Использование Spark в записных книжках
Вы можете запускать множество различных видов приложений в Spark, включая код в скриптах Python или Scala, код Java, скомпилированный в виде архива Java (JAR) и другие. Spark обычно используется в двух типах рабочих нагрузок:
- Задания пакетной или потоковой обработки для приема, очистки и преобразования данных — часто выполняются как часть автоматизированного конвейера.
- Интерактивные сеансы аналитики для изучения, анализа и визуализации данных.
Выполнение кода Spark в записных книжках
Azure Databricks включает интегрированный интерфейс записных книжек для работы со Spark. Записные книжки предоставляют интуитивно понятный способ объединения кода с заметками Markdown, который часто используют специалисты по обработке и анализу данных. Внешний вид интегрированного интерфейса записных книжек в Azure Databricks похож на вид записных книжек Jupyter — популярной платформы записных книжек с открытым кодом.
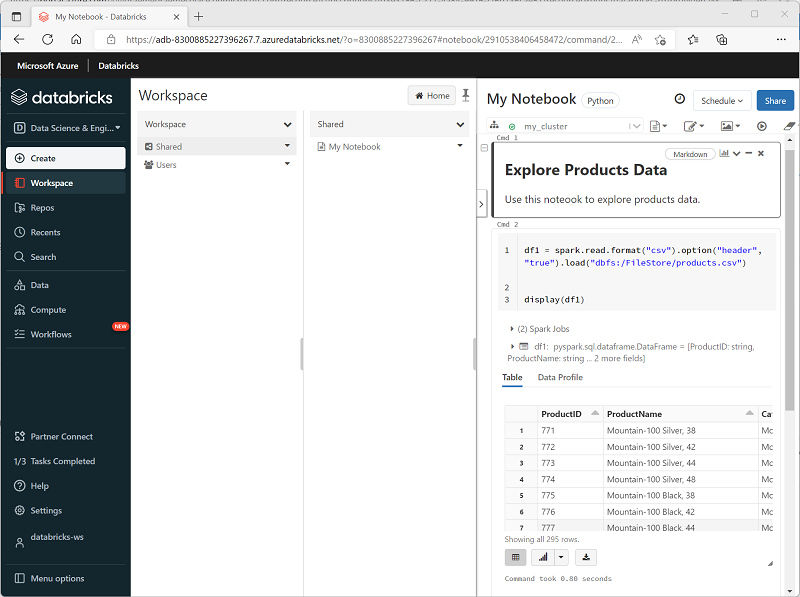
Записные книжки состоят из одной или нескольких ячеек, каждая из которых содержит код или заметку Markdown. Ячейки кода в записных книжках имеют некоторые функции для повышения производительности, в том числе:
- выделение синтаксиса и поддержка ошибок;
- автоматическое выполнение кода;
- интерактивные визуализации данных;
- возможность экспорта результатов.
Совет
Дополнительные сведения о работе с записными книжками в Azure Databricks см . в статье "Записные книжки Azure Databricks".