Упражнение. Создание модели машинного обучения
Чтобы создать модель машинного обучения, вам потребуется два набора данных: один для обучения и один для тестирования. На практике у вас бывает только один набор данных, поэтому его можно разделить на две части. В этом упражнении вы разделите подготовленный ранее кадр данных в соотношении 80 к 20, чтобы его можно было использовать для обучения модели машинного обучения. Вы также разделите кадр данных на столбцы признаков и столбцы меток. Столбцы признаков используются в качестве входных данных для модели (например, аэропорт отправления и прибытия и запланированное время отправления), а столбцы меток содержат значения, которые модель попытается предсказать, — в данном случае это столбец ARR_DEL15, который указывает, прибудет ли рейс вовремя.
Переключитесь на записную книжку Azure, которую вы создали в предыдущем разделе. Если вы закрыли записную книжку, войдите на портал "Записные книжки Microsoft Azure", откройте свою записную книжку и выберите Ячейка ->Запустить все для повторного выполнения всех ячеек в записной книжке после открытия.
В новой ячейке в конце записной книжки введите и выполните следующие инструкции:
from sklearn.model_selection import train_test_split train_x, test_x, train_y, test_y = train_test_split(df.drop('ARR_DEL15', axis=1), df['ARR_DEL15'], test_size=0.2, random_state=42)Первая инструкция импортирует вспомогательную функцию scikit-learn train_test_split. Во второй строке указана функция для разделения кадра данных на обучающий набор, содержащий 80 % исходных данных, и набор тестирования, содержащий оставшиеся 20 %. Параметр
random_stateзаполняет начальными значениями генератор случайных чисел, используемый для разделения, а первый и второй параметры — это кадры данных, содержащие столбцы признаков и столбец меток.train_test_splitвозвращает четыре кадра данных. Используйте следующую команду для отображения числа строк и столбцов в кадре данных, содержащем столбцы признаков, используемые для обучения:train_x.shapeТеперь используйте следующую команду для отображения числа строк и столбцов в кадре данных, содержащем столбцы признаков, используемые для тестирования:
test_x.shapeЧем отличаются два результата и почему?
Можно ли предсказать, что вы увидите, если вызовете shape в других двух кадрах данных, train_y и test_y? Если вы не знаете точно, попробуйте и узнаете.
Существует много типов моделей машинного обучения. Одним из наиболее распространенных является модель регрессии, которая использует один из алгоритмов регрессии для получения числового значения, например возраст человека или вероятность того, что операция по кредитной карте является мошеннической. Вы будете обучать модель классификации, которая пытается разрешить набор входных данных в один из наборов известных выходных данных. Классический пример модели классификации — это модель, которая проверяет сообщения электронной почты и классифицирует их как "спам" или "не спам". У вас будет модель двоичной классификации, прогнозирующая, прибудет ли рейс вовремя или с опозданием ("двоичная", поскольку здесь возможно только два результата).
Одним из преимуществ использования scikit-learn является то, что вам не нужно создавать эти модели или реализовать используемые в них алгоритмы вручную. Библиотека scikit-learn включает различные классы для реализации распространенных моделей машинного обучения. Один из них — RandomForestClassifier, который подходит для деревьев принятия решений и использует вычисление среднего значения, чтобы увеличить общую точность и ограничить лжевзаимосвязь.
Выполните следующий код в новой ячейке, чтобы создать объект
RandomForestClassifierи обучить его с помощью метода fit.from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier(random_state=13) model.fit(train_x, train_y)Выходные данные показывают параметры, используемые в классификаторе, включая
n_estimators, который указывает число деревьев в каждом лесу деревьев принятия решений, иmax_depth, который указывает максимальную глубину дерева принятия решений. Указанные значения используются по умолчанию, но их можно переопределить при создании объектаRandomForestClassifier.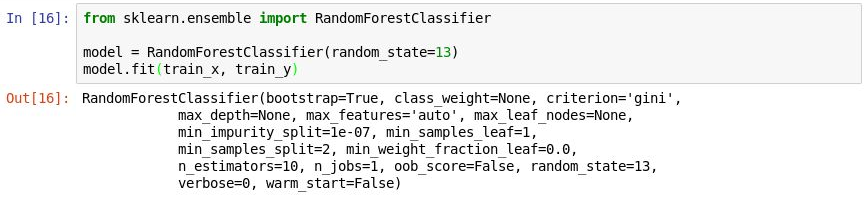
Обучение модели
Теперь вызовите метод predict для тестирования модели, используя значения в
test_x, а затем метод score, чтобы определить среднюю точность модели:predicted = model.predict(test_x) model.score(test_x, test_y)Вы увидите такой результат:

