Выбор подходящей библиотеки MPI
Номера SKU HB120_v2, HB60 и HC44 поддерживают сетевые соединения InfiniBand. Так как интерфейс PCI Express виртуализирован с помощью виртуализации Single-Root Input/Output (SR-IOV), все популярные библиотеки MPI (HPCX, OpenMPI, Intel MPI, MVAPICH и MPICH) доступны на этих виртуальных машинах HPC.
Текущее ограничение для кластера HPC, который может обмениваться данными через InfiniBand, составляет 300 виртуальных машин. В приведенной ниже таблице указано максимальное количество параллельных процессов, которое поддерживается в тесно связанных приложениях MPI, взаимодействующих через InfiniBand.
| Номер SKU | Максимальное количество параллельных процессов |
|---|---|
| HB120_v2 | 36 000 процессов |
| HC44 | 13 200 процессов |
| HB60 | 18 000 процессов |
Примечание.
В дальнейшем эти ограничения могут измениться. Если у вас есть тесно связанное задание MPI, для которого требуется более высокий предел, отправьте запрос в службу поддержки. Возможно, в вашей ситуации лимит можно увеличить.
Если для приложения HPC рекомендуется определенная библиотека MPI, сначала попробуйте использовать эту версию. Если у вас есть гибкость в отношении того, какой MPI можно выбрать, и вы хотите лучшей производительности, попробуйте использовать HPCX. В целом HPCX MPI работает лучше всего с платформой UCX для интерфейса InfiniBand и использует все возможности оборудования и программного обеспечения Mellanox InfiniBand.
На следующей иллюстрации сравниваются популярные архитектуры библиотеки MPI.
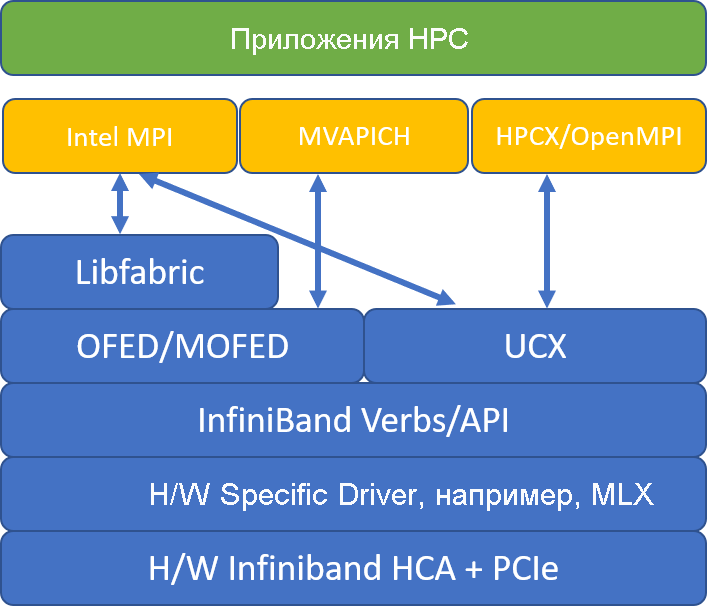
HPCX и OpenMPI совместимы с ABI, поэтому вы можете динамически запускать приложение HPC с помощью средства HPCX, которое было создано, используя OpenMPI. Intel MPI, MVAPICH и MPICH также совместимы с ABI.
Пара очередей 0 недоступна для гостевой виртуальной машины. Это позволяет предотвратить уязвимость системы безопасности вследствие низкоуровневого доступа к оборудованию. Это не должно оказывать влияния на пользовательские приложения HPC, но может препятствовать правильной работе некоторых низкоуровневых средств.
