Когда следует использовать интерактивный запрос HDInsight?
Вам как бизнес-аналитику необходимо определить наиболее подходящий тип кластера HDInsight для создания решения. Кластеры интерактивных запросов предоставляют ряд функций и возможностей взаимодействия, которые делают их уникальными для бизнес-аналитиков, знакомых с SQL. Это замечательно для пользователей, работающих с инструментами бизнес-аналитики. Таким пользователям нужны быстрые интерактивные запросы. Существуют и другие преимущества, такие как поддержка различных форматов файлов, параллелизма и атомарных, согласованных, изолированных и устойчивых транзакций (ACID). Кроме того, реализована Apache Ranger для детализации контроля над данными на уровне строк и столбцов.
Примечание.
Содержимое этого модуля относится к кластерам Interactive Query, созданным для HDInsight 4,0, в которых используются Hive 3,1 и LLAP, также известные как Hive LLAP.
У вас есть большой набор данных, на которых необходимо выполнить запрос
Кластеры интерактивных запросов лучше всего подходят для больших наборов данных, которые можно запрашивать как есть или с минимальными преобразованиями. Ситуации, когда вы будете выполнять разнообразные запросы к данным и вам будут нужны немедленные ответы. Кластеры интерактивных запросов не оптимизируются для выполнения долго выполняющихся пакетных вычислений. Интерактивный запрос поддерживает следующие форматы файлов: ORC, Parquet, CSV, Avro, JSON, text и TSV.
Требуются функции, аналогичные SQL
Если вам нужно выполнять интерактивные и нерегламентированные запросы с задержкой менее секунды для больших данных, находящихся в службе хранилища Azure и Azure Data Lake Storage, и вы предпочитаете запросы, похожие на SQL, кластеры Interactive Query Azure HDInsight отлично для этого подходят. Как бизнес-аналитик вы хорошо знакомы с таблицами SQL и создаете запросы с помощью SQL. Apache Hadoop — это мощный инструмент для анализа больших данных. Работа Apache Hadoop на платформе MapReduce и ее Java API могут стать для вас ограничением, если вы ваши навыки программирования на Java слегка утратили актуальность. В этом случае интерактивный запрос HDInsight лучше подходит, так как он основан на Apache Hadoop, но проще для всех, кто имеет опыт с SQL. Интерактивный запрос использует для обработки данных таблицы Hive, схожие с SQL, а для запроса данных язык запросов, похожий на SQL, который называется HiveQL. Использование Hive менее сложно, чем обработка данных с помощью MapReduce в Apache Hadoop. Hive ускоряет и повышает эффективность развертывания решений в вашей компании.
Быстрые интерактивные запросы с интеллектуальным кэшированием
В кластерах интерактивных запросов используются интеллектуальные методы кэширования, позволяющие распределять данные между динамическими ОЗУ, SSD узла локального кластера и системами удаленного хранилища, такими как большой двоичный объект Azure и Azure Data Lake Storage, для получения интерактивных и быстрых результатов запросов к большим данным. Хорошим примером использования расширенного кэширования является динамический кэш текста, который преобразует данные CSV в оптимизированный в памяти формат в режиме реального времени, поэтому кэширование является динамическим и запросы определяют, какие данные кэшируются. Эта функция означает, что вам не нужно сначала загружать и преобразовывать данные. Вы можете передать данные в службу хранилища Azure в исходном формате и начать выполнять запросы. Кроме того, это означает, что запросы выполняются лучше при втором запуске. При первом выполнении запроса данные считываются из уровня хранилища бизнес-данных в службе хранилища Azure или Azure Data Lake Gen2. Затем данные кэшируются в общем кэше в памяти кластера. При следующем выполнении запроса данные просто извлекаются из общего кэша в памяти, и вы экономите время, не извлекая данные из удаленного хранилища.
Выполнение запросов с помощью популярных средств
Интерактивный запрос упрощает работу с большими данными с помощью знакомых вам средств бизнес-аналитики, например Microsoft Power BI и Tableau. В аналитике больших данных организации все чаще озабочены тем, что их конечные пользователи не получают достаточно пользы от аналитических систем, поскольку часто они слишком сложны и требуют использования незнакомых и трудных в изучении средств для запуска аналитики. Интерактивный запрос HDInsight решает эту проблему, так как новым пользователям не нужно обучение, чтобы получить представление о данных. Пользователи могут писать похожие на SQL запросы HiveQL в тех средствах, которые они уже используют. К этим средствам относятся Visual Studio Code, Power BI, Apache Zeppelin, Visual Studio, представление Hive Ambari, Beeline, Data Analytics Studio и Hive ODBC. Вы не можете выполнять интерактивные запросы к кластеру с помощью консоли Hive, Templeton, классической командной строки Azure или Azure PowerShell.
Требуется согласованность транзакций и параллелизм
С появлением детального управления ресурсами, захвата и распространения кэшированных данных по запросам и пользователям интерактивные вопросы легко поддерживают одновременно несколько пользователей. HDInsight поддерживает создание нескольких кластеров в общей службе хранилища Azure. Хранилище метаданных Hive помогает достичь высокой степени параллелизма. Можно масштабировать параллелизм, добавив дополнительные узлы кластера или дополнительные кластеры, указывающие на те же базовые данные и метаданные. Интерактивный запрос также поддерживает транзакции базы данных, которые являются атомарными, постоянными, изолированными и устойчивыми (ACID). Транзакции ACID гарантируют, что транзакция, даже если она содержит несколько операций, содержится в одном блоке. То есть если какая-то операция в транзакции завершается ошибкой, можно выполнить откат всей операции, что обеспечивает целостность и точность данных.
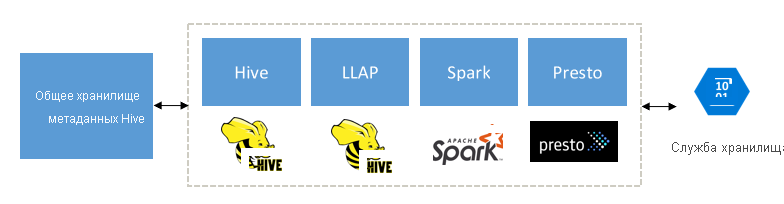
Создан для дополнения Spark, Hive, Presto и других движках работы с большими данными
Интерактивный запрос HDInsight предназначен для работы с популярными движками работы с большими данными, такими как Apache Spark, Hive, Presto и т. д. Этот тип запроса особенно полезен, так как пользователи могут выбрать любое из этих средств для выполнения анализа. Используя общие данные и архитектуру метаданных HDInsight для внешних таблиц, пользователи могут создавать несколько кластеров с тем же или другим движком, указывающим на те же базовые данные и метаданные. Эта функциональность дает очень много возможностей, так как вы больше не ограничены одной технологией для аналитики.