Тестирование модели
Средняя точность составляет 86 %, что на первый взгляд кажется хорошим результатом. Но средняя точность не всегда является надежным показателем точности модели классификации. Давайте копнем глубже и посмотрим, насколько точна модель на самом деле, то есть как хорошо она определяет своевременность прибытия рейсов.
Существует несколько способов для измерения точности модели классификации. Одним из лучших показателей модели двоичной классификации является площадь под ROC-кривой (иногда называется ROC AUC), которая, по сути, предназначена для количественной оценки того, как часто модель делает правильный прогноз независимо от результата. В этом модуле вы вычислите показатель ROC AUC для модели, созданной ранее, и узнаете, почему этот показатель меньше, чем средняя точность результатов по методу score. Вы также узнаете о других способах оценить точность модели.
Прежде чем вычислить ROC AUC, необходимо создать вероятности прогноза для тестового набора. Эти вероятности являются приблизительными для каждого из классов, или ответов, которые может предсказать модель. Например,
[0.88199435, 0.11800565]означает, что существует 89 % вероятности того, что рейс прибудет вовремя (ARR_DEL15 = 0) и 12 % вероятности того, что он опоздает (ARR_DEL15 = 1). Сумма двух вероятностей составляет 100 %.Выполните следующий код, чтобы создать набор вероятностей прогнозирования на основе тестовых данных:
from sklearn.metrics import roc_auc_score probabilities = model.predict_proba(test_x)Теперь выполните следующую инструкцию для создания оценки ROC AUC по вероятностям с помощью метода scikit-learn roc_auc_score:
roc_auc_score(test_y, probabilities[:, 1])Убедитесь, что в выходных данных отображается оценка 67%:

Создание оценки AUC
Почему показатель AUC ниже, чем средняя точность, вычисленная в предыдущем упражнении?
В выходных данных метода
scoreотражается, сколько элементов тестового набора модель предсказала правильно. Эта оценка искажена потому, что набор данных, на котором модель обучалась и тестировалась, содержит гораздо больше строк с прибытием вовремя, чем с опозданием. Из-за этого дисбаланса в данных у вас больше шансов, когда вы предсказываете своевременное прибытие, а не опоздание.ROC AUC учитывает это и предоставляет более точное обозначение вероятности того, насколько прогноз прибытия вовремя или с опозданием будет правильным.
Чтобы узнать больше о поведении модели, создайте матрицу неточностей, также известную как матрица ошибок. Матрица неточностей считает количество раз, когда каждый ответ был классифицирован как правильный или неправильный. В частности, она предназначена для оценки количества ложных положительных, ложных отрицательных, истинных отрицательных и истинных положительных результатов. Это важно, ведь если модель двоичной классификации, обученная для различения кошек и собак, тестируется с набором данных, на 95 % состоящим из собак, она может получить оценку 95 %, просто если будет каждый раз отвечать "собака". Но если она не распознает ни одной кошки, она будет бесполезна.
Чтобы создать матрицу неточностей для модели, используйте следующий код:
from sklearn.metrics import confusion_matrix confusion_matrix(test_y, predicted)Первая строка в выходных данных представляет рейсы, которые прибыли вовремя. Первый столбец в этой строке показывает, сколько рейсов правильно предсказаны как прибывшие вовремя, а второй — сколько рейсов предсказаны как опоздавшие, но на самом деле не опоздали. По этим данным кажется, что модель справляется с прогнозированием своевременного прибытия.

Создание матрицы неточностей
Но посмотрите на вторую строку, где показаны задержанные рейсы. В первом столбце показано, сколько опоздавших рейсов были неправильно предсказаны как своевременные. Во втором столбце показано, сколько опоздавших рейсов было предсказано правильно. Очевидно, модель предсказывает задержки гораздо хуже, чем своевременное прибытие. В идеале в матрице неточностей должны быть большие числа в левом верхнем и правом нижнем углах и маленькие (желательно 0) в правом верхнем и левом нижнем углах.
Другие меры правильности для модели классификации — точность и отзыв. Предположим, модели предоставлено три своевременных и три задержанных рейса, и она правильно спрогнозировала два своевременных, но не угадала с двумя задержанными. В этом случае точность модели составит 50 % (два из четырех рейсов были классифицированы как своевременные и действительно прибыли вовремя), тогда как полнота будет составлять 67 % (правильно определены два из трех своевременных рейсов). Дополнительные сведения о точности и отзыве можно получить тут: https://en.wikipedia.org/wiki/Precision_and_recall.
Библиотека scikit-learn содержит удобный метод precision_score для вычисления точности. Чтобы измерить точность модели, выполните следующие инструкции:
from sklearn.metrics import precision_score train_predictions = model.predict(train_x) precision_score(train_y, train_predictions)Изучите выходные данные. Какова точность вашей модели?

Измерение точности
Библиотека scikit-learn также содержит метод recall_score для вычисления полноты. Чтобы измерить отзыв модели, выполните следующие инструкции:
from sklearn.metrics import recall_score recall_score(train_y, train_predictions)Каков отзыв модели?

Измерение отзыва
Используйте команду Файл ->Сохранить и создать контрольную точку, чтобы сохранить записную книжку.
В реальном мире специалист по обработке обучающих данных будет искать способы повысить точность модели. Например, можно попробовать разные алгоритмы и настроить выбранный алгоритм, чтобы найти оптимальное сочетание параметров. Кроме того, можно расширить набор данных до миллионов, а не нескольких тысяч строк, и попытаться сократить дисбаланс между своевременными и опоздавшими рейсами. Но для наших целей модель подходит без изменений.