Что такое Azure HDInsight?
Рассмотрим возможности и варианты применения HDInsight. Этот обзор поможет оценить, соответствует ли HDInsight требованиям вашей организации.
Что такое большие данные?
Термин большие данные описывает большие объемы собираемых организациями структурированных и неструктурированных данных. Эти данные могут приносить компаниям значительную пользу. В частности, если организация способна анализировать данные и извлекать полезные сведения, она может принимать на их основе более эффективные решения, добиваясь таким образом большего успеха. Например, коммерческая организация может анализировать большие данные для выявления привычек клиентов и повышения объемов продаж.
Описание Azure HDInsight
Azure HDInsight — это полностью управляемая облачная служба аналитики с открытым кодом для предприятий. HDInsight помогает упорядочивать и контролировать ваши большие данные и имеет следующие особенности.
Решение представляет собой облачный дистрибутив компонентов Hadoop.
Оно упрощает, ускоряет и удешевляет обработку огромных объемов данных.
Обеспечивается поддержка следующих платформ с открытым кодом:
- Hadoop
- Apache Spark
- Apache Hive
- Apache Kafka
Примечание.
С помощью этих платформ можно реализовать различные сценарии, такие как извлечение, преобразование и загрузка, хранение данных, машинное обучение и Интернет вещей.
HDInsight дает организациям, работающим с большими данными, ряд преимуществ, в том числе:
Open-source: позволяет создавать оптимизированные кластеры для различных платформ с открытым кодом.
Надежная: предоставляет комплексное соглашение об уровне обслуживания для всех рабочих нагрузок.
Масштабируемость. Позволяет масштабировать рабочие нагрузки для реагирования на изменения спроса.
Совет
Вы можете сэкономить, создавая кластеры по запросу. и внося оплату только за используемые ресурсы.
Безопасный: позволяет защитить корпоративные ресурсы данных с помощью интеграции с:
- Виртуальная сеть Azure
- Технологии шифрования Azure. Защита персональных данных при передаче с помощью шифрования
- Microsoft Entra ID
Соответствует требованиям: соответствует популярным отраслевым и государственным стандартам соответствия.
Отслеживаемое: интегрируется с журналами Azure Monitor для предоставления единого интерфейса. Используйте единый интерфейс для отслеживания всех своих кластеров.
Как HDInsight помогает работать с большими данными
HDInsight можно использовать для самых разных сценариев обработки больших данных. Поддерживаются данные двух видов:
- Исторические данные: эти данные уже собираются и хранятся.
- Данные в режиме реального времени: эти данные передаются непосредственно из источника.
Можно выделить следующие категории сценариев обработки этих данных:
- Пакетная обработка
- Хранение данных
- IoT
- Обработка и анализ данных
- Гибридный трафик
Давайте рассмотрим эти категории более подробно.
Пакетная обработка
Организации используют задания пакетной обработки для подготовки больших данных к дальнейшему анализу. Как правило, этот процесс состоит из трех этапов:
- Чтение исходных файлов данных из разнородных источников данных.
- Обработка данных.
- Запись данных в масштабируемое хранилище.
Примечание.
Этот процесс часто называется извлечение, преобразование и загрузка.
Преобразованные данные могут помещаться в хранилище данных или использоваться для обработки и анализа и данных.
Совет
Существенным требованием для извлечения, преобразования и загрузки является горизонтальное увеличение масштаба вычислений. Это позволяет обрабатывать большие объемы данных.
Хранение данных
Хранилище данных предоставляет организации возможность хранить большие данные до их анализа. Хранение данных позволяет:
- Хранение данных.
- Подготовка данных для анализа.
- Предоставление подготовленных данных в структурированном формате. Затем можно запрашивать данные с помощью средств аналитики.
На следующей схеме показано, как Apache Hadoop в HDInsight собирает и хранит данные из нескольких источников. Apache Spark и Apache Hive готовят и анализируют данные. Наконец, данные моделируются для использования с инструментами бизнес-аналитики (BI). Power BI используется для визуализации данных.
