Потоковая передача данных с помощью Apache Kafka
Платформа Apache Kafka была создана компанией LinkedIn в 2010 году с целью перемещения данных в очень большом масштабе, с очень низкой задержкой и с высоким уровнем отказоустойчивости. Затем LinkedIn передала проект организации Apache в 2012 году, однако LinkedIn по-прежнему использует Kafka в своей экосистеме для отслеживания активности пользователей, обмена сообщениями и сбора метрик.
Kafka — это платформа распределенной потоковой передачи, предназначенная для следующего:
- упрощение конвейеров данных;
- работа с большими объемами данных для потоковой передачи;
- поддержка систем обработки в режиме реального времени и пакетной обработки;
- массовое горизонтальное увеличение масштаба.
Давайте сначала изучим исключительно Apache Kafka, а затем Kafka в Azure HDInsight.
Компоненты Kafka
Прежде чем понять, как работает Kafka, рассмотрим роли некоторых ключевых компонентов Kafka и их взаимодействие для обеспечения высокомасштабируемой и отказоустойчивой системы обмена сообщениями.
Broker
Kafka — это кластеризованная служба, а отдельный кластер Kafka называется брокером. Брокеры получают сообщения от производителей и сохраняют эти сообщения на диске. Брокер также отвечает на запросы получения от потребителей. В кластере брокеров один брокер выступает в качестве контроллера и отвечает за административные операции и назначение секций брокерам.
Сообщение
Единица данных в кластере Kafka. В большинстве случаев сообщения являются парами "ключ — значение".
Темы и разделы
Темы и разделы — это категории сообщений в Kafka. Темы, как правило, разбиваются на несколько разделов, что позволяет улучшить структуру (минимальное количество разделов составляет три). Сообщения записываются в раздел темы только путем добавления. Затем разделы реплицируются между несколькими брокерами для повышения избыточности в случае сбоя брокера. Благодаря разделам темы можно читать параллельно, поскольку они позволяют разбивать данные между несколькими брокерами. Имеется ведущая реплика, которая обрабатывает все запросы на чтение и запись. Последующие реплики создаются из ведущей реплики. В случае сбоя ведущей реплики одна из реплик берет на себя эту роль.
Производители и потребители
Производители и потребители — это клиенты, которые создают и потребляют сообщения из системы Kafka. Производители публикуют новые сообщения и направляют их в конкретную тему. Потребители также могут выполнять запись в конкретный раздел темы. Потребители, в свою очередь, подписываются на одну или несколько тем и читают сообщения из них.
Группа потребителей
Один или несколько потребителей могут работать совместно как группа и получать сообщения в качестве группы. Если число потребителей равно числу разделов темы, каждый потребитель получает из одного раздела темы для создания параллелизма.
Хранение
Сообщения в Kafka могут надежно храниться в кластере Kafka в течение заданного периода времени. По достижении предельного срока хранения Kafka может удалить эти сообщения.
Смещение
Смещение — это просто позиция сообщения в разделе. Обновление текущей позиции в разделе по мере обработки сообщений называется фиксацией. После обработки сообщения Kafka фиксирует смещение сообщения в специальном внутреннем разделе Kafka. Когда производитель публикует сообщение в разделе, он перенаправляется в ведущую реплику. Ведущая реплика добавляет сообщение в журнал фиксации и увеличивает смещение сообщения. Смещение сообщения — это способ идентификации сообщений в разделе. Сообщение доступно потребителю только после того, как оно было зафиксировано в кластере.
Zookeeper
Zookeeper — это служба координации. В кластере Kafka служба Zookeeper предоставляет синхронизированное представление состояния кластера. Kafka использует Zookeeper для выбора ведущей реплики среди брокеров и разделов темы. Кроме того, Kafka использует Zookeeper для управления обнаружением служб для брокеров Kafka, образующих кластер. Zookeeper отправляет изменения топологии в Kafka, поэтому каждый узел в кластере знает о присоединении нового брокера, удалении брокера, удалении или добавлении темы.
Как все это работает?
