Результаты теста
Теперь мы рассмотрим результаты теста, чтобы проверить советы по производительности, которые мы обсуждали в предыдущем уроке. В частности, мы сосредоточимся на использовании набора тестов SPEC SFS для создания нескольких потоков, которые имитируют рабочие нагрузки EDA. Кроме того, мы показываем результаты FIO для изучения некоторых методик производительности.
Обзор двух средств тестирования
Пакет SPEC SFS является стандартным отраслевым эталоном для автоматизации проектирования электронных систем. Типичная РАБОЧАЯ нагрузка EDA состоит из функциональных и физических этапов. Функциональный этап выполняет в основном случайные операции ввода-вывода и метаданных файловой системы. Физический этап приводит к последовательному чтению и записи больших блоков.
FIO — это средство ввода-вывода, которое может создавать согласованные случайные или последовательные нагрузки чтения и записи для тестирования операций ввода-вывода и пропускной способности целевого объекта хранения.
Типы томов в Azure NetApp Files
Azure NetApp Files предоставляет два типа томов, которые можно подготовить для облачного хранилища данных: обычные тома и большие тома. В следующей таблице перечислены некоторые основные различия между двумя типами томов. Используйте эту таблицу как руководство при выборе подходящего типа тома для вашей рабочей нагрузки.
| Предел | Обычный том | Большой том |
|---|---|---|
| Минимальная емкость | 100 ГиБ | 50 ТиБ |
| Максимальная емкость | 100 ТиБ | 500 ТиБ |
| Минимальный поддерживаемый уровень обслуживания | Стандарт | Стандарт |
| Максимальная наблюдаемая пропускная способность | 4500 MiB/s | 10 240 МиБ/с |
| Максимальное количество зафиксированных операций ввода-вывода в секунду | ~200 000 | ~700 000 |
| Максимально наблюдаемое количество операций ввода-вывода в секунду | ~135 000 | ~474 000 |
