Отслеживание инцидентов
Инциденты имеют жизненный цикл. Чтобы реагировать наиболее эффективно, необходимо иметь возможность отслеживать эволюцию самого инцидента и эволюцию вашего ответа на него с самого начала этого жизненного цикла.
Оценка того, что вы знаете
Хороший способ оценить процедуру отслеживания инцидентов с помощью конкретного инцидента — задать себе ряд вопросов:
- Когда вы впервые узнали о проблеме? Если ваша цель заключается в сокращении времени, необходимого для восстановления от инцидентов, необходимо начать сбор информации с момента, когда вы узнаете о проблемах.
- Как вы узнали о проблеме? Оповещает ли ваша система мониторинга об инциденте? Вы впервые услышали об этом от клиентов, которые жаловались лично или в социальных сетях?
- Узнав о проблеме, вы являетесь первым, кто об этом узнал? Если да, кто вам нужно уведомить? Если нет, кто еще знает о проблеме?
- Если другие знают, то что предпринимается по этому поводу? Предполагает ли каждый, что кто-то другой занимается этим, или уже кто-то начал принимать меры для решения этой проблемы?
- Насколько это плохо? У нас может не быть никакого представления о серьезности или последствиях, и нет возможности узнать, насколько серьезна на самом деле проблема и кто пострадал.
Это могут быть трудные вопросы, чтобы ответить, если ничего не отслеживается.
Установите стандарты для отслеживания информации об инцидентах
Существует множество возможных мест, где можно хранить и где можно поделиться списком инцидентов (активных или неактивных) и всей текущей информацией об этих инцидентах. Это может быть так же просто, как общая папка с документами Word, и такими сложными, как высокоспециализированные программное обеспечение и службы отслеживания инцидентов. Между этими двумя крайностями находятся системы обработки заявок и отслеживания работы, которые можно использовать для этой задачи. Какая система, которую вы выбираете, на самом деле менее важна, чем ее использование. Независимо от того, какая система используется, все, кто может иметь любое подключение ко всем инцидентам (инженеры, специалисты по поддержке клиентов, управлению, связям с общественностью, юридическими и т. д.), должны знать, куда идти, чтобы найти систему, как вызвать инцидент и как получить доступ к данным при необходимости. Один из способов провалить отслеживание инцидентов — это когда люди, которым оно будет помогать, не знают, как зайти в систему ("Какой был URL-адрес для нашей системы?"), когда она им нужна.
В этом модуле мы будем использовать функциональность рабочих элементов Azure DevOps для нашей примера отслеживающей системы.
Создание мостика для общения
Чтобы ответить на некоторые вопросы в предыдущем разделе "Оцените, что вы знаете" и начать процесс реагирования на инциденты, необходимо иметь способ общаться с другими о данном инциденте. В идеале это будет какая-то "командное сотрудничество" электронная платформа для общения, хотя телефонные конференции также работают. Конференц-связи и телефонные мосты менее предпочтительны, потому что сложнее ретроспективно восстановить ход общения во время инцидента, поэтому ранее упоминалась роль "Секретаря".
Независимо от того, какое средство вы выбираете, вы должны быть уверены, что создаете уникальный канал, строго ограниченный для обсуждения этого инцидента и исключительно для этого. Важно избегать неуместных обсуждений в этом канале, потому что вам нужно иметь возможность собирать данные и анализировать их позже в ходе проверки после инцидента.
В этом модуле мы будем использовать Microsoft Teams в качестве метода связи с инцидентами.
Автоматизация запуска отслеживания инцидентов
Итак, давайте рассмотрим части, которые мы собрали до сих пор. У нас есть:
- Список дежурных (и график, определенный для них).
- Роль, которую мы можем назначить людям, работающим над инцидентом.
- Конкретное место, где мы собираемся объявить об инциденте и отслеживать его.
- Уникальный канал для людей, работающих над этим инцидентом, чтобы сообщить об этом.
Вы можете и должны автоматизировать создание и управление всеми этими вещами до максимально возможной степени. При возникновении срочной проблемы вам не хотелось бы вспоминать все шаги, необходимые для подачи инцидента, вовлечения подходящих специалистов и отслеживания процесса. Все, что вы действительно хотите сделать, заключается в том, чтобы иметь возможность нажать кнопку "старт", чтобы работа могла немедленно начать решать проблему.
