabric подсистемы Power BI и SQL используют технологию Microsoft Verti-Scan, которая использует все преимущества оптимизации V-Order для ускорения операций чтения. Spark и другие подсистемы не используют технологию VertiScan, но по-прежнему получают выгоду от оптимизации V-Order примерно на 10 % быстрее считывания, иногда до 50 %.
V-Order работает путем применения специальных сортировки, распределения групп строк, кодирования словаря и сжатия в файлах Parquet. Это 100 % соответствует формату Parquet с открытым исходным кодом, и все обработчики Parquet могут читать его.
V-Order может оказаться не полезным для сценариев с интенсивным записью, таких как промежуточные хранилища данных, в которых данные считываются только один или два раза. В таких ситуациях отключение V-Order может сократить общее время обработки для приема данных.
Примените V-Order к отдельным таблицам с помощью функции обслуживания таблиц, выполнив OPTIMIZE команду.
Vacuum
Команда VACUUM позволяет удалить старые файлы данных.
При каждом обновлении или удалении создается новый файл Parquet и запись выполняется в журнале транзакций. Старые файлы Parquet сохраняются для включения перемещения по времени, что означает, что файлы Parquet накапливаются с течением времени.
Команда VACUUM удаляет старые файлы данных Parquet, но не журналы транзакций. При запуске VACUUM вы не сможете вернуть время назад, чем период хранения.
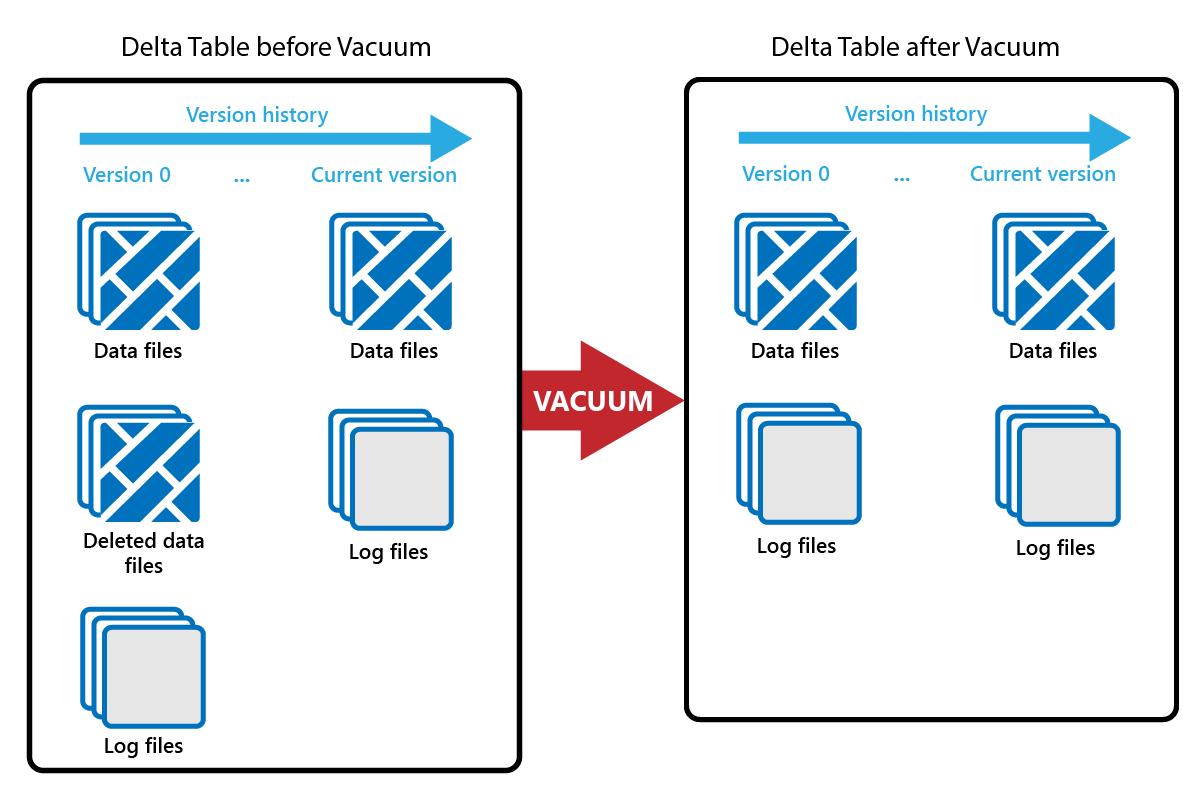
Файлы данных, которые в настоящее время не ссылаются в журнале транзакций и старше указанного периода хранения, окончательно удаляются с помощью запуска VACUUM. Выберите срок хранения на основе таких факторов, как:
- требования к хранению данных.
