Выбор подходящего целевого объекта вычислений
В Машинном обучении Azure целевые объекты вычислений являются физическими или виртуальными компьютерами, на которых выполняются задания.
Общие сведения о доступных типах вычислений
Машинное обучение Azure поддерживает несколько типов вычислений для экспериментирования, обучения и развертывания. Используя несколько типов вычислений, можно выбрать наиболее подходящий тип целевого объекта вычислений для ваших потребностей.
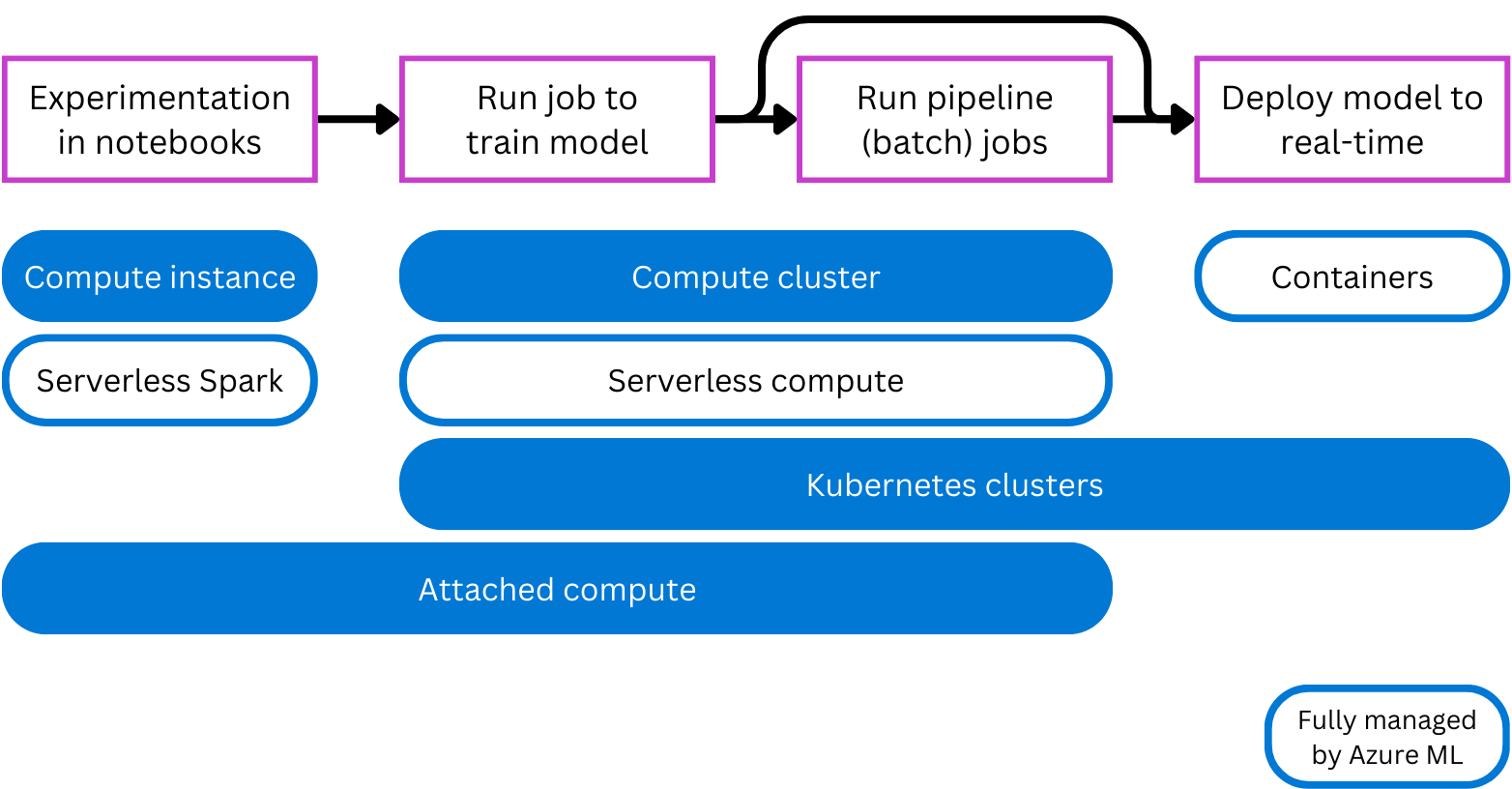
- вычислительный экземпляр: работает аналогично виртуальной машине и в основном используется для запуска тетрадей. Это оптимально подходит для экспериментирования.
