Интеграция Apache Spark и запросов Hive LLAP
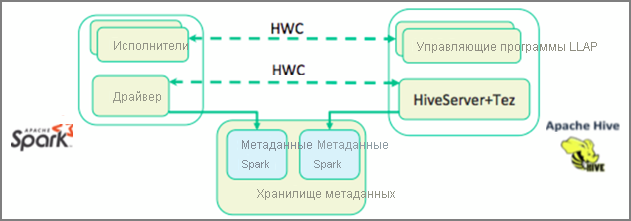
В предыдущей единице мы рассматривали два способа запроса статических данных, хранящихся в кластере интерактивных запросов, — Data Analytics Studio и записная книжка Zeppelin. Но что делать, если вы хотите передать новые данные о недвижимости в кластеры с помощью Spark и запросить его с помощью Hive? Поскольку Hive и Spark имеют два разных метахранилища, им требуется соединитель для моста между ними, и Apache Hive Warehouse Connector является этим мостом. Библиотека Hive Warehouse Connector позволяет более просто работать с Apache Spark и Apache Hive, поддерживая такие задачи, как перемещение данных между кадрами и таблицами Hive в Spark, а также направление данных потоковой передачи Spark в таблицы Hive. Мы не будем настраивать соединитель в нашем сценарии, но важно помнить, что этот параметр существует.
Apache Spark имеет API структурированной потоковой передачи, который предоставляет возможности потоковой передачи, недоступные в Apache Hive. Начиная с HDInsight 4.0 Apache Spark 2.3.1 и Apache Hive 3.1.0 имеют отдельные хранилища метаданных, что затруднило взаимодействие. Hive Warehouse Connector упрощает совместное использование Spark и Hive. Библиотека Hive Warehouse Connector загружает данные из управляющих программ LLAP в параллельные исполнители Spark, делая их более эффективными и масштабируемыми, чем использование стандартного подключения JDBC из Spark к Hive.
Операции, поддерживаемые Hive Warehouse Connector:
- описание таблицы;
- Создание таблицы для данных в формате оптимизированных столбцов в строках (ORC)
- выбор данных Hive и получение кадра данных;
- пакетная запись кадров данных в Hive;
- выполнение инструкции обновления Hive;
- чтение данных таблицы из Hive, их преобразование в Spark и запись в новую таблицу Hive;
- запись кадра данных или потока Spark в Hive с помощью HiveStreaming.
После развертывания кластера Spark и развернутого кластера интерактивных запросов настройте параметры кластера Spark в Ambari, который является веб-средством, включенным во все кластеры HDInsight. Чтобы открыть Ambari, перейдите по адресу https://servername.azurehdinsight.net в браузере, где ServerName — имя кластера интерактивных запросов.
Затем, чтобы записать данные потоковой передачи Spark в таблицы, создайте таблицу Hive и начните записывать в нее данные. Затем выполните запросы к данным потоковой передачи. Можно использовать любой из следующих элементов:
- spark-shell
- PySpark
- spark-submit
- Zeppelin
- Livy