Принцип работы Azure Data Explorer
В этом уроке мы рассмотрим, как Azure Data Explorer работает за кулисами, обсудив основные компоненты системы. Затем вы узнаете, как взаимодействовать со службой, изучая общий рабочий процесс:
- Прием данных
- Kusto Query Language — язык запросов Kusto
- Визуализация данных
Эти знания помогут вам решить, подходит ли Azure Data Explorer для ваших потребностей.
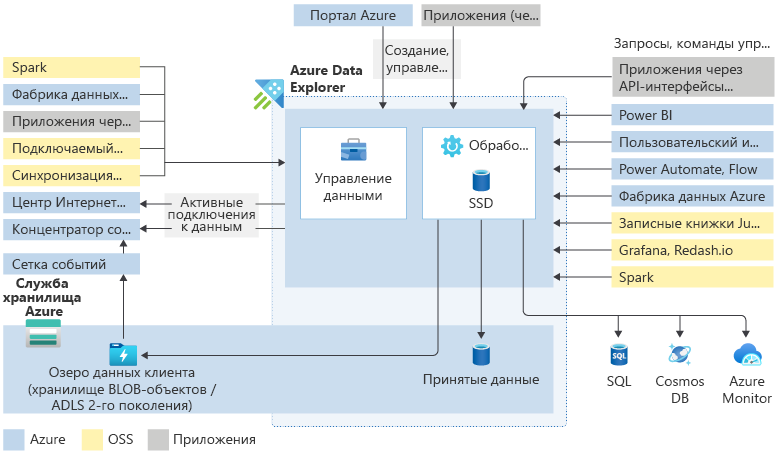
Основные компоненты
Кластер Azure Data Explorer выполняет всю работу по приему, обработке данных и выполнению запросов к ним. Кластеры автоматически масштабируются в соответствии с вашими потребностями. Azure Data Explorer также хранит данные в службе хранилища Azure и кэширует некоторые из этих данных на вычислительных узлах кластера для достижения оптимальной производительности запросов.
Что находится в кластере Azure Data Explorer?
Каждый кластер Azure Data Explorer может содержать до 10 000 баз данных, а каждая база данных — до 10 000 таблиц. Данные в каждой таблице хранятся в сегментах данных, также называемых экстентами. Все данные автоматически индексируются и секционируются на основе времени приема. В отличие от реляционной базы данных, эта система не предусматривает ограничения относительно первичного внешнего ключа или другие ограничения, такие как уникальность. Это означает, что вы можете хранить большие объемы различных данных. И из-за того, как он хранится, вы получаете быстрый доступ к запросу.
Логическая структура базы данных аналогична той, которая имеется у множества других реляционных баз данных. База данных Azure Data Explorer может содержать следующее:
- Таблицы: состоят из набора столбцов. В каждом столбце представлен один из девяти различных типов данных.
- Внешние таблицы: таблицы, базовое хранилище которых находится в других местах, таких как Azure Data Lake.
Знакомство с общим рабочим процессом
Как правило, при взаимодействии с Azure Data Explorer вы проходите следующий рабочий процесс: сначала вы получаете данные, чтобы получить их в системе. Затем вы анализируете данные. Затем вы визуализируете результаты анализа. В любое время вы также можете взаимодействовать с функциями управления данными. Эта работа с Azure Data Explorer осуществляется за счет взаимодействия с кластером. Доступ к этим ресурсам можно получить в пользовательском веб-интерфейсе или с помощью пакетов SDK.
Как передать мои данные в Azure Data Explorer?
Прием данных — это процесс, используемый для загрузки записей данных из одного или нескольких источников в таблицу в Azure Data Explorer. Далее для данных может выполняться сопоставление схемы, упорядочение, индексирование, кодирование и сжатие. Диспетчер данных затем фиксирует прием данных в обработчике, где он становится доступен для запросов.
Помимо мастера собственного веб-интерфейса, доступны различные средства приема. Включая управляемые конвейеры, сетку событий, Центр Интернета вещей и Фабрика данных Azure. Вы можете использовать соединители и подключаемые модули, такие как подключаемый модуль Logstash, соединитель Kafka, Power Automate и соединитель Apache Spark. Можно также использовать программный способ приема данных с помощью пакетов SDK или LightIngest.
Данные можно принимать в двух режимах: пакетном или потоковом. Прием в пакетном режиме оптимизирован для высокой пропускной способности приема и быстрого получения результатов запросов. Потоковый прием данных позволяет уменьшить задержку до близкой к реальному времени для небольших наборов данных в каждой таблице.
Как анализировать мои данные?
Для анализа данных Azure Data Explorer использует собственный язык запросов Kusto (KQL). Она широко используется в Microsoft (Azure Monitor — Log Analytics и Application Insights, Microsoft Sentinel и XDR в Microsoft Defender). KQL оптимизирован для анализа быстро поступающего потока разнообразных больших данных. Запросы ссылаются на таблицы, представления, функции и любые другие табличные выражения. Включая таблицы в разных базах данных или даже кластерах. Запросы можно выполнять с помощью веб-интерфейса, различных средств запросов или с помощью одного из пакетов SDK для Azure Data Explorer.
Как работает язык запросов Kusto?
Язык запросов Kusto — это интуитивно понятный и высокопроизводительный язык запросов с использованием выражений. Он обеспечивает плавный переход от простых однострочных скриптов к сложным сценариям обработки данных, а также поддерживает выполнение запросов к структурированным, частично структурированным и неструктурированным (текстовым) данным. В этом языке запросов есть множество операторов и функций (агрегирование, фильтрация, функции временных рядов, геопространственные функции, соединения, объединения и т. д.). KQL поддерживает запросы между кластерами и между базами данных. Он обеспечивает широкие возможности с точки зрения синтаксического анализа (JSON, XML и т. д.). Кроме того, язык изначально поддерживает расширенную аналитику.
Как можно отобразить результаты запроса?
Пользовательский веб-интерфейс Azure Data Explorer был разработан с учетом больших данных, что позволяет выполнять запросы и создавать панели мониторинга. Она поддерживает отображение до 500-K записей и тысяч столбцов. Он обладает высокой степенью масштабируемости и широкими возможностями, позволяющими быстро получить полезные сведения из данных. Вы также можете использовать различные визуальные отображения данных на панелях мониторинга Azure Data Explorer. Для отображения результатов можно использовать собственные соединители для некоторых ведущих служб визуализации, доступных на сегодня, таких как Power BI и Grafana. Azure Data Explorer также поддерживает соединители ODBC и JDBC для таких инструментов, как Tableau и Qlik.
Как управлять данными?
Администраторы хотят выполнять различные задачи обслуживания и политики в кластерах Azure Data Explorer, а команды управления дают им возможность сделать это. С помощью команд Control они могут создавать новые кластеры или базы данных, устанавливать подключения к данным, выполнять автоматическое масштабирование и настраивать конфигурации кластера. Они также могут контролировать и изменять сущности, объекты метаданных, управлять разрешениями и политиками безопасности. Кроме того, они могут изменять материализованные представления (постоянно обновляемые отфильтрованные представления других таблиц), функции (хранимые функции и определяемые пользователем функции) и политику обновления (функции, активируемые после приема).
Команды управления выполняются непосредственно в подсистеме с помощью веб-интерфейса, портала Azure, различных средств для работы с запросами или одного из пакетов SDK для Azure Data Explorer.