Устранение потенциальных причинений вреда
После определения базового плана и способа измерения вредных выходных данных, создаваемых решением, можно предпринять шаги по устранению потенциальных рисков, а также при необходимости повторного тестирования измененной системы и сравнения уровней вреда с базовыми показателями.
Устранение потенциальных рисков в решении сгенерируемым искусственным интеллектом включает в себя многоуровневый подход, в котором методы устранения рисков можно применять на каждом из четырех уровней, как показано ниже.
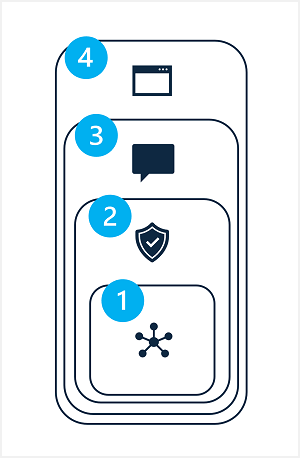
- Модель
- система Сейф ty
- Метапроимпт и заземление
- Возможности для пользователя
1. Уровень модели
Уровень модели состоит из одной или нескольких моделей сгенерированных ИИ в центре решения. Например, решение может быть создано вокруг модели, например GPT-4.
Ниже приведены способы устранения рисков, которые можно применить на уровне модели:
- Выбор модели, подходящей для предполагаемого использования решения. Например, хотя GPT-4 может быть мощной и универсальной моделью, в решении, которое требуется только для классификации небольших, конкретных текстовых входных данных, более простая модель может обеспечить необходимые функциональные возможности с меньшим риском создания вредного контента.
- Настройка базовой модели с собственными данными обучения, чтобы ответы, создаваемые им, скорее всего, были релевантными и область для вашего сценария решения.
2. Уровень системы безопасности
Уровень системы безопасности включает конфигурации и возможности уровня платформы, которые помогают снизить вред. Например, Azure AI Studio поддерживает фильтры содержимого, которые применяют критерии для подавления запросов и ответов на основе классификации содержимого на четыре уровня серьезности (безопасный, низкий, средний и высокий) для четырех категорий потенциального вреда (ненависти, сексуального насилия и самоповредения).
Другие способы устранения рисков уровня системы безопасности могут включать алгоритмы обнаружения злоупотреблений, чтобы определить, является ли решение систематически злоупотреблять (например, с помощью больших объемов автоматических запросов от бота) и уведомлений об оповещениях, которые позволяют быстро реагировать на потенциальное злоупотребление системой или вредное поведение.
3. Метапроимпт и слой заземления
Метапроимпт и слой заземления фокусируется на создании запросов, отправленных в модель. Методы устранения вреда, которые можно применить на этом уровне, включают:
- Указание метапроимптов или системных входных данных, определяющих параметры поведения для модели.
- Применение инженерии запросов для добавления данных заземления к входным запросам, максимизируя вероятность соответствующих, нехармных выходных данных.
- Использование метода получения дополненного поколения (RAG) для получения контекстных данных из доверенных источников данных и включения его в запросы.
4. Уровень взаимодействия с пользователем
Уровень взаимодействия с пользователем включает в себя программное приложение, с помощью которого пользователи взаимодействуют с формируемой моделью ИИ и документацией или другими пользователями, описывающими использование решения для своих пользователей и заинтересованных лиц.
Проектирование пользовательского интерфейса приложения для ограничения входных данных для конкретных субъектов или типов, а также применение проверки ввода и вывода может снизить риск потенциально опасных ответов.
Документация и другие описания создаваемого решения ИИ должны быть надлежащим образом прозрачными в отношении возможностей и ограничений системы, моделей, на которых она основана, и любых потенциальных причинений, которые не всегда могут быть устранены мерами по устранению рисков, которые вы создали.