Требования к гибридному доступу к файлам
На предыдущих уроках мы в основном говорили о том, какие функции выполняет ваше решение для хранения данных. В этом уроке основное внимание уделяется расположению данных. В частности, рекомендации по гибридному доступу к файлам и их подход.
Общие сведения о гибридном доступе к файлам
Вы решили запустить рабочую нагрузку HPC в Azure, которая сейчас выполняется в вашем центре обработки данных. Вычислительная среда получает доступ к данным в хранилище NAS, которое обслуживает операции NFSv3 для рабочей нагрузки. Ваша среда NAS использовалась несколько лет, но сейчас цикл ее поддержки заканчивается. Вместо замены среды вы хотите выполнить долгосрочную миграцию в облако.
После принятия этого решения, но до полноценного облачного развертывания рабочей нагрузки HPC вы определяете стратегию Azure и настраиваете базовую учетную запись, подписку и систему безопасности. А дальше наступает сложная часть — перенос рабочих нагрузок HPC!
Наращивание кластера HPC и его плоскость управления находятся за рамками этого модуля. Предположим, что вы определили, какие типы и объемы виртуальных машин необходимо запустить в кластере.
Теперь мы также предполагаем, что ваша цель состоит в том, чтобы запустить рабочую нагрузку как есть. То есть вы не хотите изменять логику или методы доступа, развернутые локально. В результате ваш код ожидает, что данные будут находиться в путях каталогов в локальных файловых системах участников кластера.
Первая цель — понять, какие данные требуются и откуда они должны быть получены. Данные могут находиться в одном каталоге в одной среде NAS или могут быть распределены по различным средам.
Следующая цель — определить, какой объем данных требуется для выполнения рабочей нагрузки. Исходные данные занимают несколько гигабайт или сотни терабайт?
Наконец, необходимо определить способ представления данных в вычислении Azure. Обслуживается ли он локально на каждом компьютере кластера HPC или предоставляется ли он облачным решением NAS?
Вопросы удаленного доступа к данным
У вас есть рабочая нагрузка в сфере геномики, которую вы хотите запустить в Azure. Ваши данные создаются локальными последовательностями генов и отправляются в локальную среду NAS. Локальные исследователи используют данные для различных целей. Исследователи также могут использовать результаты рабочей нагрузки HPC, которую вы собираетесь запустить в Azure. Но некоторые из них используют для запуска рабочих нагрузок локальные рабочие станции. Также предположим, что свежие данные генома создаются регулярно. Поэтому у вас есть ограниченный интервал для выполнения текущей рабочей нагрузки перед заменой и обновлением данных.
Задача заключается в том, чтобы передать данные в вычисление Azure без лишних затрат и задержек, сохранив локальный доступ к этим данным.
Ниже приведены некоторые основные вопросы, которые необходимо задать перед запуском рабочих нагрузок HPC в Azure:
- Можно ли переместить исходные данные в Azure без сохранения копии в локальной среде?
- Можно ли сохранить результирующие данные в хранилище в Azure без сохранения копии в локальной среде?
- Требуется ли локальным пользователям одновременный доступ к исходным или результирующим данным?
- Если да, то смогут ли пользователи выполнять операции с данными в Azure или данные должны храниться в локальной среде?
Если данные должны храниться в локальной среде, то какой объем данных необходимо скопировать в Azure для рабочей нагрузки? Каков интервал времени между завершением обработки данных и началом обработки нового набора данных? Уложится ли рабочая нагрузка в этот период?
Также необходимо проанализировать параметры сетевого подключения к Azure. У вас есть доступ к Azure только через Интернет? Такого доступа может быть достаточно в зависимости от размера копируемых и передаваемых данных, а также от интервала времени между обновлениями. Возможно, вам необходимо каждый раз копировать большой объем данных. Вам может потребоваться подключение к Azure с помощью Azure ExpressRoute по глобальной сети (WAN), чтобы увеличить пропускную способность для копирования и передачи данных.
