Упражнение. Потоковая передача данных Kafka в записную книжку Jupyter и определение окна для данных
Теперь кластер Kafka записывает данные в свой журнал, который можно обработать с помощью структурированной потоковой передачи Spark.
Записная книжка Spark включена в клонированный пример, поэтому для его использования необходимо передать эту записную книжку в кластер Spark.
Отправка записной книжки Python в кластер Spark
На портале Azure выберите "Главная" > "Кластеры HDInsight", а затем выберите только что созданный кластер Spark (не кластер Kafka).
В области "Информационные панели кластера" щелкните "Записная книжка Jupyter".
При появлении запроса на ввод учетных данных введите admin в качестве имени пользователя, а также пароль, указанный при создании кластеров. Отобразится веб-сайт Jupyter.
Щелкните PySpark, а затем на странице PySpark нажмите кнопку Upload (Отправить).
Перейдите в папку, в которую был скачан пример из GitHub, выберите файл RealTimeStocks.ipynb, а затем нажмите кнопку Open (Открыть), нажмите Upload (Отправить), а затем и нажмите кнопку "Обновить" в браузере.
После отправки записной книжки в папку PySpark щелкните RealTimeStocks.ipynb, чтобы открыть записную книжку в браузере.
Выполните первую ячейку в записной книжке, поместив курсор в ячейку, а затем нажав клавиши SHIFT + ВВОД, чтобы выполнить ячейку.
На успешное выполнение ячейки Настройка библиотек и пакетов указывают сообщения Starting Spark application (Запуск приложения Spark) и дополнительные сведения, как показано в следующем снимке экрана.
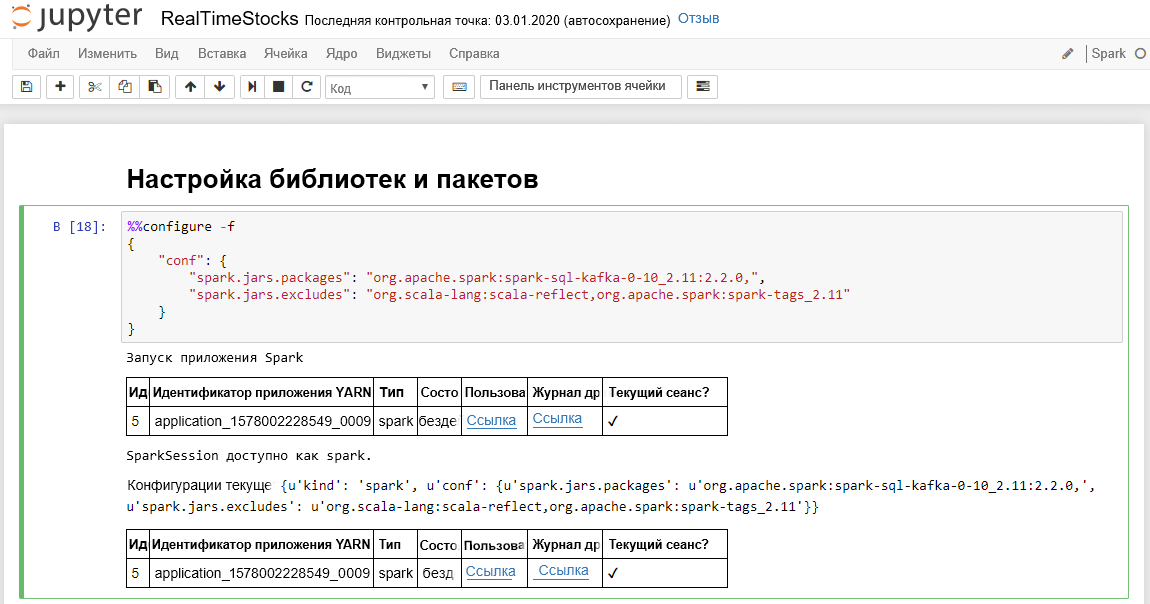
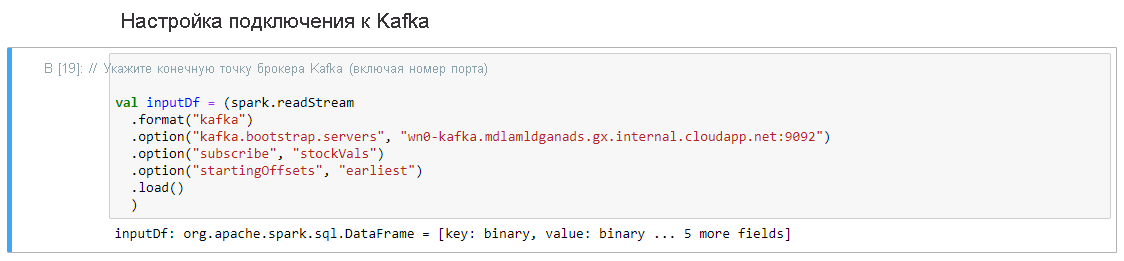
В ячейке Настройка подключения к Kafka в строке.option("kafka.bootstrap.servers", "") введите брокер Kafka между вторым набором кавычек. Например, .option("kafka.bootstrap.servers", "wn0-kafka.mdlamldganads.gx.internal.cloudapp.net:9092"), а затем нажмите клавиши SHIFT + ВВОД, чтобы выполнить ячейку.
Настройка подключения к ячейке Kafka завершается успешно при отображении входных данных сообщения: org.apache.spark.sql.DataFrame = [ключ: двоичное, значение: двоичное... 5 дополнительных полей]. Для чтения данных Spark использует API readStream.
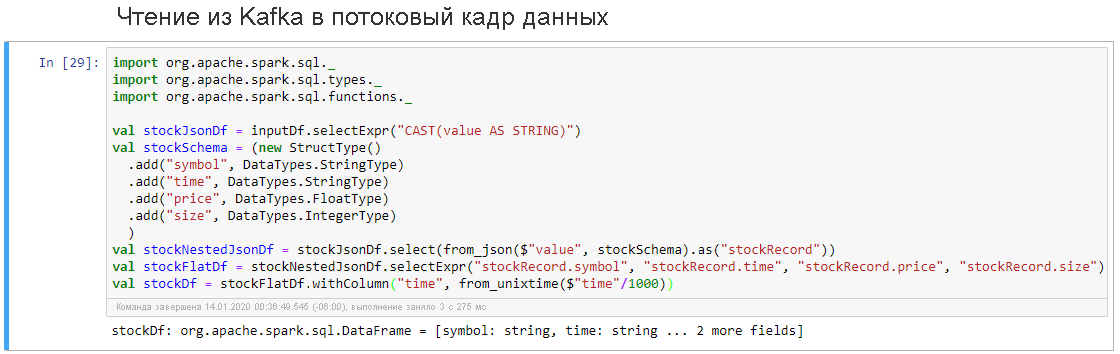
Выберите ячейку Чтение из Kafka в потоковый кадр данных, а затем нажмите клавиши SHIFT + ВВОД, чтобы выполнить ячейку.