Приложения (также называемые производителями) отправляют сообщения брокеру Kafka, после чего эти сообщения обрабатываются одним или несколькими потребителями. Сообщения в кластере классифицируются по темам. Например, клиент может создать тему "Продажи" для отправки всех сообщений, касающихся продаж, и т. д. Поскольку с увеличением количества сообщений размер тем также увеличивается, они разбиваются на разделы, и эти разделы в дальнейшем реплицируются между брокерами Kafka для обеспечения избыточности. Разделы классифицируются как ведущие реплики и последующие реплики. Ведущая реплика раздела используется для записи и чтения, а последующие реплики раздела — это просто реплики, которые дублируют состояние ведущей реплики. Чтобы определить раздел для чтения и записи, производители и потребители должны знать, какие разделы назначены ведущими репликами. Узлы Zookeeper управляют состоянием кластера Kafka, а также выбирают ведущие реплики разделов и предоставляют эти сведения производителям и потребителям.
Kafka предоставляет гарантии того, что порядок сообщений в разделе соответствует порядку, в котором они были созданы. Конкретное сообщение можно определить с помощью его смещения, которое является его позицией в разделе. Потребитель считывает сообщения из разделов и постобработки, фиксирует смещение, указывающее на то, что сообщение успешно обработано. Kafka хранит все записи на диске и обеспечивает сохранность сообщений. Если потребитель был прерван по какой-либо причине и обработка была прекращена, Kafka хранит такие сообщения в течение предварительно заданного срока хранения. После восстановления работы потребитель может перезапустить обработку с зафиксированного смещения, где она была остановлена до прерывания.
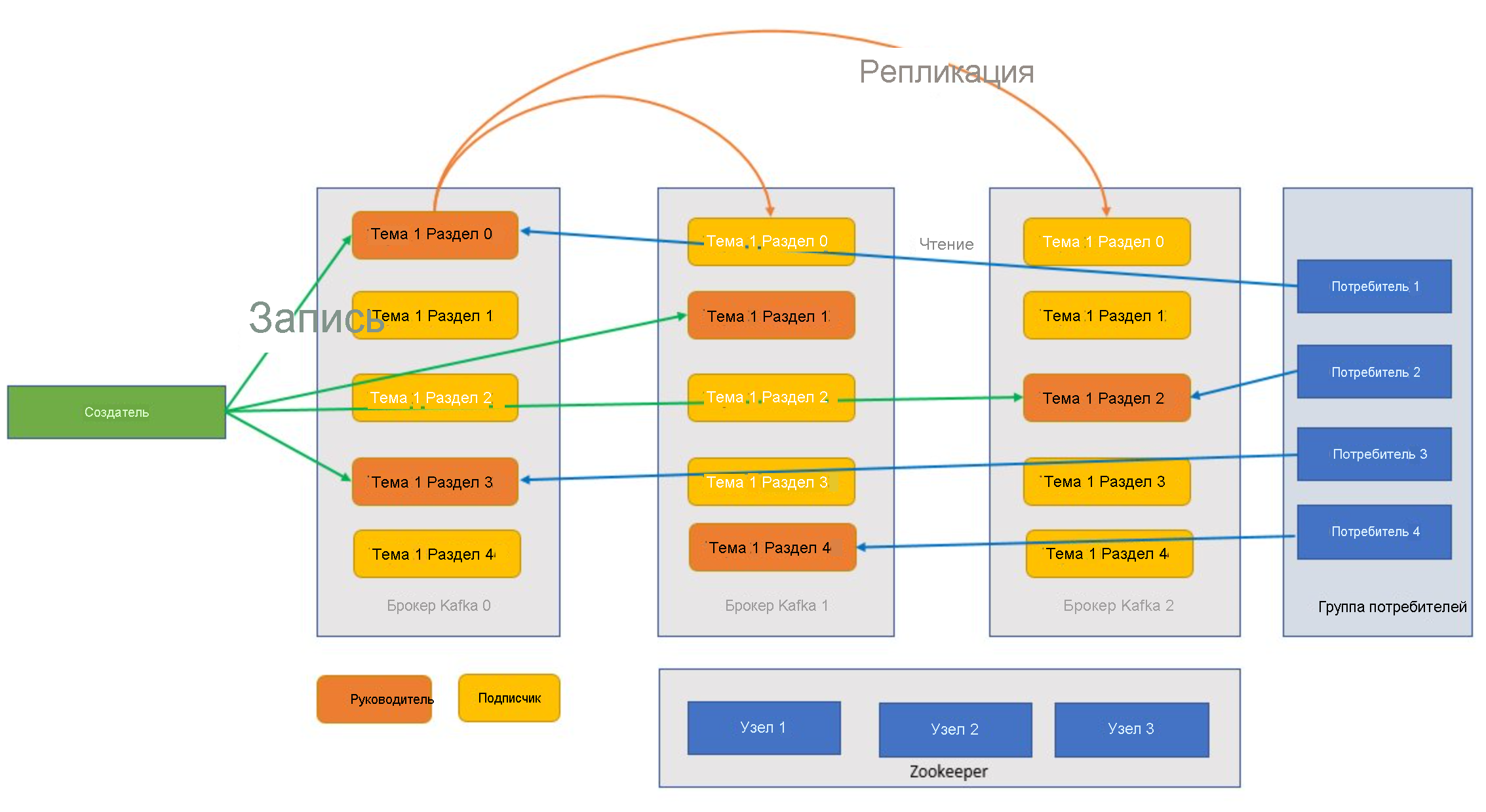
Темы Kafka
Тема Kafka — это веб-канал или очередь, в которой хранятся и публикуются сообщения. Производители отправляют сообщения в темы, а потребители считывают их из тем. Каждый узел в брокере Kafka может содержать несколько тем.
Каковы преимущества использования Kafka в Azure HDInsight?