Использование Logic Apps для автоматизации без кода
Одним из способов автоматизации первоначального ответа является использование Logic Apps, которое может упростить задание планирования, автоматизации и оркестрации задач, бизнес-процессов и рабочих процессов.
Logic Apps — это облачная служба Azure для создания решений интеграции. Он использует соединители для создания автоматизированных рабочих процессов. Триггеры запускают Logic App, когда выполняется определенное событие или когда данные соответствуют указанным критериям. Действия — это операции, которые затем выполняются в рабочем процессе приложения логики.
В нашем примере мы будем использовать следующие коннекторы Logic App для отслеживания инцидентов:
- Azure Boards (часть Azure DevOps), которую можно использовать для отслеживания и создания вопросов и инцидентов.
- службы хранилища Azure, где можно хранить и получать сведения о том, кто дежурит, чтобы вы могли назначить соответствующих людей для реагирования на инцидент. В нашем примере мы будем использовать хранилище таблиц Azure, так как оно предлагает очень простое хранилище "ключ-значение", которое упрощает хранение списка инженеров и их состояния по вызову.
- Microsoft Teams, который можно использовать для создания нового уникального канала инцидентов для отслеживания бесед команд инженеров в режиме реального времени, когда они сообщают о конкретных инцидентах. Это позволяет сохранить взаимодействие в соответствии с временной последовательностью событий при проведении проверки после инцидента.
Теперь давайте связываем это все вместе с приложением логики. Сначала ознакомьтесь с полным приложением, как показано в конструкторе Logic Apps, а затем рассмотрим его пошагово.
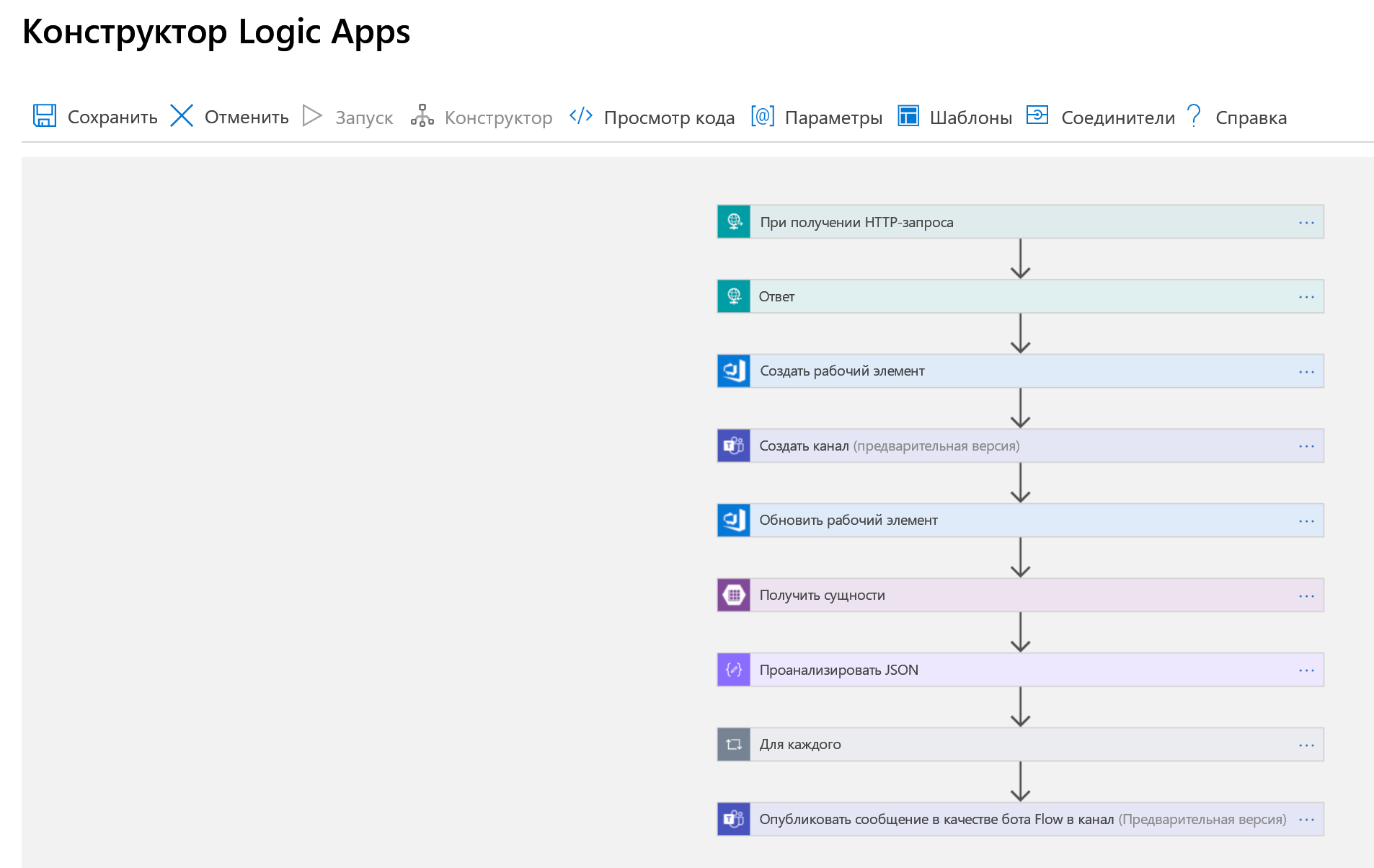
Первым шагом является обработка триггера — упомянутого HTTP-запроса. HTTP POST-запрос выполняется в нашем логическом приложении, которое содержит JSON-содержимое с информацией об инциденте, который мы хотим зарегистрировать. Мы анализируем полученные данные и отправляем обратно подтверждение о получении.
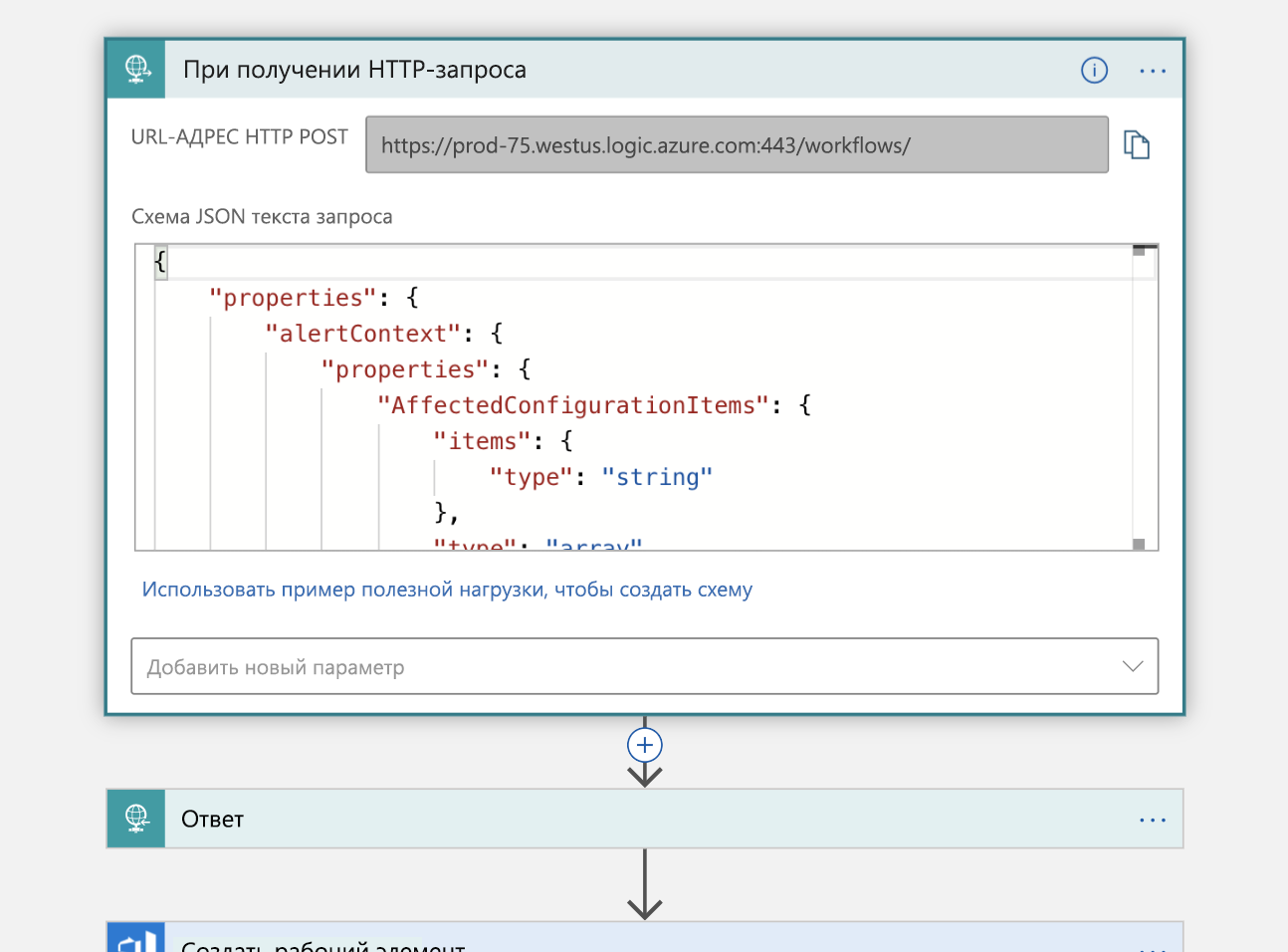
Используя эти сведения, мы создадим новый рабочий элемент в нашей организации Azure DevOps, представляющей этот инцидент.
