Описание Apache HBase
Apache HBase — это база данных NoSQL с открытым кодом, созданная на основе Apache Hadoop. HBase обеспечивает произвольный доступ и строгую согласованность для больших объемов неструктурированных и частично структурированных данных в базе данных, не имеющей схемы, которая упорядочена по семействам столбцов. Кластеры HDInsight HBase 4.0 поставляются с Apache HBase 2.1.6 и Apache Phoenix 5.
С точки зрения пользователя HBase напоминает базу данных. Данные хранятся в строках и столбцах таблицы, данные в строке группируются по семейству столбцов. База данных HBase не имеет схемы в том смысле, что ни столбцы, ни типы хранимых в них данных не нужно определять до использования. Открытый код линейно масштабируется, чтобы обрабатывать петабайты данных на тысячах узлов.
В HBase есть следующие функции, которые делают ее уникальной.
Согласованные операции чтения и записи
Низкая задержка операций
Автоматическое сегментирование
Автоматическая отработка отказа сервера региона
Интеграция с Hadoop/HDFS/MapReduce
Клиентский API Java
Поддержка Thrift и RESTFUL для внешних интерфейсов, отличных от Java
Кэш блока и фильтры раскрытия
Azure HDInsight HBase с Apache Phoenix обеспечивает следующие дополнительные преимущества.
Интерфейсы SQL и NoSQL
Гибкое планирование ресурсов
Глобальное распределение и репликация с помощью сети Azure
Разделение уровней вычисления и хранения
Тесная интеграция с функциями безопасности в HDInsight Enterprise
Ускоренная запись HDInsight HBase для операций чтения и записи с чрезвычайно низкой задержкой
Apache Phoenix для отправки запросов наподобие SQL в режиме реального времени
Использование Azure HDInsight с HBase позволяет запускать базы данных NoSQL в очень крупном масштабе. Вам как инженеру данных в компании Contoso необходима возможность выполнять тесты производительности, чтобы оценить производительность и масштаб HDInsight HBase, прежде чем использовать платформу для критически важных рабочих сценариев.
HBase в HDInsight работает с разделением вычислений и хранилища. Кластеры HDInsight HBase настроены на хранение данных непосредственно в службе хранилища Azure, что обеспечивает небольшую задержку и повышенную гибкость в выборе соотношения производительности и стоимости. Это свойство позволяет клиентам создавать интерактивные веб-сайты, работающие с большими наборами данных, создавать службы для хранения данных датчиков и телеметрии с миллионов конечных точек, а также для анализа этих данных с помощью заданий Hadoop. HBase и Hadoop — это хорошие отправные точки для создания проектов для работы с большими данными в Azure. Благодаря этим службам приложения могут в реальном времени работать с большими наборами данных. В реализациях HDInsight HBase используется горизонтальная архитектура HBase для автоматического сегментирования таблиц. Это также обеспечивает строгую согласованность для операций чтения и записи и автоматический переход на другой ресурс. Производительность повышается за счет кэширования операций чтения в памяти и потоковой записи с высокой пропускной способностью Также для HDInsight HBase доступна подготовка виртуальных сетей. Кластер HBase можно создать внутри виртуальной сети. Дополнительные сведения см. в статье Создание кластеров HBase в виртуальной сети Azure.