- Объем данных и затраты на хранение
- Частота изменения данных
- Нормативные требования
Срок хранения по умолчанию составляет 7 дней (168 часов), а система запрещает использовать более короткий период хранения.
Вы можете запустить VACUUM на нерегламентированном или запланированном режиме с помощью записных книжек Fabric.
Запустите VACUUM в отдельных таблицах с помощью функции обслуживания таблиц:
- В Lakehouse Explorer выберите ... меню рядом с именем таблицы и выберите "Обслуживание".
- Выберите команду Run VACUUM с помощью порогового значения хранения и задайте пороговое значение хранения.
- Выберите Запустить сейчас.
Вы также можете запустить VACUUM в качестве команды SQL в записной книжке:
%%sql
VACUUM lakehouse2.products RETAIN 168 HOURS;
ВАКУУМ фиксирует журнал транзакций Delta, чтобы просмотреть предыдущие запуски в ЖУРНАЛЕ ОПИСАНИЙ.
%%sql
DESCRIBE HISTORY lakehouse2.products;
Секционирование разностных таблиц
Delta Lake позволяет упорядочивать данные в секции. Это может повысить производительность, включив пропуск данных, что повышает производительность, пропуская неуместные объекты данных на основе метаданных объекта.
Рассмотрим ситуацию, когда хранятся большие объемы данных о продажах. Вы можете секционирование данных о продажах по годам. Секции хранятся в вложенных папках с именем Year=2021, Year=2022 и т. д. Если вы хотите сообщить только о данных о продажах за 2024 год, можно пропустить секции в течение других лет, что повышает производительность чтения.
Секционирование небольших объемов данных может снизить производительность, так как это увеличивает количество файлов и может усугубить "проблему с небольшими файлами".
Используйте секционирование, если:
- У вас есть очень большие объемы данных.
- Таблицы можно разделить на несколько больших секций.
Не используйте секционирование, если:
- Объемы данных небольшие.
- Столбец секционирования имеет высокую кратность, так как это создает большое количество секций.
- Столбец секционирования приведет к нескольким уровням.
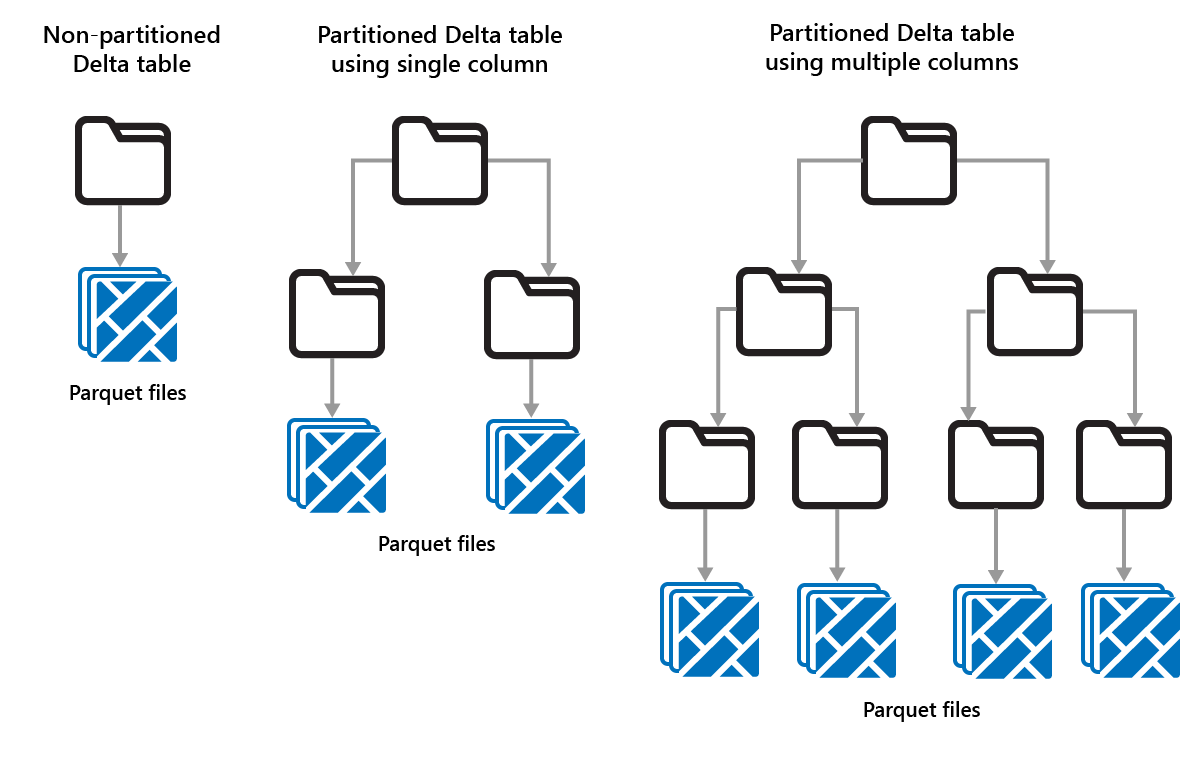
Секции — это фиксированный макет данных и не адаптируются к разным шаблонам запросов. При рассмотрении того, как использовать секционирование, думайте о том, как используются данные, и его детализация.