Если у вас уже есть подключение ExpressRoute к Azure, следует проанализировать то, какой объем подключения доступен для операции копирования данных. Если подключение используется активно, то может потребоваться назначить перенос данных на определенное время дня. Или вы можете настроить более подключение ExpressRoute с большей пропускной способностью для передачи больших объемов данных.
При перемещении данных в Azure может потребоваться рассмотреть способ его защиты. Например, у вас может быть локальная среда NFS, использующая службу каталогов, которая предоставляет разрешения для пользователей. Если вы планируете скопировать эту безопасность в Azure, необходимо решить, нужна ли служба каталогов в рамках сборки Azure. С другой стороны, если рабочая нагрузка ограничена кластером HPC и результаты передаются обратно в локальную среду, эти требования можно не учитывать.
Далее мы рассмотрим методы доступа к данным: кэширование, копирование и синхронизацию.
Кэширование, копирование и синхронизация
Рассмотрим общие подходы, которые можно использовать для добавления данных в Azure. Основное внимание в этом обсуждении передачи данных — это активные данные, а не архив данных и резервное копирование.
Мы предполагаем, что передаваемые данные представляют собой рабочий набор в рабочей нагрузке HPC. В среде HPC для биологических исследований данные могут содержать исходные данные, такие как необработанные данные генома, двоичные файлы, используемые для обработки этих данных, или дополнительные данные, такие как эталонный геном. Они должны обрабатываться сразу после поступления или через минимальный промежуток времени. Данные должны храниться на носителе с соответствующим профилем производительности с точки зрения операций ввода-вывода в секунду, задержки, пропускной способности и стоимости. Архивы и резервные копии данных, напротив, чаще всего передаются в самое дешевое хранилище, которое не предназначено для высокопроизводительного доступа.
Основными методами передачи активных данных являются кэширование, копирование и синхронизация. Давайте обсудим плюсы и минусы каждого подхода, начиная с копирования.
Копирование данных — наиболее распространенный способ перемещения данных. Данные копируются различными способами в зависимости от используемого инструмента.
Учитывайте следующие факторы:
- Размер файлов.
- Количество файлов.
- Объем доступной пропускной способности для передачи данных.
- Время передачи.
Если вы передаете несколько файлов не очень большого размера в удаленное место назначения, вам будет достаточно базового инструмента копирования, например cp. При передаче данных по незащищенным сетям вы, скорее всего, будете использовать scp вместо cp, так как scp обеспечивает шифрование по протоколу Secure Shell (SSH).
Существует множество подходов к оптимизации операций копирования в зависимости от места, куда вы собираетесь копировать данные. Например, при копировании файлов напрямую на каждый компьютер HPC можно запланировать отдельные операции копирования на каждом узле.
При копировании данных по каналам глобальной сети необходимо учитывать количество копируемых файлов и папок. Если вы копируете много небольших файлов, вы хотите объединить использование копии с архивом, как tar удалить затраты на метаданные из ссылки глобальной сети. Скопируйте TAR-файл в Azure, а затем скопируйте данные на эти компьютеры.
Еще одной проблемой, связанной с копированием, является риск прерывания. Например, если вы пытаетесь скопировать большой файл и возникают ошибки передачи, использование cp не работает, так как оно не может перезапустить копию, из которой она ушла.
Кроме того, нужно понимать, что копия может устареть. Например, вы можете скопировать набор данных в Azure. После этого локальный пользователь может обновить один или несколько исходных файлов. Необходимо определить процесс, гарантирующий, что вы используете правильные данные.