На успешное выполнение ячейки указывает следующее сообщение: stockDf: org.apache.spark.sql.DataFrame = [symbol: string, time: string ... 2 more fields]
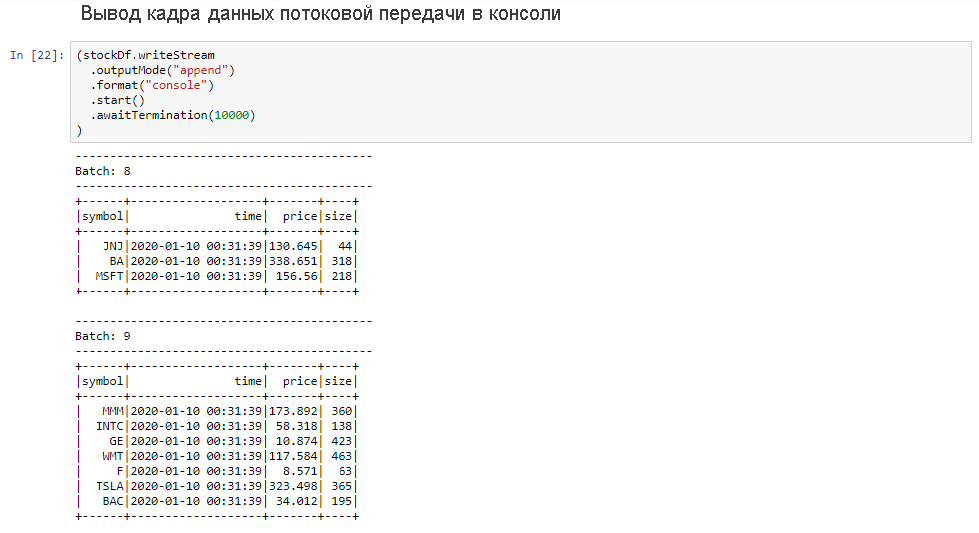
Выберите ячейку Вывод потокового кадра данных в консоль, а затем нажмите клавиши SHIFT + ВВОД, чтобы выполнить ячейку.
На успешное выполнение этой ячейки указывают сведения, аналогичные приведенным ниже. В выходных данных отображается значение для каждой ячейки в том виде, в каком оно было передано в микропакете, — один пакет в секунду.
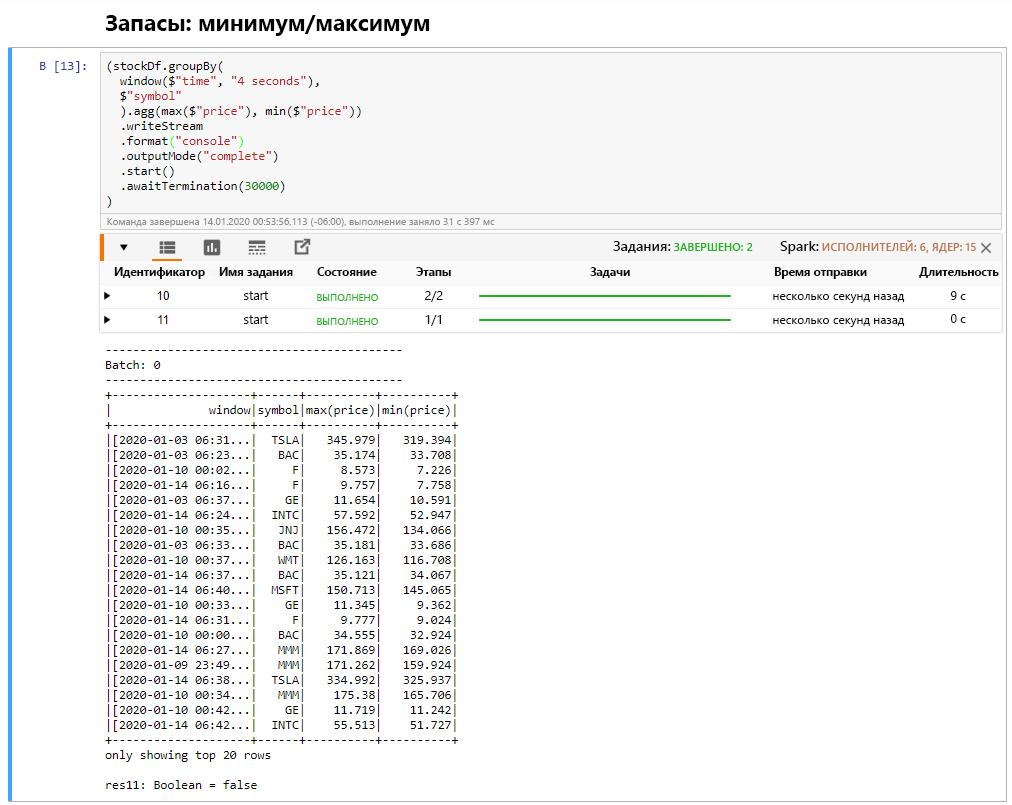
Выберите ячейку "Минимум/максимум акции в окне", а затем нажмите клавиши SHIFT + ВВОД, чтобы выполнить ячейку.