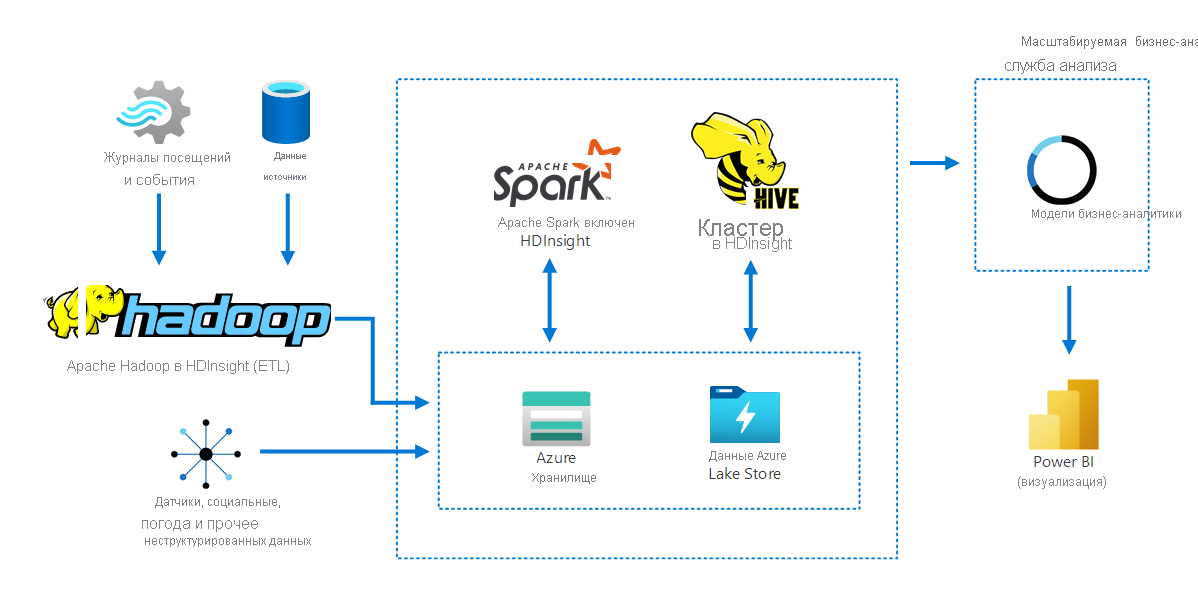
Компоненты этого сценария:
- Apache Spark — это платформа параллельной обработки. Apache Spark поддерживает обработку в памяти, что повышает производительность приложений для анализа больших данных.
- Apache Hive в HDInsight — это система хранилища данных для Apache Hadoop. Hive включает формирование сводных данных, запросы и анализ. При помощи этих компонентов вы можете запрашивать структурированные и неструктурированные данные в любом формате и объемом в несколько петабайт.
Совет
Запросы Hive создаются на языке запросов HiveQL, который похож на SQL.
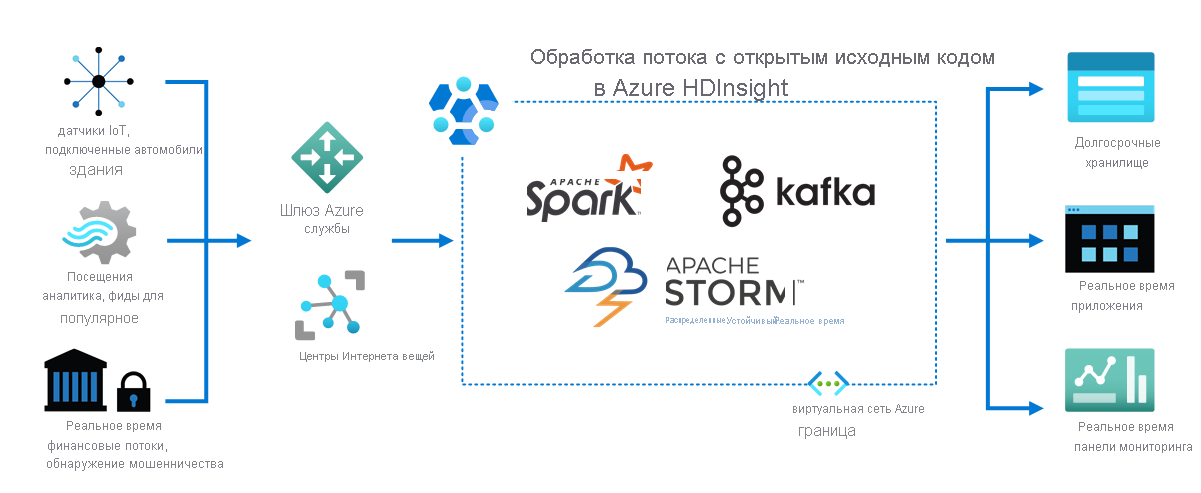
Интернет вещей
Как показано на следующей схеме, HDInsight обрабатывает потоковые данные, полученные в режиме реального времени с различных устройств и датчиков. В этом примере несколько платформ с открытым кодом обеспечивают потоковую обработку, в том числе Apache Spark и Apache Kafka.
Службы шлюза Azure и центры Интернета вещей направляют данные из различных источников в эти платформы. Затем платформы обрабатывают данные, и они передаются в следующие ресурсы:
- долговременное хранение;
- Приложения в режиме реального времени.
- Панель мониторинга в реальном времени.
Обработка и анализ данных
HDInsight можно использовать для выполнения общих задач обработки и анализа данных, таких как:
- Прием данных.
- проектирование признаков;
- Моделирование.
- Оценка модели.
