Изучение архитектуры решения
Прежде чем приступить к работе, давайте рассмотрим архитектуру, чтобы понять все требования. Перенос модели в рабочую среду означает, что необходимо масштабировать решение и работать вместе с другими командами. Вместе со специалистами по обработке и анализу данных, инженерами данных и командой по инфраструктуре вы решили использовать следующий подход:
- Все данные будут храниться в Хранилище BLOB-объектов Azure, которыми будет управлять инженер данных.
- Команда инфраструктуры создаст необходимые ресурсы Azure, такие как рабочая область Машинного обучения Azure.
- Специалист по обработке и анализу данных сосредоточится на внутреннем цикле: разработке и обучении модели.
- Инженер по машинному обучению развернет обученную модель во внешнем цикле.
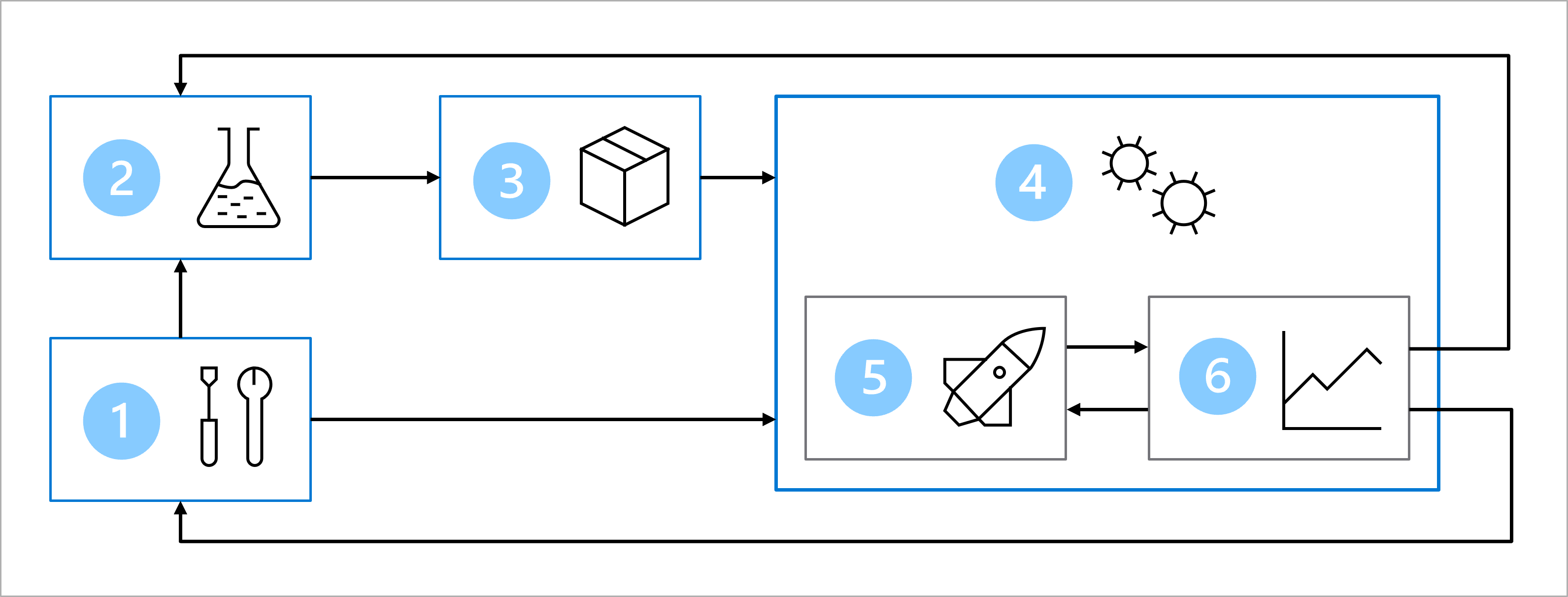
Вместе с большой командой вы разработали архитектуру для реализации подхода MLOps.
Примечание.
На схеме демонстрируется упрощенное представление архитектуры MLOps. Чтобы просмотреть архитектуру более подробно, изучите различные варианты использования в акселераторе решений MLOps (версии 2).
Основной целью архитектуры MLOps является создание надежного и воспроизводимого решения. Этапы создания такой архитектуры:
- Настройка: создание всех необходимых ресурсов Azure для решения.
- Разработка моделей (внутренний цикл): изучение и обработка данных для обучения и оценки модели.
- Непрерывная интеграция: упаковка и регистрация модели.
- Развертывание модели (внешний цикл): развертывание модели.
- Непрерывное развертывание: тестирование модели и перенос в рабочую среду.
- Мониторинг: мониторинг производительности модели и конечной точки.
На этом этапе проекта создается рабочая область Машинного обучения Azure, данные хранятся в Хранилище BLOB-объектов Azure, а команда по обработке и анализу данных обучила модель.
Вы хотите перейти от внутреннего цикла и разработки модели к внешнему циклу, развернув модель в рабочей среде. Поэтому необходимо преобразовать выходные данные команды по обработке и анализу данных в надежный и воспроизводимый конвейер в Машинном обучении Azure.