Результаты тестирования с использованием средства SPEC EDA для регулярных томов
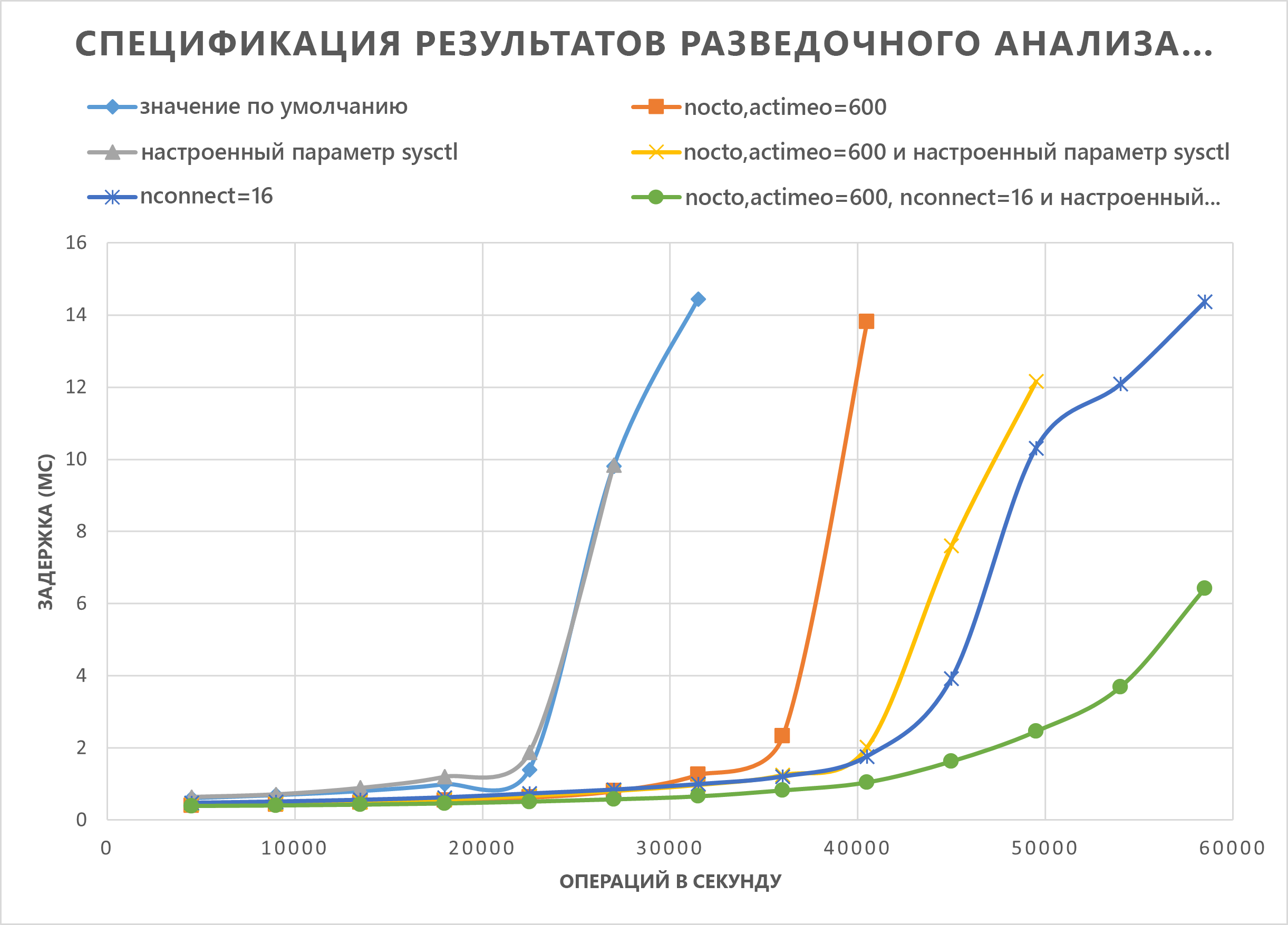
Графики в этом разделе демонстрируют кривые ввода-вывода и задержки. Они рассматривают некоторые сочетания следующих методик производительности:
nocto,actimeo=600sysctl tunednconnect=16
При применении всех трех предыдущих методик операции ввода-вывода в секунду увеличиваются и по-прежнему сохраняют низкую задержку (менее 1 миллисекунда).
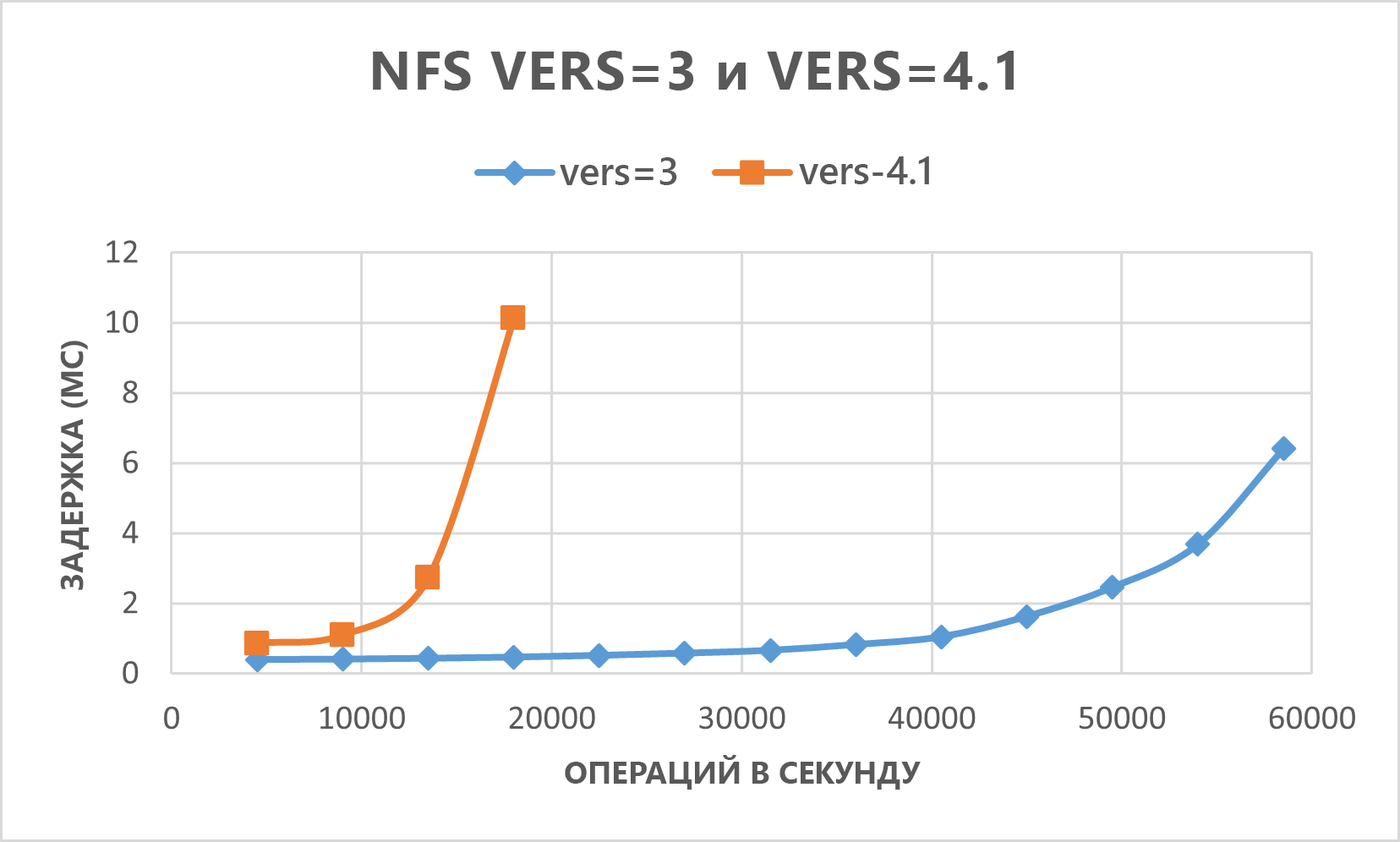
На следующем графике показано, что NFSv3 работает лучше, чем NFSv4.1 для этого типа рабочей нагрузки.
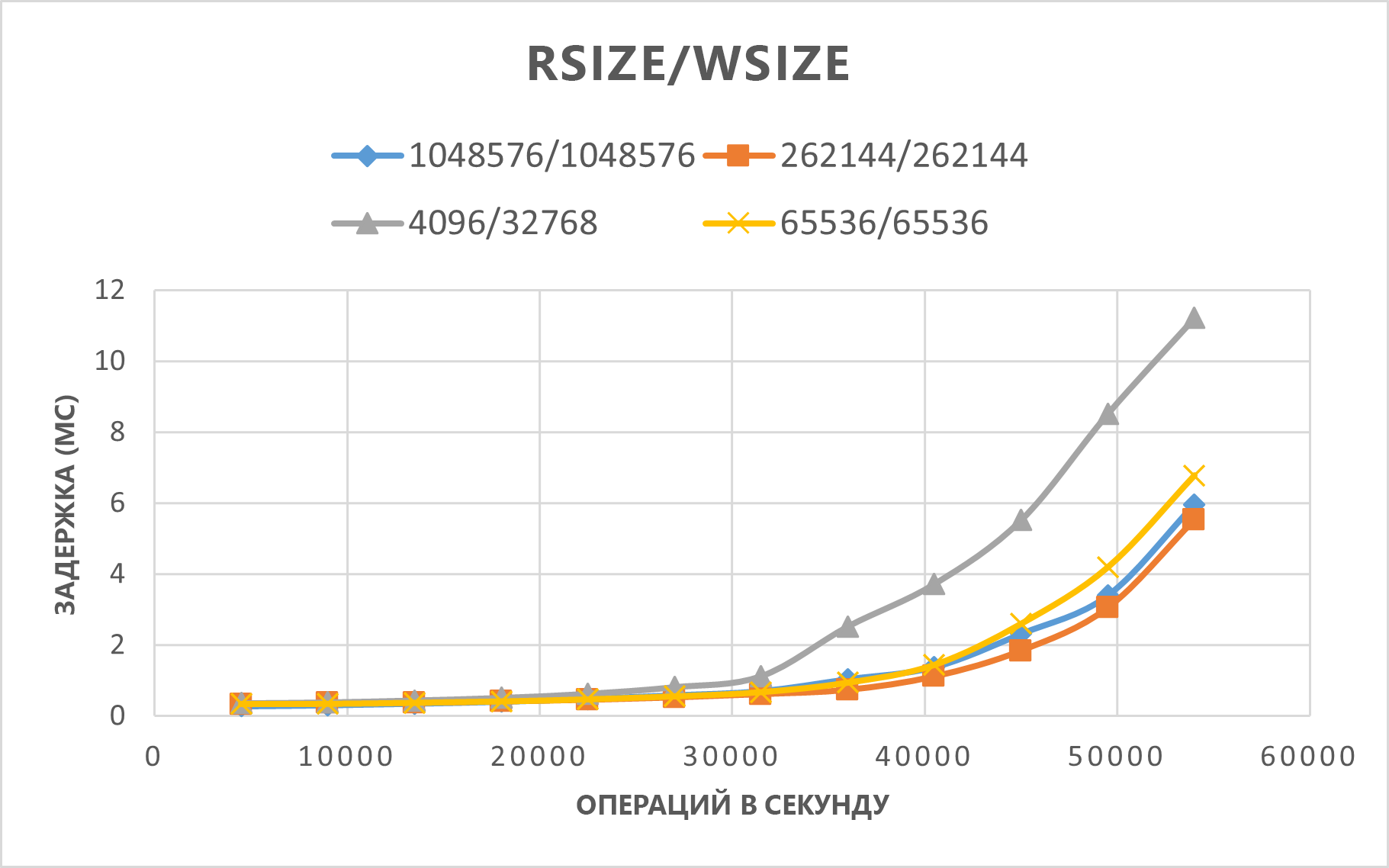
На следующем графике показано, что rsize=wsize=262144(256 K) работает лучше, чем другие параметры.
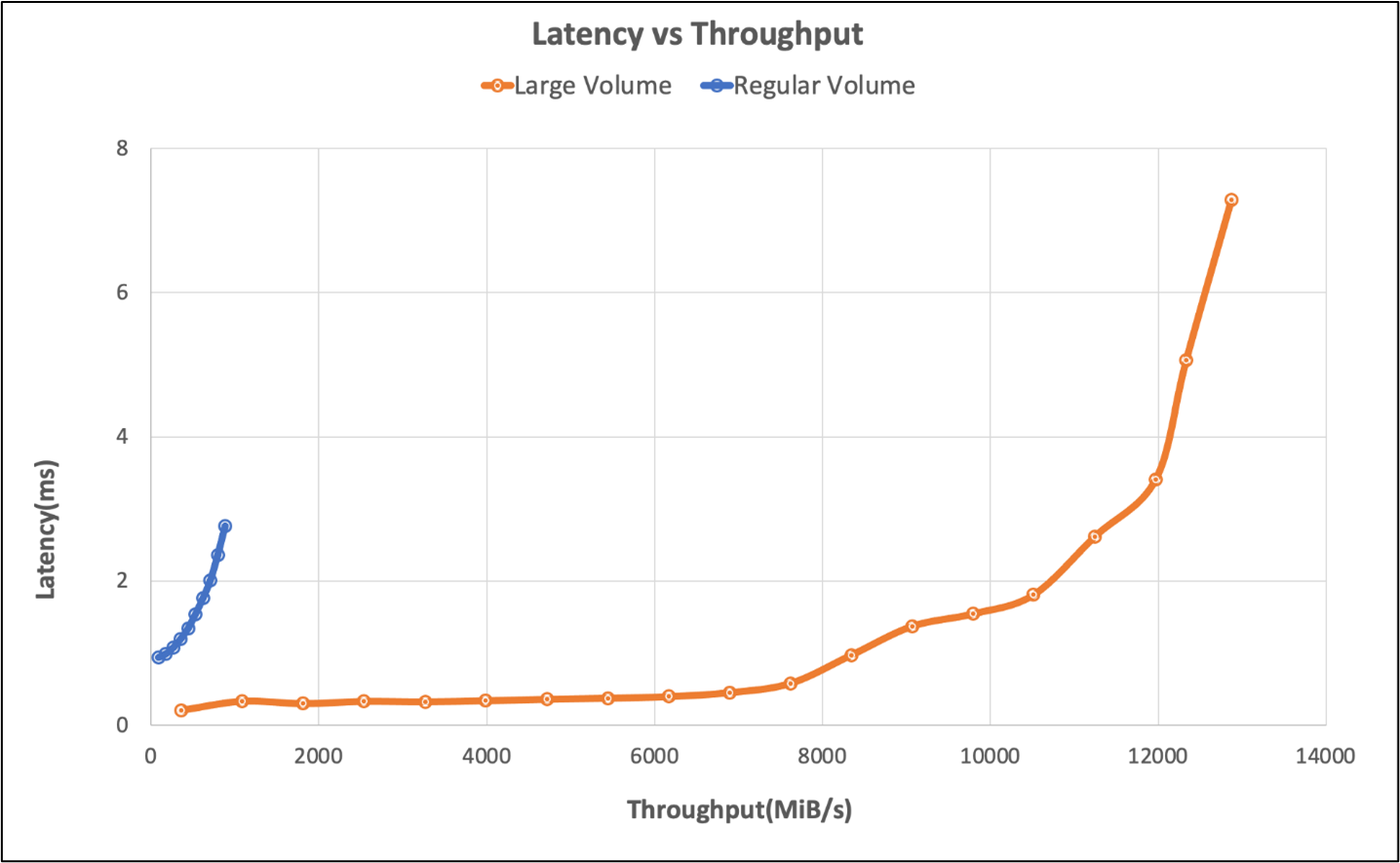
Результаты тестирования средства SPEC EDA для больших объемов данных