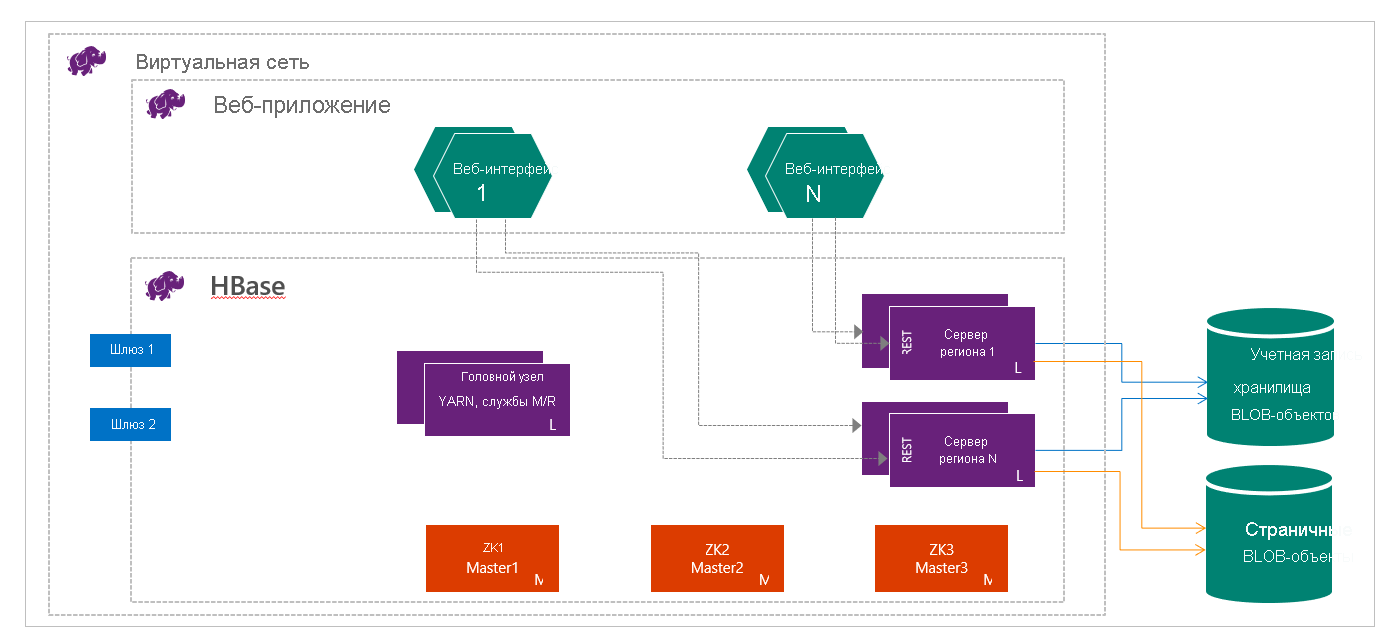
Вам как инженеру данных необходимо определить наиболее подходящий тип кластера HDInsight для создания решения. Вы будете использовать кластеры HBase в HDInsight для базы данных NoSQL, которая масштабируется линейно, обеспечивая большую пропускную способность, обеспечивает низкую задержку чтения и неограниченное хранилище в зависимости от стоимости.
Ниже приведены основные сценарии использования HBase в HDInsight.
Хранилище "ключ-значение"
HBase обычно используется в качестве хранилища ключевых значений и подходит для управления системами сообщений.
информация от датчиков;
HBase подходит для записи данных, собираемых постепенно из различных источников, включая социальную аналитику, временные ряды, актуализацию тенденций и счетчиков на интерактивных панелях мониторинга, а также управление системами журналов аудита.
Запросы в режиме реального времени
Apache Phoenix — это система запросов SQL для Apache HBase. Доступ к системе осуществляется через драйвер JDBC, и она позволяет создавать запросы и управлять таблицами HBase с использованием SQL.
HBase как платформа
Поверх HBase могут выполняться приложения, используя ее как хранилище данных. Например, это используется в Phoenix, OpenTSDB, Kiji и Titan. Также возможна интеграция приложений с HBase. Примерами являются Apache Hive, Apache Pig, Solr, Apache Flume, Apache Impala, Apache Spark, Ganglia и Apache Drill.
HBase в HDInsight можно использовать как отдельное приложение или развертывать вместе с другими приложениями для анализа больших данных, такими как Spark, Hadoop, Hive или Kafka.
Модель данных HBase хранит частично структурированные данные различных типов, с различными размерами столбцов и полей. Структура модели данных HBase упрощает секционирование и распределение данных в кластере. Модель данных HBase состоит из нескольких логических компонентов: ключей строк, семейств столбцов, имени таблицы, метки времени и т. д.
Ключ строки используется для уникальной идентификации строк в таблицах HBase. В HDInsight можно либо записать данные в HBase непосредственно с помощью нескольких доступных API, таких как HBase REST, HBase RPC, Сервер запросов Phoenix, массовая загрузка HBase, либо использовать интеграцию с несколькими платформами больших данных, такими как Apache Spark, Hive и т. д.
Вы можете использовать функцию ускорения записи HBase, чтобы обеспечить высокую пропускную способность записи. Дополнительные сведения об архитектуре HBase и рекомендациях см. в руководстве по HBase.