Знакомство со Spark
Чтобы получить более полное представление об использовании Apache Spark для обработки и анализа данных в Azure Databricks, важно понять базовую архитектуру.
Общий обзор
На высоком уровне служба Azure Databricks запускает кластеры Apache Spark в подписке Azure и управляет ими. Кластеры Apache Spark — это группы компьютеров, которые воспринимаются как один компьютер и обрабатывают выполнение команд, выданных из записных книжек. Кластеры позволяют обрабатывать данные параллельно на множестве компьютеров для улучшения масштабируемости и производительности. Они состоят из драйвера (ведущего узла) Spark и рабочих узлов. Драйвер отправляет задания на рабочие узлы и сообщает им о необходимости получить данные из указанного источника.
Программой драйвера в Databricks обычно является интерфейс записной книжки. Она содержит главный цикл программы и создает распределенные наборы данных в кластере, а затем применяет к этим наборам операции. Программы драйвера обращаются к Apache Spark через объект SparkSession независимо от расположения развертывания.
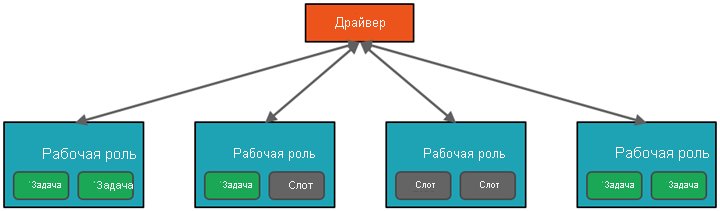
Microsoft Azure управляет кластером и автоматически масштабирует его по мере необходимости в зависимости от потребления и параметра, который использовался при настройке кластера. Можно также включить автоматическое завершение, что позволяет Azure завершать работу кластера после указанного числа минут бездействия.
Подробно о заданиях Spark
Отправляемая в кластер работа подразделяется на необходимое число независимых заданий. Так осуществляется распределение работы между узлами кластера. Задания далее делятся на задачи. Входные данные для задания секционируются в одну секцию или несколько. Эти секции являются единицами работы для каждого слота. В промежутках между выполнением задач может потребоваться реорганизация секций и предоставление к ним доступа по сети.
Секрет высокой производительности Spark заключается в параллелизме. Вертикальное масштабирование (добавление ресурсов на один компьютер) ограничено конечным объемом ОЗУ, числом потоков и скоростью центрального процессора. Однако кластеры масштабируются горизонтально за счет добавления новых узлов по мере необходимости.
Spark параллелизирует задания на двух уровнях:
- Первый уровень параллелизации представляет исполнитель — виртуальная машина Java на рабочем узле (как правило, по одному экземпляру на узел).
- Второй уровень параллелизации — слоты, число которых определяется числом ядер и процессоров на каждом узле.
- Каждый исполнитель имеет несколько слотов, которым можно назначать параллельные задачи.
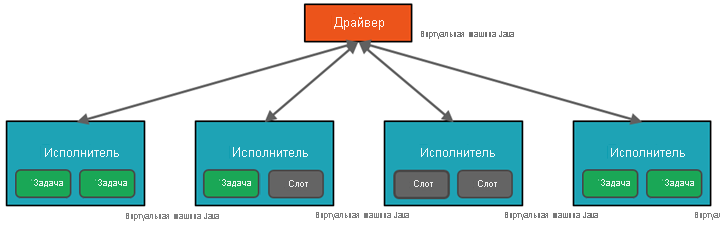
Виртуальная машина Java, конечно же, является многопоточной, но отдельная виртуальная машина, например координирующая работу драйвера, имеет конечный лимит ресурсов. Разделяя работу на задачи, драйвер может назначать единицы работы *слотам исполнителей на рабочих узлах для параллельного выполнения. Кроме того, драйвер определяет секционирование данных, чтобы их можно было распределять для параллельной обработки. Он назначает секцию данных каждой задаче, чтобы каждая задача знала, какой фрагмент данных ей нужно обрабатывать. После запуска каждая задача будет получать секцию данных, которая ей назначена.
Задания и этапы
В зависимости от выполняемой работы может потребоваться множество параллельных заданий. Каждое задание разбивается на этапы. Для большей понятности можно представить, что задание — построить дом:
- Первый этап — закладка фундамента.
- Второй этап — возведение стен.
- Третий этап — добавление крыши.
Делать эти этапы не по порядку бессмысленно или даже невозможно. Аналогичным образом Spark разбивает каждое задание на этапы, чтобы все выполнялось в верном порядке.
Модульность
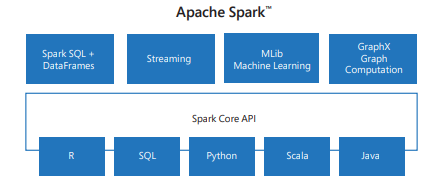
Spark включает библиотеки для задач, начиная от SQL до потоковой передачи и машинного обучения, что делает его инструментом для задач обработки данных. Некоторые из библиотек Spark включают:
- Spark SQL: для работы со структурированными данными.
- SparkML: для машинного обучения.
- GraphX: для обработки графа.
- Потоковая передача Spark: для обработки данных в режиме реального времени.
Совместимость
Spark может работать в различных распределенных системах, включая Hadoop YARN, Apache Mesos, Kubernetes или собственный диспетчер кластеров Spark. Он также считывает данные из различных источников данных, таких как HDFS, Cassandra, HBase и Amazon S3.