Тестирование порогов производительности было проведено на одном большом томе с помощью бенчмарка SPEC SFS со следующей конфигурацией:
| Тип конфигурации | Настройка |
|---|---|
| Операционная система | RHEL 9.3 / RHEL 8.7 |
| Тип экземпляра | D16s_v5 |
| Число экземпляров | 10 |
| Параметры подключения | nocto,actimeo=600,hard,rsize=262144,wsize=262144,vers=3,tcp,noatime,nconnect=8 |
Тесты сравнивали возможности производительности большого объема с помощью SFS-эталона SPEC по сравнению с обычным объемом в Azure NetApp Files.
| Сценарий | Скорость ввода-вывода на уровне 2 мс | MiB/с при 2 мс |
|---|---|---|
| Один обычный том | 39 601 | 692 |
| Один большой том | 652,260 | 10,030 |
Результаты оценки средства FIO для обычных томов
Следующие команды FIO тестируют IOPS (операции ввода-вывода в секунду) и пропускную способность соответственно.
// FIO commands to benchmark IOPS:
// 8K Random Reads
fio --name=8krandomreads --rw=randread --direct=1 --ioengine=libaio --bs=8k --numjobs=4 --iodepth=128 --size=4G --runtime=600 --group_reporting
// 8K Random Writes
fio --name=8krandomwrites --rw=randwrite --direct=1 --ioengine=libaio --bs=8k --numjobs=4 --iodepth=128 --size=4G --runtime=600 --group_reporting
// FIO commands to benchmark throughput:
// 64K Sequential Reads
fio --name=64kseqreads --rw=read --direct=1 --ioengine=libaio --bs=64k --numjobs=4 --iodepth=128 --size=4G --runtime=600 --group_reporting
// 64K Sequential Writes
fio --name=64kseqwrites --rw=write --direct=1 --ioengine=libaio --bs=64k --numjobs=4 --iodepth=128 --size=4G --runtime=600 --group_reporting
В следующих двух графах показано, что при настройке nocto,actimeo=600, nconnect=16и sysctl Azure NetApp Files может достигнуть более высокой пропускной способности и количества операций ввода-вывода в секунду.