На успешное выполнение ячейки указывает отображение максимальной и минимальной цены за каждую акцию в четырехсекундном окне, которое определено в ячейке. Как обсуждалось ранее, предоставление сведений о конкретных окнах времени является одним из преимуществ структурированной потоковой передачи Spark.
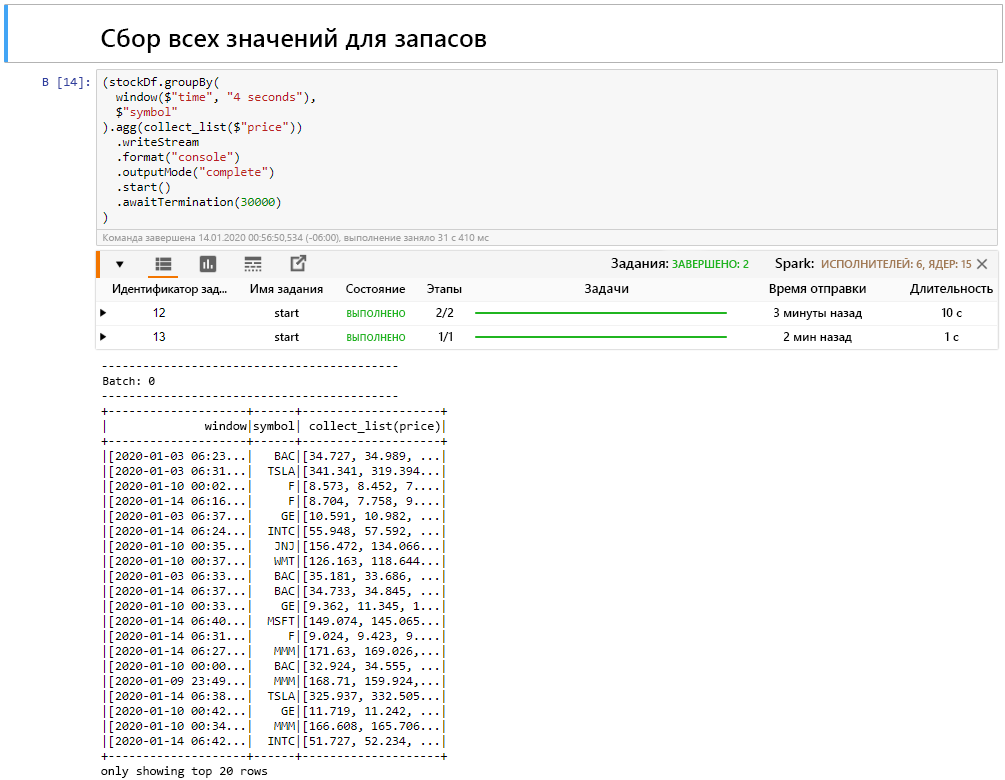
Выберите ячейку "Сбор всех значений акций в окне", а затем нажмите клавиши SHIFT + ВВОД, чтобы выполнить ячейку.
На успешное выполнение ячейки указывает отображение таблицы значений для акций. Для параметра outputMode указано complete, поэтому отображаются все данные.
В этом уроке вы отправили записную книжку Jupyter в кластер Spark, подключили ее к кластеру Kafka, вывели потоковые данные, созданные с помощью файла производителя Python, в записную книжку Spark, определили окно для потоковых данных и отобразили высокие и низкие цены на акции в этом окне, а также вывели все значения цены на акции в виде таблицы. Поздравляем! Вы успешно выполнили структурированную потоковую передачу с помощью Spark и Kafka!