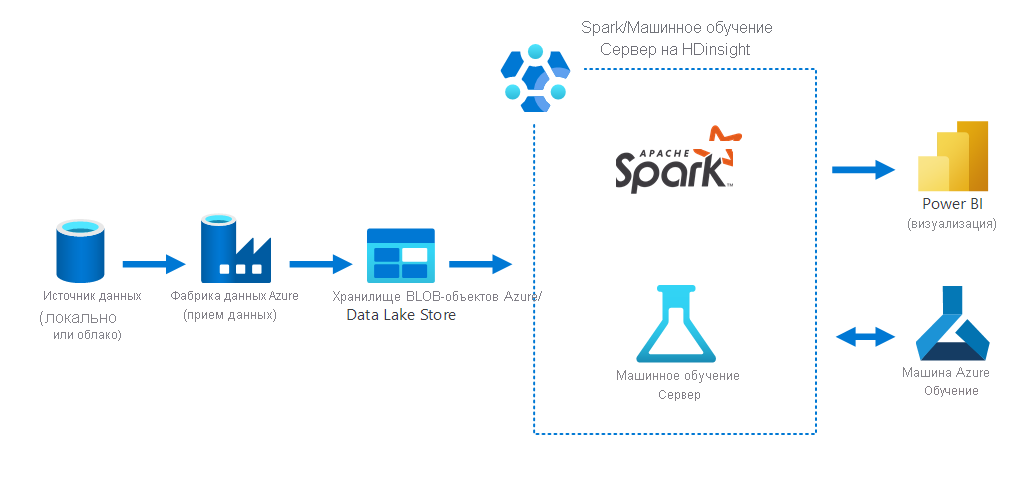
На следующей схеме показан сценарий обработки и анализа данных, в котором:
- данные собираются из локального источника данных с помощью Фабрики данных Azure;
- принятые данные затем хранятся в хранилище Azure (хранилище BLOB-объектов Azure или Data Lake Store).
- Azure Spark в HDInsight обрабатывает и готовит данные для Машинного обучения Azure. Для визуализации данных также используется Power BI.
Гибридный трафик
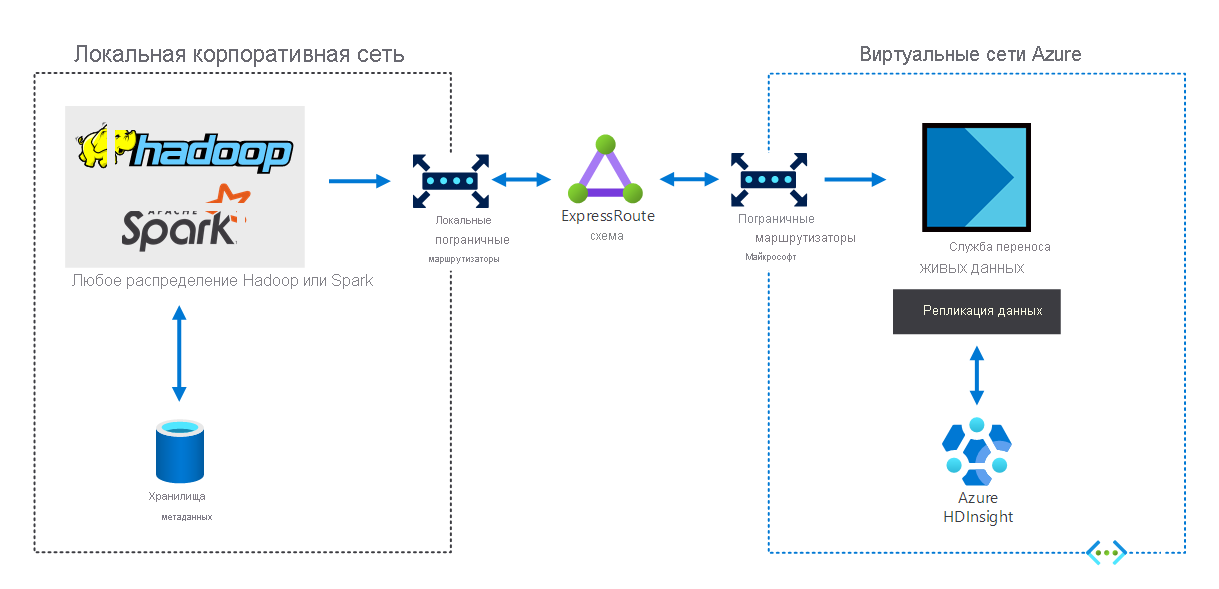
Организации, имеющие локальную инфраструктуру больших данных, могут использовать HDInsight для расширения в Azure. Благодаря этому вы можете воспользоваться преимуществами функций расширенной аналитики в облаке Azure. На следующей схеме показан гибридный сценарий, в котором:
- локальная инфраструктура больших данных состоит из хранилищ метаданных, а также дистрибутива Hadoop или Spark на локальных виртуальных машинах;
- канал ExpressRoute Azure подключает локальную корпоративную сеть к виртуальным сетям Azure;
- динамическое средство миграции данных для Azure реплицирует данные, полученные из локальной среды в HDInsight.