Оценка модели классификации
Большая часть машинного обучения заключается в оценке того, насколько хорошо работают модели. Эта оценка выполняется во время обучения, чтобы помочь сформировать модель, и после обучения, чтобы помочь нам судить, является ли модель нормальной для использования в реальном мире. Модели классификации нуждаются в оценке, как и модели регрессии, хотя то, как мы делаем эту оценку, иногда может быть немного сложнее.
Освежение по затратам
Помните, что во время обучения мы вычисляем, насколько плохо работает модель, и называем это затратами или потерями. Например, в линейной регрессии часто используется метрика, называемая среднеквадратической ошибкой (MSE). MSE вычисляется путем сравнения прогноза и фактической метки, возведения разницы в квадрат и вычисления среднего значения результата. Чтобы подогнать нашу модель и сообщить о том, насколько хорошо она работает, можно использовать MSE.
Функции затрат для классификации
Модели классификации оцениваются либо по их выходным вероятностям, таким как 40% вероятность лавины, либо по конечным меткам —no avalanche или avalanche. Использование вероятностей выходных данных может быть выгодно во время обучения. Незначительные изменения в модели отражаются в изменениях вероятностей, даже если они недостаточно, чтобы изменить окончательное решение. Использование конечных меток для функции затрат более полезно, если мы хотим оценить реальную производительность нашей модели. Например, в тестовом наборе. Так как для реального использования мы используем окончательные метки, а не вероятности.
Потеря журнала
Логарифмическая потеря — одна из самых популярных функций потерь для простой классификации. Логарифмическая функция потерь применяется к выходным вероятностям. Аналогично MSE, небольшие объемы ошибок приводят к небольшим затратам, а умеренные объемы ошибок приводят к большим затратам. Мы вычислим потерю журнала на следующем графике для метки, в которой правильный ответ был 0 (false).
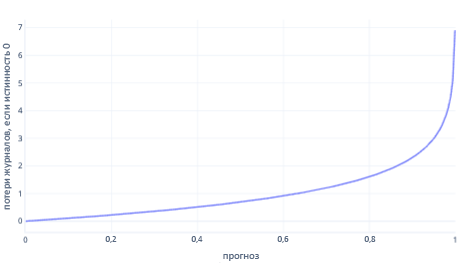
Ось x показывает возможные выходные данные модели — вероятности от 0 до 1, а ось y показывает стоимость. Если модель имеет высокую уверенность в том, что правильный ответ равен 0 (например, прогнозирование 0.1). Затем стоимость низка, так как в этом случае правильный ответ равен 0. Если модель уверенно предсказывает результат неправильно (например, прогнозирование 0,9), то стоимость становится высокой. На самом деле, при x=1 стоимость настолько высока, что мы обрезаем ось x здесь до 0,999, чтобы обеспечить возможность чтения графа.
Почему бы не MSE?
MSE и логарифмическая потеря — схожие метрики. Существуют некоторые сложные причины, почему логарифмическая потеря предпочительна для логистической регрессии, но есть и некоторые более простые причины. Например, потери журнала наказывает неправильные ответы гораздо сильнее, чем MSE. Например, на следующем графике, где правильный ответ равен 0, прогнозы с значением выше 0,8 имеют более высокое значение логарифмической ошибки, чем MSE.
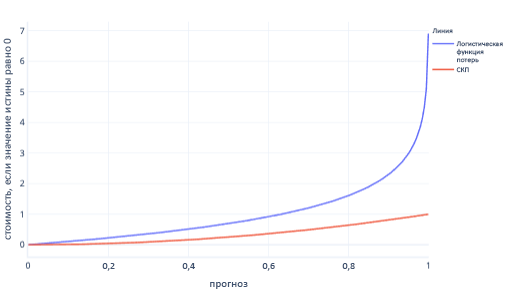
Повышение стоимости таким образом помогает модели быстрее обучаться из-за более крутого градиента линии. Аналогичным образом, логарифмическая функция потерь помогает моделям стать более уверенными в выдаче правильного ответа. Обратите внимание на предыдущий график: стоимость MSE для значений меньше 0,2 небольшая, а градиент почти плоский. Эта связь замедляет обучение моделей, близких к исправлению. Логарифмическая потеря имеет более крутой градиент для этих значений, что помогает моделям быстрее обучаться.
Ограничения функций затрат
Использование одной функции затрат для оценки модели всегда ограничено, так как она не говорит о том, какие ошибки делает ваша модель. Например, рассмотрим сценарий прогнозирования лавины. Большое значение логарифмической потери может означать, что модель неоднократно предсказывает лавины, когда их нет. Или это может означать, что неоднократно не удается предсказать происходящие лавины.
Чтобы лучше понять наши модели, это может быть проще использовать несколько чисел, чтобы оценить, хорошо ли они работают. Мы охватываем этот более крупный предмет в других учебных материалах, хотя мы касаемся его в следующих упражнениях.