В этом примере кадр данных, содержащий данные продукта, секционируется по категориям:
df.write.format("delta").partitionBy("Category").saveAsTable("partitioned_products", path="abfs_path/partitioned_products")
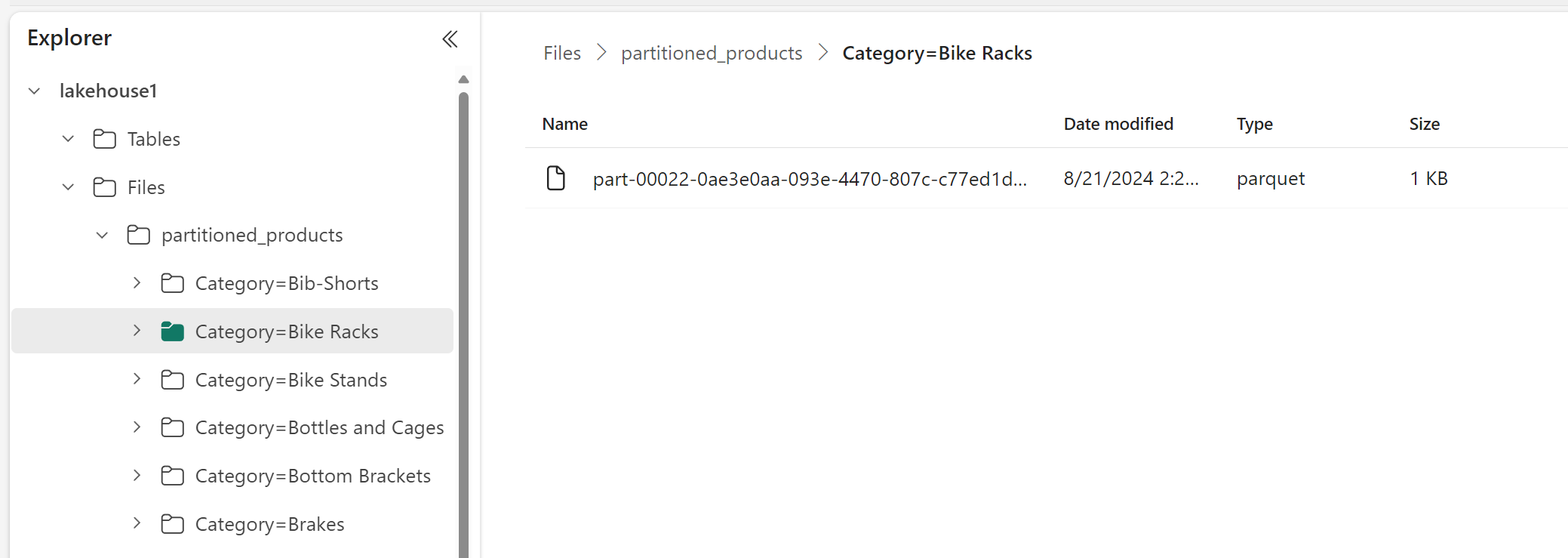
В обозревателе Lakehouse можно увидеть, что данные являются секционированной таблицей.
- В таблице есть одна папка с именем "partitioned_products".
- Существуют вложенные папки для каждой категории, например "Category=Bike Racks", и т. д.
С помощью SQL можно создать аналогичную секционированную таблицу:
%%sql
CREATE TABLE partitioned_products (
ProductID INTEGER,
ProductName STRING,
Category STRING,
ListPrice DOUBLE
)
PARTITIONED BY (Category);