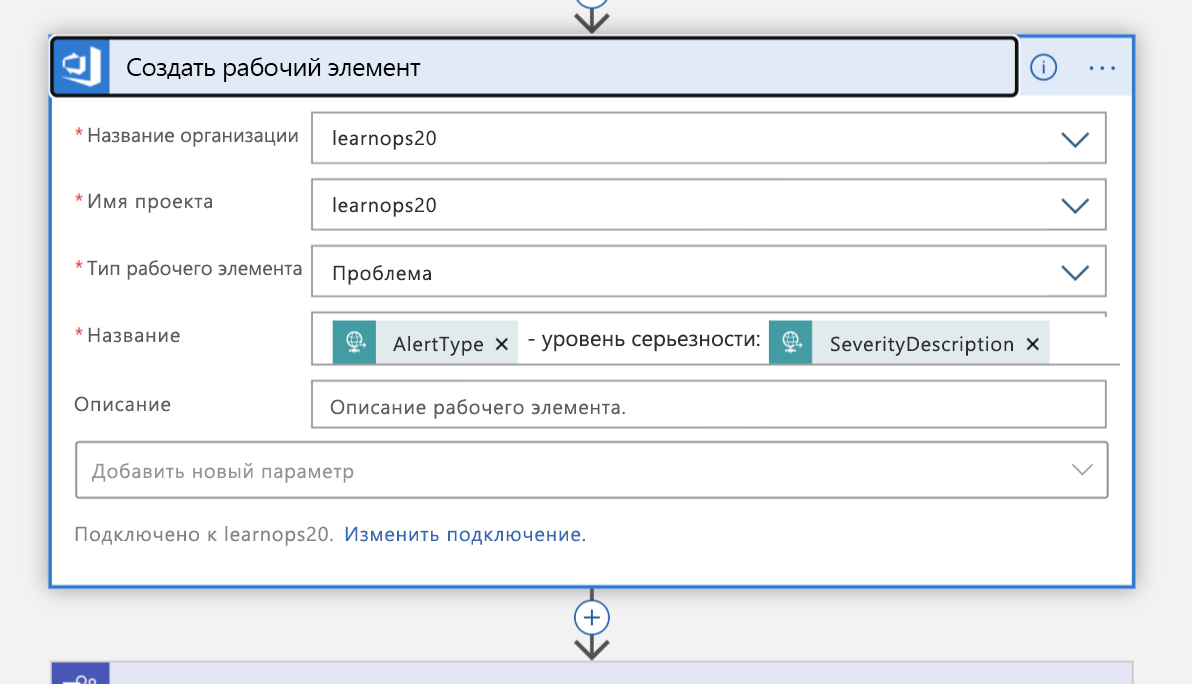
Затем он создаст новый канал Teams для инцидента:
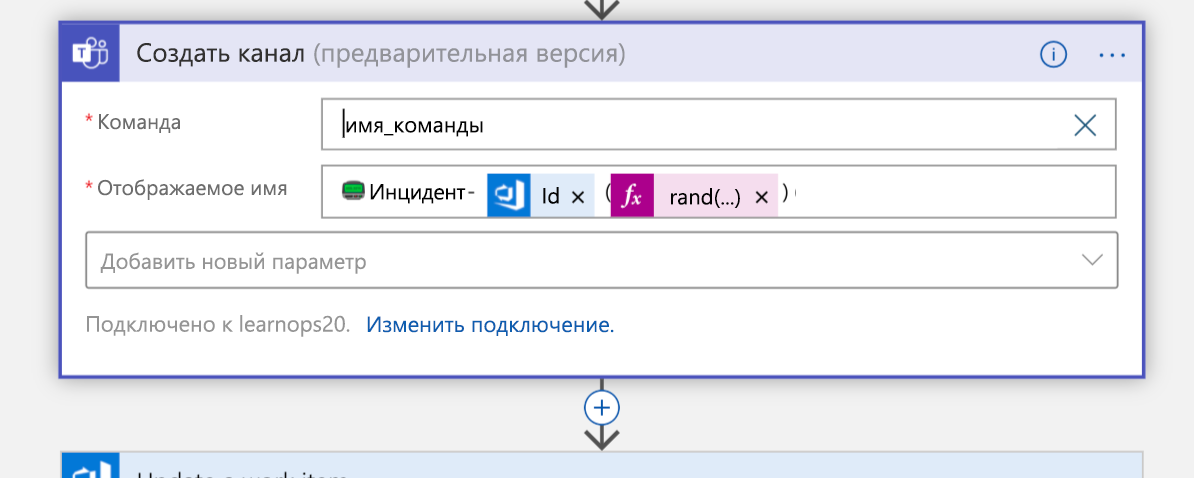
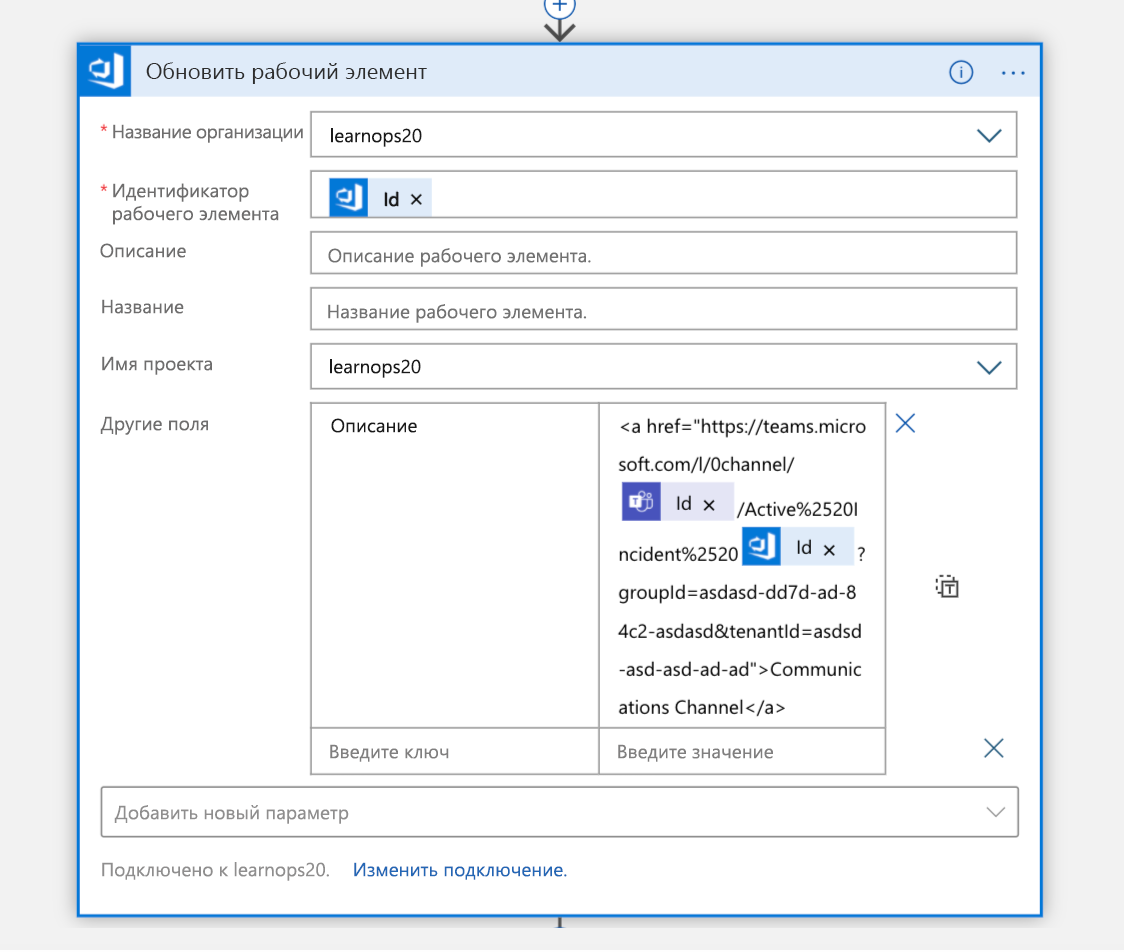
После создания канала рабочий элемент, который мы создали момент назад, обновляется со ссылкой на новый канал. Это хранит всю информацию в одном месте (рабочий элемент) и позволяет людям, глядя на него позже, знать, куда идти, если они хотят присоединиться к этому каналу.