- вычислительные кластеры: кластеры с несколькими узлами виртуальных машин, которые автоматически масштабируются для того, чтобы отвечать запросам. Экономичный способ выполнения скриптов, которые должны обрабатывать большие объемы данных. Кластеры также позволяют использовать параллельную обработку для распределения рабочей нагрузки и уменьшения времени выполнения скрипта.
- кластерах Kubernetes: кластер на основе технологии Kubernetes, что обеспечивает более подробный контроль над настройкой и управлением вычислительными ресурсами. Вы можете подключить кластер Azure Kubernetes (AKS) для облачных вычислений или кластер Arc Kubernetes для локальных рабочих нагрузок.
- присоединенные вычислительные. Позволяет подключать существующие вычислительные ресурсы, такие как виртуальные машины Azure или кластеры Azure Databricks к рабочей области.
- бессерверные вычисления: полностью управляемые вычислительные ресурсы по запросу, которые можно использовать для выполнения обучающих заданий.
Заметка
Машинное обучение Azure предлагает вам возможность создавать собственные вычислительные ресурсы и управлять ими или использовать вычислительные ресурсы, полностью управляемые Машинным обучением Azure.
Когда следует использовать какой тип вычислений?
Как правило, существуют некоторые рекомендации, которые можно использовать при работе с целевыми объектами вычислений. Чтобы понять, как выбрать подходящий тип вычислений, приведены несколько примеров. Помните, что используемый тип вычислений всегда зависит от конкретной ситуации.
Выбор целевого объекта вычислений для экспериментирования
Представьте, что вы являетесь специалистом по обработке и анализу данных, и вам предлагается разработать новую модель машинного обучения. Скорее всего, у вас есть небольшое подмножество обучающих данных, с помощью которых можно экспериментировать.
Во время экспериментирования и разработки вы предпочитаете работать в записной книжке Jupyter. Наибольшую пользу при работе с записной книжкой приносит вычислительная система, которая работает без перерывов.
Многие специалисты по обработке и анализу данных знакомы с запуском блокнотов на локальном устройстве. Вычислительный экземпляр , управляемый Машинным обучением Azure, является облачной альтернативой. Кроме того, вы можете выбрать бессерверные вычислительные Spark для запуска кода Spark в записных книжках, если вы хотите использовать распределенную вычислительную мощность Spark.
Выберите вычислительный ресурс для продакшна
После экспериментирования можно обучить модели, запустив скрипты Python для подготовки к продакшну. Скрипты будут проще автоматизировать и запланировать, когда вы хотите переобучить модель непрерывно с течением времени. Скрипты можно запускать в виде заданий конвейера.
При переходе в рабочую среду необходимо, чтобы целевой объект вычислений был готов к обработке больших объемов данных. Чем больше данных вы используете, тем лучше модель машинного обучения, скорее всего, будет.
При обучении моделей с помощью скриптов требуется целевой объект вычислений по запросу. вычислительный кластер автоматически масштабируется, когда необходимо выполнить скрипты, и уменьшается, когда выполнение скриптов завершается. Если вам нужен альтернативный вариант, который не нужно создавать и управлять им, можно использовать бессерверные вычислительные ресурсы машинного обучения Azure .
Выбор целевого объекта вычислений для развертывания
Тип вычислений, необходимых при использовании модели для создания прогнозов, зависит от того, требуется ли пакетное или реальное время прогнозирование.
Для пакетных прогнозов можно запустить задачу конвейера в системе Azure Machine Learning. Выделенные ресурсы для вычислений, такие как вычислительные кластеры и бессерверные вычислительные ресурсы в Azure Machine Learning, идеально подходят для заданий конвейера, так как они доступны по запросу и легко масштабируемы.
Если требуется прогнозирование в режиме реального времени, вам потребуется тип вычислений, выполняющихся непрерывно. Поэтому развертывания в режиме реального времени пользуются более простыми (и, таким образом, более экономичными) вычислительными ресурсами. Контейнеры идеально подходят для развертываний в режиме реального времени. При развертывании модели в управляемой сетевой конечной точке Машинное обучение Azure создает контейнеры для запуска модели и управляет ими. Кроме того, можно подключить кластеры Kubernetes для управления необходимыми вычислительными ресурсами для создания прогнозов в режиме реального времени.