Синхронизация данных — это более сложная форма копирования. Такие средства, как rsync, позволяют синхронизировать данные между источником и местом назначения в дополнение к копированию данных из источника.
rsync проверяет актуальность файлов на основе размеров файлов и дат изменения. Синхронизация позволяет минимизировать вероятность наличия устаревших файлов.
rsync предоставляет возможность восстановления. Например, если вы копируете большой файл и возникают ошибки передачи, то rsync может возобновить копирование с момента прерывания.
rsync — это бесплатный и простой в реализации инструмент. У него есть и другие возможности, не описанные в этой статье. Он позволяет установить синхронизированную файловую систему в Azure на основе локальных данных.
rsync также имеет ограничения, о которых стоит упомянуть. Во-первых, это средство является однопоточным. Оно может выполнять только одну операцию за раз и не может параллельно обращаться к данным. Программа копирования cp также является однопоточной. Поэтому эти средства не оптимизированы для крупномасштабных операций копирования и синхронизации с большими объемами данных за короткий период времени. Вам также потребуется запустить инструмент для синхронизации данных. Запуск этого средства повышает сложность среды, так как вам необходимо сделать так, чтобы средство работало в соответствии с требованиями к временному интервалу. Например, может потребоваться запланировать сценарий, включающий rsync. Такой подход означает, что вам потребуется добавить ведение журнала для вашего сценария на случай возникновения проблем. Это также означает, что необходимо отслеживать наличие проблем. Уровень сложности может быстро возрастать.
Если вы используете коммерческое решение NAS, существуют средства синхронизации на уровне сервера, которые более сложны и предлагают многопоточное производительность. После включения и настройки такие инструменты работают постоянно, синхронизируя данные между одним или несколькими источниками и местами назначения.
При копировании и синхронизации передаются полные копии данных источника. Полная передача файлов подойдет для небольших наборов данных или файлов небольшого размера. Если данные источника представляют собой множество больших файлов, это может привести к значительным задержкам. Чем больше данных вы передаете, тем больше времени занимает передача. Синхронизация гарантирует, что в облако добавляются только новые файлы. Однако эти файлы по-прежнему должны передаваться полностью. В некоторых случаях вашей рабочей нагрузке HPC может не требоваться полный набор файлов. Ей может требоваться доступ только к конкретным участкам файлов.
