Общие сведения о хранилищах данных в Fabric
Lakehouse Fabric — это коллекция файлов, папок, таблиц и ярлыков, которые действуют как база данных в озере данных. Он используется подсистемой Spark и подсистемой SQL для обработки больших данных и имеет функции для транзакций ACID при использовании таблиц с форматированными разностными таблицами с открытым кодом.
Интерфейс хранилища данных Fabric позволяет переходить с озера озера Lakehouse (который поддерживает проектирование данных и Apache Spark) на интерфейсы SQL, предоставляемые традиционным хранилищем данных. Lakehouse позволяет считывать таблицы и использовать конечную точку аналитики SQL, а хранилище данных позволяет управлять данными.
В интерфейсе хранилища данных вы моделироваете данные с помощью таблиц и представлений, запустите T-SQL для запроса данных в хранилище данных и Lakehouse, используйте T-SQL для выполнения операций DML с данными внутри хранилища данных и обслуживания уровней отчетов, таких как Power BI.
Итак, вы изучили основные принципы для разработки схемы реляционного хранилища данных. Теперь давайте рассмотрим, как создать хранилище данных.
Описание хранилища данных в Fabric
В интерфейсе хранилища данных в Fabric можно создать реляционный слой на основе физических данных в Lakehouse и предоставить его средствам анализа и отчетности. Хранилище данных можно создать непосредственно в Fabric из центра создания или в рабочей области. После создания пустого хранилища можно добавить в него объекты.
После создания хранилища можно создавать таблицы с помощью T-SQL непосредственно в интерфейсе Fabric.
Прием данных в хранилище данных
Существует несколько способов приема данных в хранилище данных Fabric, включая конвейеры, потоки данных, межбазовые запросы и команду COPY INTO. После приема данные становятся доступными для анализа несколькими бизнес-группами, которые могут использовать такие функции, как межбазовый запрос и общий доступ для доступа к нему.
Создание таблиц
Чтобы создать таблицу в хранилище данных, можно использовать SQL Server Management Studio (SSMS) или другой клиент SQL для подключения к хранилищу данных и запуска инструкции CREATE TABLE. Вы также можете создавать таблицы непосредственно в пользовательском интерфейсе Fabric.
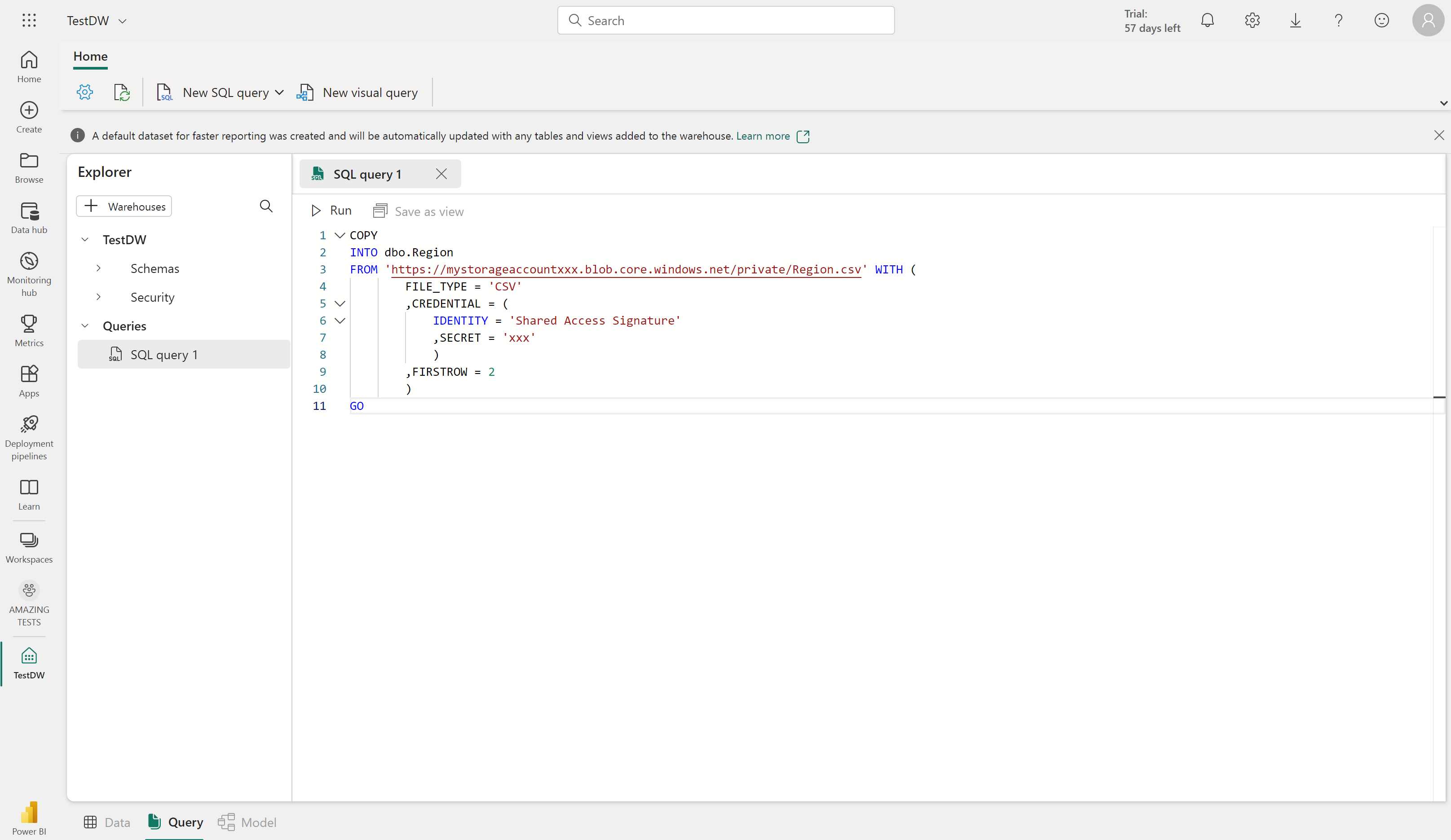
Данные из внешнего расположения можно скопировать в таблицу в хранилище данных с помощью синтаксиса COPY INTO . Например:
COPY INTO dbo.Region
FROM 'https://mystorageaccountxxx.blob.core.windows.net/private/Region.csv' WITH (
FILE_TYPE = 'CSV'
,CREDENTIAL = (