Диаграмма 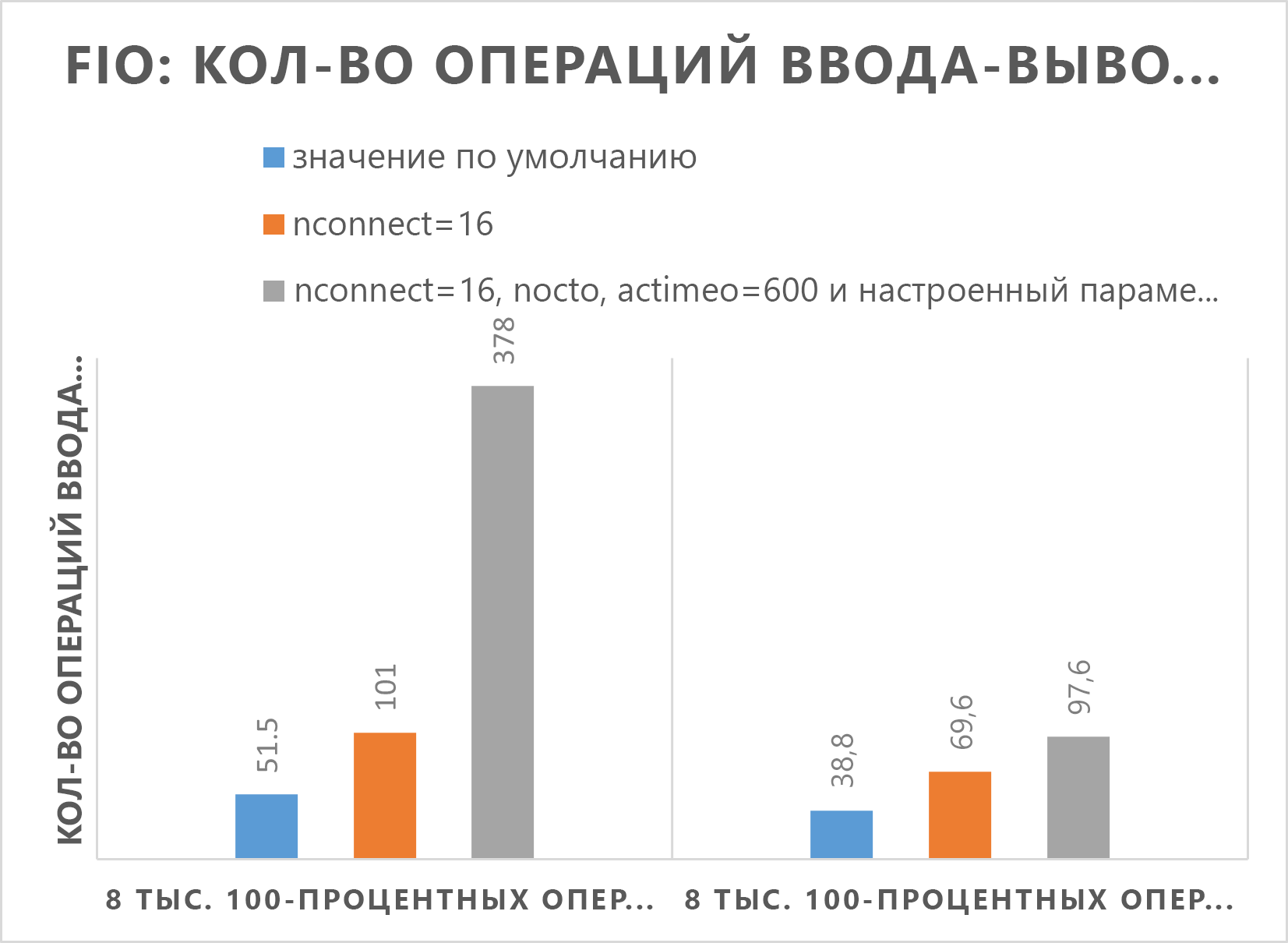
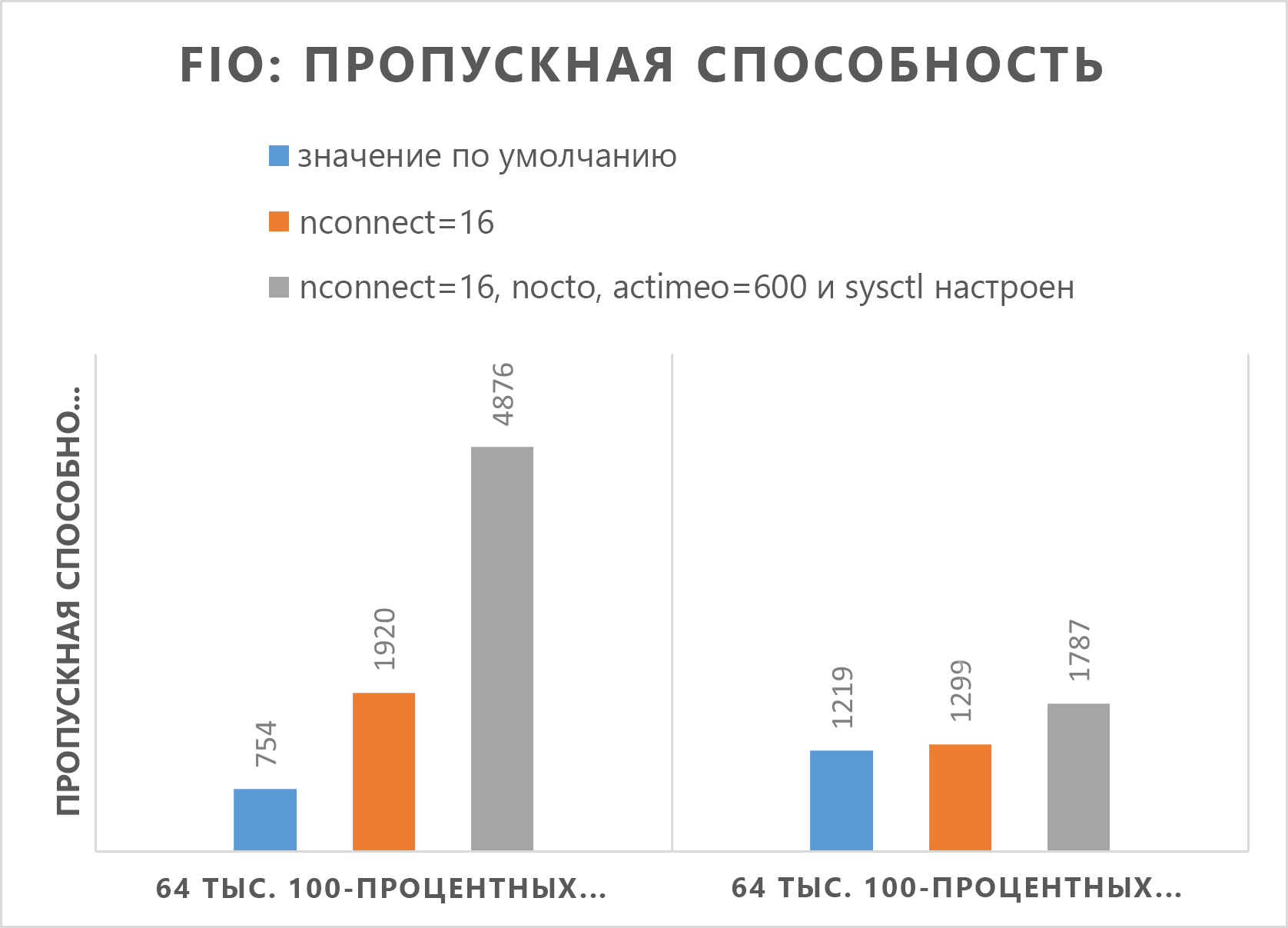
Результаты теста средства FIO для больших объемов
В этом разделе описываются пороговые значения производительности одного большого тома с помощью теста FIO. Тесты выполнялись со следующей конфигурацией:
| Компонент | Конфигурация |
|---|---|
| Размер виртуальной машины Azure | E32s_v5 |
| Ограничение пропускной способности исходящего трафика виртуальной машины Azure | 2000MiB/s (2GiB/s) |
| Операционная система | RHEL 8.4 |
| Большой размер тома | 101 TiB Ultra (пропускная способность 10 240 МиБ/с) |
| Параметры подключения | hard,rsize=65536,wsize=65536,vers=3 ПРИМЕЧАНИЕ. использование как 262144 так и 65536 имело похожую производительность. |
256-KiB последовательных рабочих нагрузок (MiB/s)
График представляет собой последовательную рабочую задачу размером 256 КиБ и рабочий набор размером 1 ТиБ. В нем показано, что один большой том Azure NetApp Files может обрабатывать примерно 8518 МиБ/с чистой последовательной записи и 99 970 МиБ/с чистой последовательности чтения.

8 КиБ случайная рабочая нагрузка (IOPS)
Диаграмма представляет случайную нагрузку объемом 8-КиБ и рабочий набор объемом 1-ТиБ. На графике показано, что большой том Azure NetApp Files может обрабатывать примерно 474 000 чистых случайных операций записи и примерно 709 000 чистых случайных операций чтения.