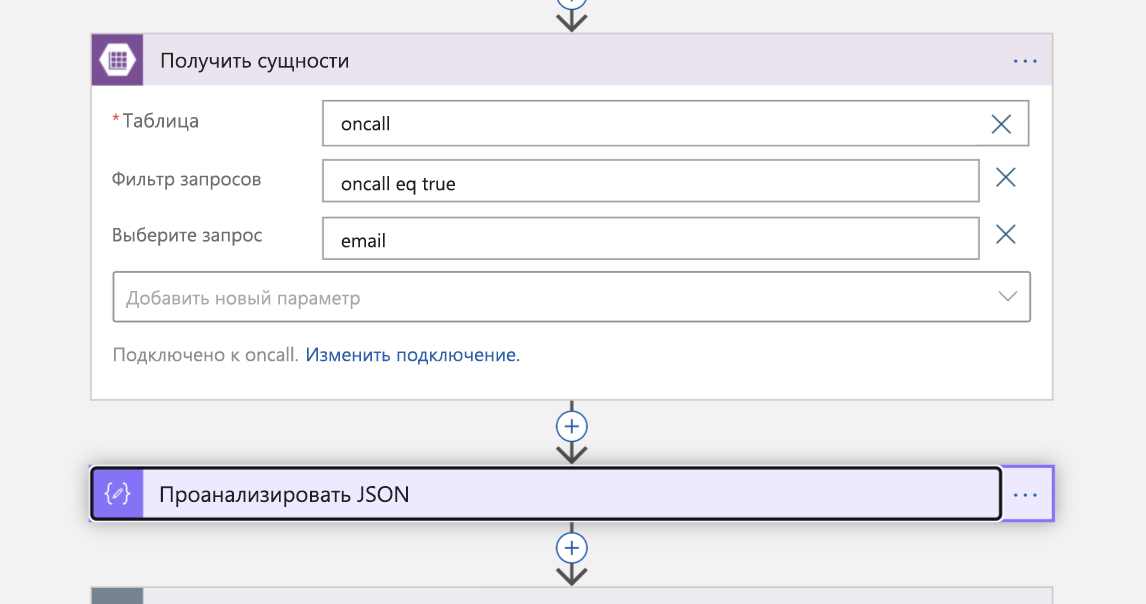
Теперь пришло время вовлечь дежурного в ситуацию. Мы выполняем поиск в службе хранилища таблиц Azure для адреса электронной почты инженера, находящегося на вызове. Возвращается ответ JSON, который затем анализируется.
