Объединение и оптимизация данных
Организации часто сопоставляют различные типы информации из многих источников. Сведения хранятся в большом количестве таблиц. Иногда может потребоваться присоединить таблицы на основе логических связей между ними для более глубокого анализа или создания отчетов. В сценарии розничной компании вы используете таблицы для клиентов, продуктов и сведений о продажах.
В этом модуле вы узнаете о различных способах объединения данных в запросах Kusto, чтобы предоставить участникам команды информацию, необходимую для повышения осведомленности о продуктах и роста продаж.
Поймите ваши данные
Прежде чем приступать к написанию запросов, которые объединяют информацию из таблиц, необходимо понять данные. При работе с запросами Kusto необходимо думать о таблицах как о одной из двух категорий:
- таблицы фактов: таблицы, записи которых неизменяемы факты, такие как таблица SalesFact в сценарии розничной компании. В этих таблицах записи добавляются либо постепенно в порядке потока, либо большими блоками. Записи остаются в таблице до тех пор, пока они не будут удалены, и они никогда не обновляются.
- таблицы размерностей: таблицы, в которых записи являются изменяемыми размерности, например, таблицы Клиентов и Продуктов в сценарии розничной торговли. Эти таблицы содержат справочные данные, такие как таблицы подстановки от идентификатора сущности к его свойствам. Таблицы измерений регулярно не обновляются с новыми данными.
В нашем сценарии розничной компании вы используете таблицы измерений для обогащения таблицы SalesFact дополнительными сведениями или для предоставления дополнительных возможностей фильтрации данных для запросов.
Вы также хотите понять объемы данных, с которыми вы работаете, и ее структуру, или схему (имена столбцов и типы). Чтобы получить эти сведения, можно выполнить следующие запросы, заменив TABLE_NAME именем проверяемой таблицы:
Чтобы получить количество записей в таблице, используйте оператор
count:TABLE_NAME | countЧтобы получить схему таблицы, используйте оператор
getschema:TABLE_NAME | getschema
Выполнение этих запросов на таблицы фактов и измерений в сценарии розничной компании дает сведения, как показано в следующем примере:
| Стол | Записи | Схема |
|---|---|---|
| SalesFact | 2,832,193 | — SalesAmount (real) - ОбщаяСтоимость (вещественное число) — DateKey (datetime) - ProductKey (long) - CustomerKey (long) |
| Клиенты | 18,484 | — CityName (строка) — CompanyName (string) — НазваниеКонтинента (строка) - CustomerKey (long) — Образование (строка) — FirstName (string) - Пол (строка) - LastName (string) - Состояние в браке (string) — профессия (строка) — RegionCountryName (строка) — имя штата или провинции (строка) |
| Продукция | 2,517 | — ProductName (строка) - Производитель (строка) — ColorName (строка) — ClassName (строка) — ProductCategoryName (строка) — ИмяПодкатегорииПродукта (строка) - ProductKey (длинный) |
В таблице выделены уникальные идентификаторы CustomerKey и ProductKey, которые используются для объединения записей между таблицами.
Понимание запросов с несколькими таблицами
После анализа данных необходимо понять, как объединить таблицы для предоставления необходимых сведений. Запросы Kusto предоставляют несколько операторов, которые можно использовать для объединения данных из нескольких таблиц, включая операторы lookup, joinи union.
Оператор join объединяет строки двух таблиц путем сопоставления значений указанных столбцов из каждой таблицы. Результирующая таблица зависит от типа используемого соединения. Например, если используется внутреннее соединение, таблица имеет те же столбцы, что и левая таблица (иногда называемая внешней таблицей), а также столбцы из правой таблицы (иногда называются внутренней таблицей). Дополнительные сведения о типах присоединения см. в следующем разделе. Для повышения производительности, если одна таблица всегда меньше другой, используйте ее в качестве левой стороны оператора join.
Оператор lookup — это специальная реализация оператора join, который оптимизирует производительность запросов, в которых таблица фактов обогащена данными из таблицы измерений. Она расширяет таблицу фактов значениями, которые подбираются из таблицы измерений. Для оптимальной производительности система по умолчанию предполагает, что левая таблица является большей (факт) таблицей, а правая — меньшей (измерения). Это предположение является именно противоположностью допущения, используемого оператором join.
Оператор union возвращает все строки из двух или более таблиц. Полезно, если требуется объединить данные из нескольких таблиц.