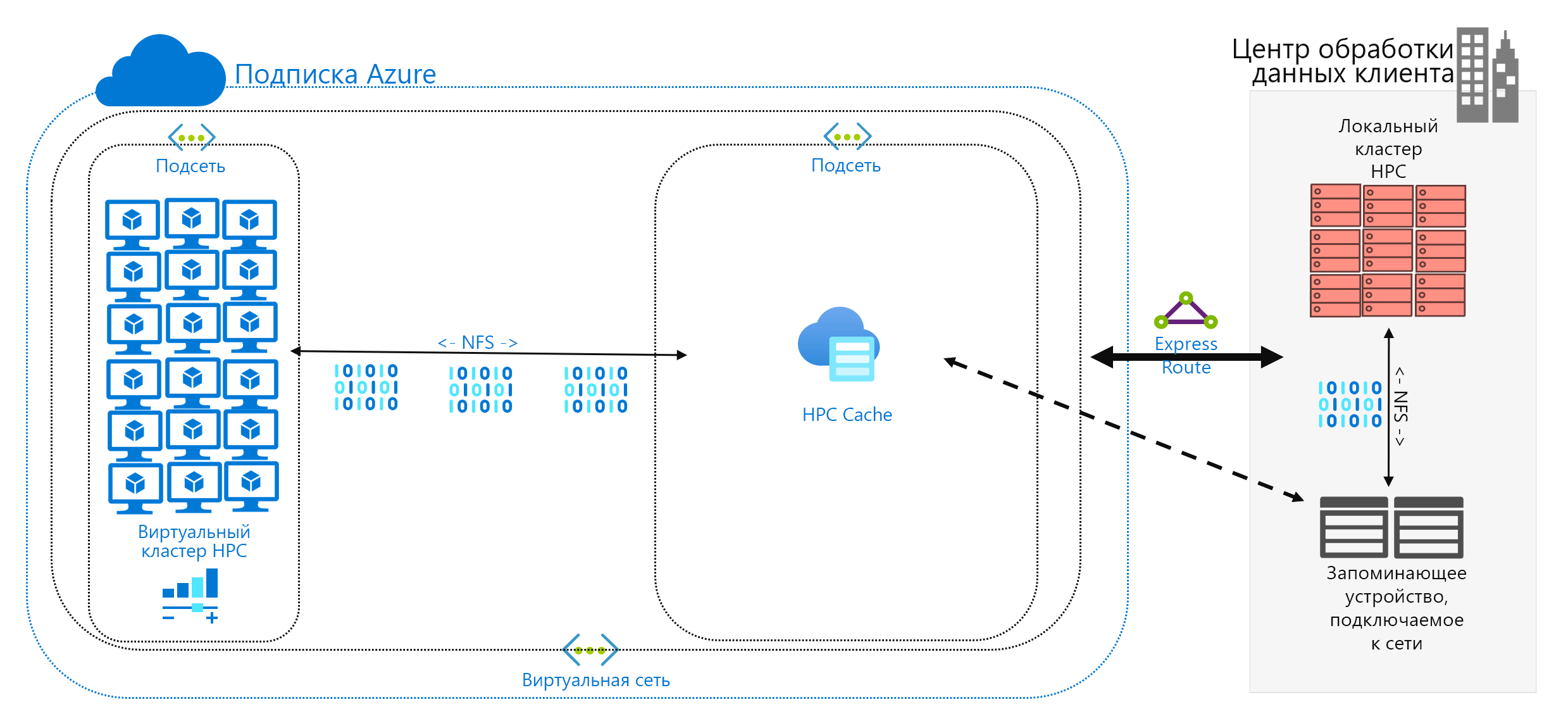
Кэширование данных — это третий подход к добавлению данных в Azure. Кэширование означает извлечение и представление данных файлов с помощью кэша. Кэш может располагаться на отдельных локальных клиентах или представлять собой распределенный кэш, обслуживающий все компьютеры HPC. Кэши обычно используются для снижения задержки, поэтому размещение кэша на границе задержки является оптимальным подходом к предоставлению данных. Например, можно кэшировать запросы данных через подключение к глобальной сети, поместив распределенный кэш в вычисление Azure, подключенное к локальному хранилищу по каналу глобальной сети.
В этом модуле мы говорим именно о кэшировании файлов, при котором сами поля кэша запрашиваются с компьютеров. При этом данные получаются из среды серверного хранилища (например, среды NFS NAS) и передаются клиентам.
Преимущество кэширования заключается в двух аспектах. Во-первых, кэш не извлекает файлы полностью. Кэш получает запрошенное подмножество файлов (или диапазон байтов), а не целые файлы. Получение данных основано на клиентских запросах для этих диапазонов байтов. Такой подход к получению данных гораздо меньше влияет на производительность по сравнению с получением всего крупного файла, когда требуется лишь его малая часть.
Во-вторых, кэш оптимизирует многократный доступ к часто запрашиваемым данным. После поступления диапазона байтов в кэш последующие запросы к этим данным выполняются быстро. Единственной медленной операцией получения данных является первая. При наличии большого числа клиентов и потоков HPC, обращающихся к общему набору файлов, можно получить значительные преимущества.
Кэширование предлагает еще одно преимущество для гибридных сценариев. Данные хранятся в Azure (в кэше) лишь временно. Они хранятся только во время выполнения рабочей нагрузки HPC. Таким образом, вы можете снизить затраты на логистику за счет более точечного перемещения данных в Azure. Проблемы конфиденциальности и безопасности данных можно изолировать на уровне кэша и самих компьютеров HPC.
Наконец, некоторые решения для кэширования предлагают так называемую проверку атрибутов. Как и при синхронизации, кэш периодически проверяет атрибуты файла, расположенного в источнике, и получает диапазоны байтов, если в источнике произошли изменения. Такая архитектура гарантирует, что среда HPC всегда работает с актуальными данными.