Аргументы mpirun для OpenMPI и HPCX
Следующая команда иллюстрирует некоторые рекомендуемые mpirun аргументы для HPCX и OpenMPI:
mpirun -n $NPROCS --hostfile $HOSTFILE --map-by ppr:$NUMBER_PROCESSES_PER_NUMA:numa:pe=$NUMBER_THREADS_PER_PROCESS -report-bindings $MPI_EXECUTABLE
В этой команде:
| Параметр | Описание |
|---|---|
$NPROCS |
Указывает количество процессов MPI. Например: -n 16. |
$HOSTFILE |
Указывает файл, содержащий имя узла или IP-адрес, чтобы указать расположение, в котором выполняются процессы MPI. Например: --hostfile hosts. |
$NUMBER_PROCESSES_PER_NUMA |
Указывает количество процессов MPI, выполняемых в каждом домене NUMA. Например, чтобы задать четыре процесса MPI для каждого домена NUMA, используйте --map-by ppr:4:numa:pe=1. |
$NUMBER_THREADS_PER_PROCESS |
Указывает количество потоков на процесс MPI. Например, чтобы задать один процесс MPI и четыре потока на каждый домен NUMA, используйте --map-by ppr:1:numa:pe=4. |
-report-bindings |
Выводит значение сопоставления процессов MPI с ядрами. Это полезно для проверки правильности закрепления процесса MPI. |
$MPI_EXECUTABLE |
Указывает встроенную компоновку исполняемого файла MPI в библиотеках MPI. Программы-оболочки компилятора MPI делают это автоматически. Пример: mpicc или mpif90. |
Если есть подозрение, что тесно связанное приложение MPI выполняет чрезмерное количество коллективных коммуникаций, можно попытаться включить Hierarchical Collectives (HCOLL). Чтобы включить эти функции, используйте следующие параметры:
-mca coll_hcoll_enable 1 -x HCOLL_MAIN_IB=<MLX device>:<Port>
Аргументы mpirun для Intel MPI
Выпуск Intel MPI 2019 перешел с платформы Open Fabric Alliance (OFA) на платформу Open Fabric Interfaces (OFI) и сейчас поддерживает libfabric. Существует два поставщика поддержки InfiniBand: mlx и verbs. Поставщик mlx является предпочтительным для виртуальных машин HB и HC.
Ниже приведены некоторые предложенные mpirun аргументы для Intel MPI 2019 с обновлением 5+:
export FI_PROVIDER=mlx
export I_MPI_DEBUG=5
export I_MPI_PIN_DOMAIN=numa
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
В этих аргументах:
| Параметры | Описание |
|---|---|
FI_PROVIDER |
Указывает, какой поставщик libfabric следует использовать, который влияет на используемый API, протокол и сеть.
verbs является еще одним вариантом, но обычно mlx обеспечивает лучшую производительность. |
I_MPI_DEBUG |
Указывает уровень дополнительных отладочных выходных данных, которые могут содержать сведения о том, где закреплены процессы и какие протокол и сеть используются. |
I_MPI_PIN_DOMAIN |
Указывает способ закрепления процессов. Например, за ядрами, сокетами или доменами NUMA. В этом примере вы установите для этой переменной numaсреды значение , что означает, что процессы закреплены к доменам узлов NUMA. |
Существуют и другие варианты, которые можно использовать, особенно если коллективные операции занимают значительное время. Intel MPI 2019 с обновлением 5+ поддерживает указанный mlx и использует платформу UCX для взаимодействия с InfiniBand. Он также поддерживает HCOLL.
export FI_PROVIDER=mlx
export I_MPI_COLL_EXTERNAL=1
Аргументы mpirun для MVAPICH
Следующий список содержит несколько рекомендуемых mpirun аргументов:
export MV2_CPU_BINDING_POLICY=scatter
export MV2_CPU_BINDING_LEVEL=numanode
export MV2_SHOW_CPU_BINDING=1
export MV2_SHOW_HCA_BINDING=1
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
В этих аргументах:
| Параметры | Описание |
|---|---|
MV2_CPU_BINDING_POLICY |
Указывает используемую политику привязки, которая влияет на то, как процессы закрепляются за основными идентификаторами. В этом случае указывается scatter, поэтому процессы равномерно разбросаны между доменами NUMA. |
MV2_CPU_BINDING_LEVEL |
Указывает, где следует закреплять процессы. В этом случае вы задаете значение numanode, то есть процессы закрепляются за элементами доменов NUMA. |
MV2_SHOW_CPU_BINDING |
Указывает, необходимо ли получать отладочные сведения о том, где закреплены процессы. |
MV2_SHOW_HCA_BINDING |
Указывает, необходимо ли получать отладочные сведения о том, какой хост-адаптер канала используется каждым процессом. |