Функция materialize() кэширует результаты выполнения запроса для последующего повторного использования в запросе. Это похоже на создание снимка результатов подзапроса и их многократное использование в основном запросе. Эта функция полезна при оптимизации запросов для сценариев, в которых результаты:
- Затраты на вычисление
- Недетерминированные
Вскоре вы узнаете больше о различных операторах объединения таблиц и функции materialize() и их использовании.
Виды соединения
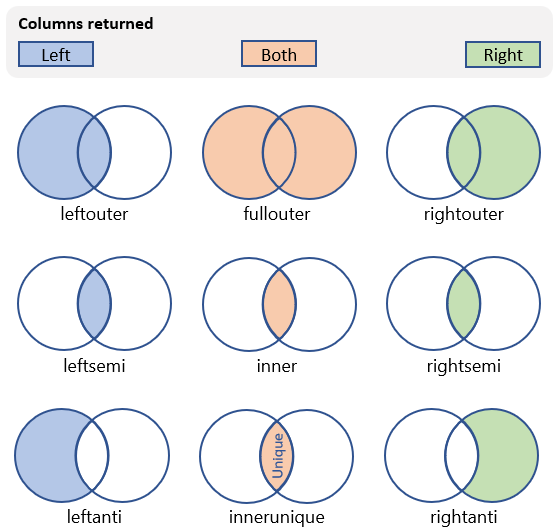
Существует множество различных типов соединений, которые могут быть выполнены, влияющие на схему и строки в результирующей таблице. В следующей таблице показаны типы соединений, поддерживаемые языком запросов Kusto и схемой и строками, которые они возвращают:
| Тип соединения | Описание | Иллюстрация |
|---|---|---|
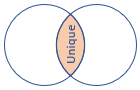
innerunique (по умолчанию) |
Внутреннее соединение с дедупликацией на левой стороне Схема : все столбцы из обеих таблиц, включая соответствующие ключи строк: все дедупликированные строки из левой таблицы, соответствующие строкам из правой таблицы. |
|
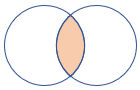
inner |
Стандартное внутреннее соединение схема: все столбцы из обеих таблиц, включая соответствующие ключи строки: только соответствующие строки из обеих таблиц |
|
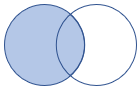
leftouter |
Левое внешнее соединение Схема: все столбцы из обеих таблиц, включая соответствующие ключи строки: все записи из левой таблицы и только соответствующие строки из правой таблицы |
|
rightouter |
Правое внешнее соединение схема: все столбцы из обеих таблиц, включая соответствующие ключи строки: все записи из правой таблицы и только соответствующие строки из левой таблицы |
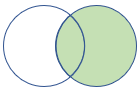
|
fullouter |
Полное внешнее соединение Схема: все столбцы из обеих таблиц, включая совпадающие ключи строки: все записи из обеих таблиц с несовпадными ячейками, заполненными значением NULL |
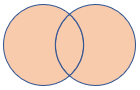
|
leftsemi |
Левое полусоединяние Схема : все столбцы из таблицы слева строк: все записи из левой таблицы, соответствующие записям из правой таблицы. |
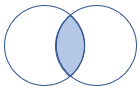
|
leftanti, anti, leftantisemi |
Левый антисоединяние и полу-вариант Схема: все столбцы из левой таблицы строки: все записи из левой таблицы, которые не соответствуют записям из правой таблицы. |
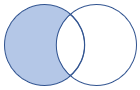
|
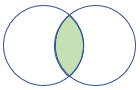
rightsemi |
Правое полусоединяние Схема: Все столбцы из правой таблицы строки: все записи из правой таблицы, соответствующие записям из левой таблицы. |
|
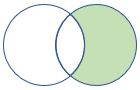
rightanti, rightantisemi |
Правый антисоединяние и полу-вариант схема: все столбцы из правой таблицы строки: все записи из правой таблицы, не соответствующие записям из левой таблицы |
|
Обратите внимание, что тип соединения по умолчанию innerunique, и его не нужно указывать. Тем не менее, рекомендуется всегда явно указывать тип соединения для ясности.
По мере выполнения этого модуля вы также узнаете о функциях агрегирования arg_min() и arg_max(), оператор as в качестве альтернативы инструкции let и функции startofmonth(), чтобы помочь с группировкой данных по месяцам.