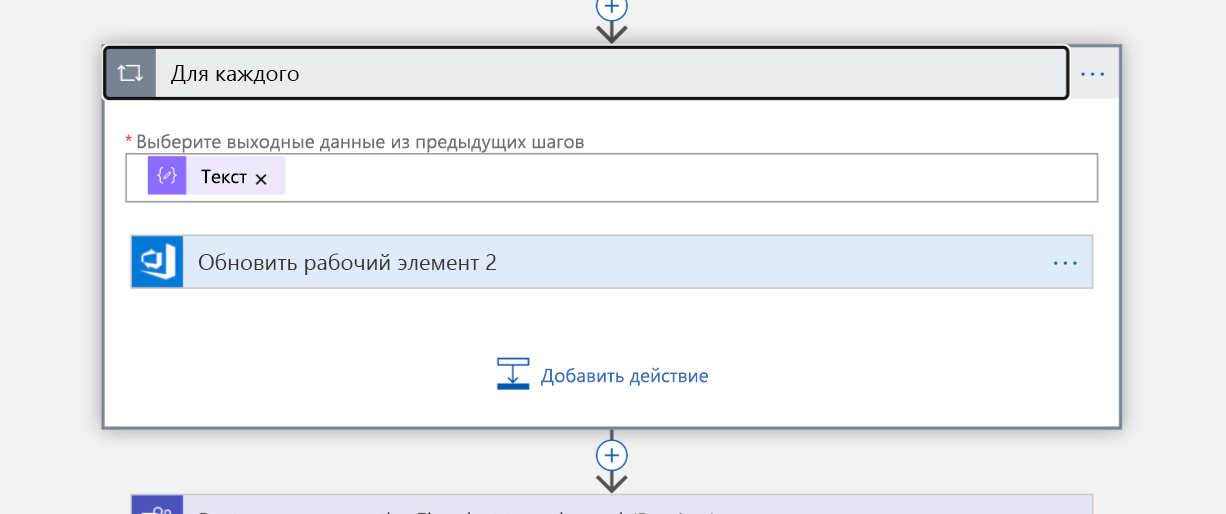
Так как наш запрос вернет список, необходимо выполнить итерацию по каждому элементу в этом списке в качестве следующего шага. Мы назначаем задачу каждому человеку (теперь они становятся владельцами инцидента).
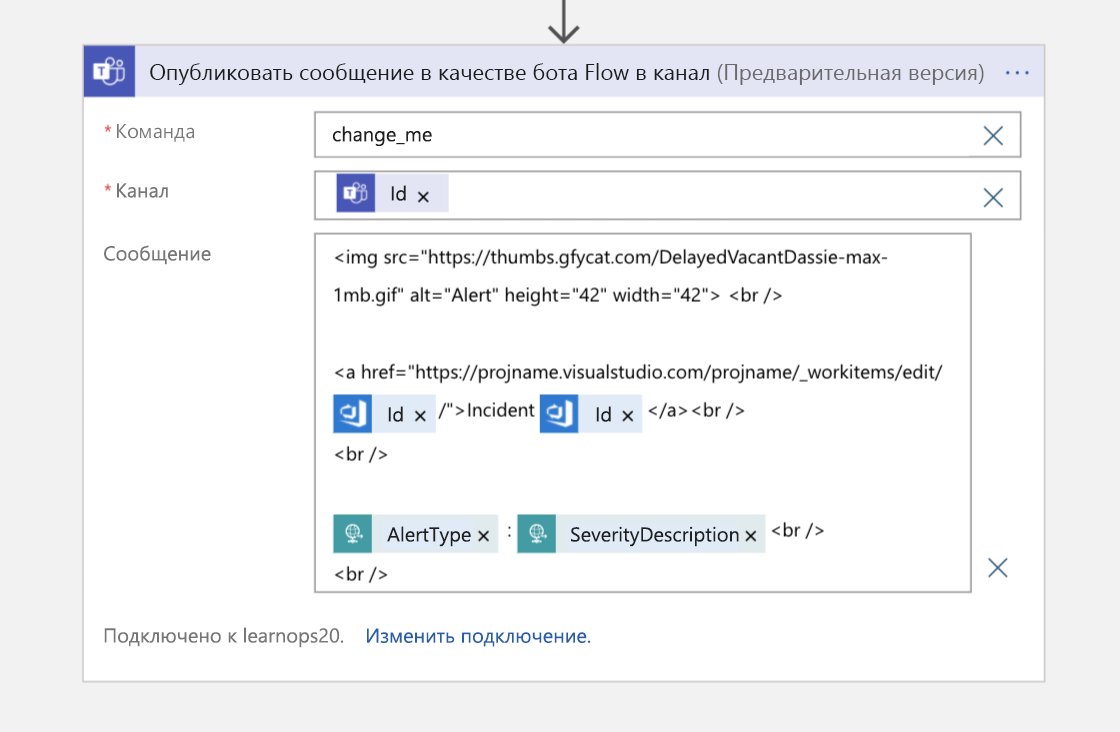
Затем, в качестве заключительного шага, мы отправляем сообщение в канал Teams с указателем на рабочий элемент для тех, кто присоединяется к каналу и хочет знать, где хранится достоверная информация по этому инциденту.
Это лишь один пример того, как можно автоматизировать настройку механизмов отслеживания инцидентов и обмена данными. В следующем уроке мы немного углубимся в аспекты взаимодействия вокруг инцидента.