Версия Kafka с открытым исходным кодом предоставляет множество возможностей, однако для ее настройки придется приложить немало усилий. Azure HDInsight позволяет использовать в Azure лучшие платформы аналитики с открытым исходным кодом и упрощает для клиентов настройку их кластеров с открытым исходным кодом, которая занимает считаные минуты, а не недели или месяцы. Кроме того, они доступны для использования немедленно. HDInsight также является службой корпоративного пользования благодаря следующим преимуществам.
- Это управляемая служба, которая упрощает процесс настройки. Она создает конфигурацию, проверенную и поддерживаемую корпорацией Майкрософт.
- Корпорация Майкрософт предоставляет для Spark и Kafka Соглашение об уровне обслуживания (SLA), подразумевающее доступность этих компонентов в течение 99,9 % времени.
- В качестве резервного хранилища для Kafka используются управляемые диски Azure. Управляемые диски могут обеспечить до 16 ТБ хранилища для каждого брокера Kafka, а также возможность использовать несколько брокеров Kafka.
- HDInsight обеспечивает лучшую безопасность на уровне предприятия с помощью виртуальных сетей, детальную настройку безопасности с помощью Apache Ranger и шифрование BYOK для неактивных данных.
- Соответствие требованиям HIPAA, SOC и PCI.
- Возможность развертывания сквозных конвейеров потоковой обработки данных с помощью Spark и службы хранилища посредством автоматизированных шаблонов Azure Resource Manager (ARM) в той же виртуальной сети.
- Высокая доступность может быть достигнута с помощью компонента Kafka MirrorMaker, который может использовать записи из тем основного кластера, а затем создавать локальную копию во вторичном кластере.
- HDInsight позволяет изменить количество рабочих узлов (в которых размещается брокер Kafka) после создания кластера. Масштабирование можно выполнить на портале Azure, в Azure PowerShell и других интерфейсах управления Azure. Для Kafka выполните повторную балансировку реплик секций после масштабирования. Балансировка секций позволяет Kafka пользоваться преимуществами нового количества рабочих узлов.
- Журналы Azure Monitor можно использовать для мониторинга Kafka в HDInsight. Журналы Azure Monitor предоставляют сведения уровня виртуальной машины, такие как метрики диска и сетевой карты, а также метрики JMX из Kafka.