Если весь код будет храниться в виде скриптов, а скрипты будут выполняться в виде заданий Машинного обучения Azure, вы упростите автоматизацию обучения модели и переобучение модели в будущем.
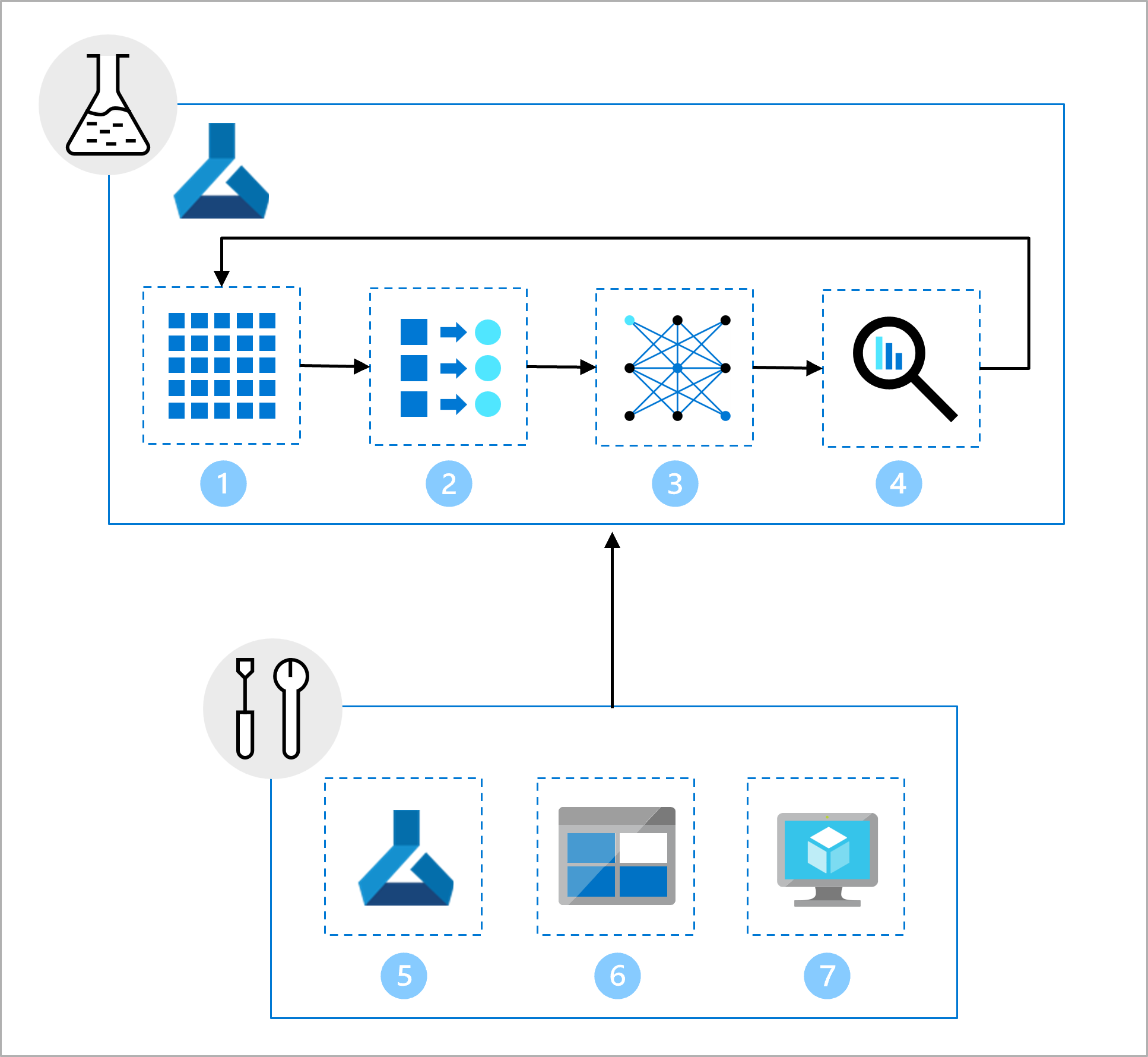
Команда по обработке и анализу данных работает над разработкой моделей. Они предоставляют записную книжку Jupyter, которая включает следующие задачи:
- Чтение и изучение данных.
- Выполните проектирование функций.
- Обучение модели.
- Оценка модели.
В ходе настройки команда по инфраструктуре создала следующие компоненты:
- Рабочая область разработки Машинного обучения Azure, которую может использовать команда по обработке и анализу данных для исследования и экспериментирования.
- Ресурс данных в рабочей области, который ссылается на папку в Хранилище BLOB-объектов Azure, содержащей данные.
- Вычислительные ресурсы, необходимые для запуска записных книжек и сценариев.
Ваш первый шаг в направлении MLOps — преобразовать работу специалистов по обработке и анализу данных, чтобы можно было легко автоматизировать разработку моделей. Пока команда по обработке и анализу данных работает в записной книжке Jupyter, вы должны выполнять скрипты с помощью заданий Машинного обучения Azure. Входные данные задания будут ресурсом данных, созданным командой по инфраструктуре, который указывает на данные, находящиеся в Хранилище BLOB-объектов Azure, подключенном к рабочей области Машинного обучения Azure.