IDENTITY = 'Shared Access Signature'
, SECRET = 'xxx'
)
,FIRSTROW = 2
)
GO
Этот SQL-запрос загружает данные из CSV-файла, хранящегося в Хранилище BLOB-объектов Azure, в таблицу с именем "Регион" в хранилище данных Fabric.
Клонирование таблиц
Вы можете создавать клоны таблиц нулевого копирования с минимальными затратами на хранение в хранилище данных. Эти клоны по сути являются репликами таблиц, созданных путем копирования метаданных, а также ссылки на те же файлы данных в OneLake. Это означает, что базовые данные, хранящиеся в виде файлов parquet, не дублируются, что помогает сэкономить затраты на хранение.
Клоны таблиц особенно полезны в нескольких сценариях.
- Разработка и тестирование. Клоны позволяют разработчикам и тестировщикам создавать копии таблиц в более низких средах, упрощая разработку, отладку, тестирование и процессы проверки.
- Восстановление данных. В случае сбоя выпуска или повреждения данных клоны таблиц могут сохранять предыдущее состояние данных, что позволяет восстановить данные.
- Исторические отчеты: они помогают создавать исторические отчеты, которые отражают состояние данных в определенный момент времени и сохраняют данные в определенных бизнес-вех.
Вы можете создать клон таблицы с помощью CREATE TABLE AS CLONE OF команды T-SQL.
Дополнительные сведения о клонах таблиц см. в руководстве . Клонирование таблицы с помощью T-SQL в Microsoft Fabric.
Рекомендации по таблице
После создания таблиц в хранилище данных важно рассмотреть процесс загрузки данных в эти таблицы. Распространенный подход — использовать промежуточные таблицы. В Fabric можно использовать команды T-SQL для загрузки данных из файлов в промежуточные таблицы в хранилище данных.
Промежуточные таблицы — это временные таблицы, которые можно использовать для очистки данных, преобразования данных и проверки данных. Промежуточные таблицы также можно использовать для загрузки данных из нескольких источников в одну целевую таблицу.
Обычно загрузка данных выполняется как периодический пакетный процесс, в котором вставка и обновление хранилища данных координируются с регулярным интервалом (например, ежедневно, еженедельно или ежемесячно).
Как правило, следует реализовать процесс загрузки хранилища данных, выполняющий задачи в следующем порядке:
- Прием новых данных для загрузки в озеро данных, применение предварительной очистки или преобразований по мере необходимости.
- Загрузите данные из файлов в промежуточные таблицы в реляционном хранилище данных.
- Загрузите таблицы измерений из данных измерения в промежуточных таблицах, обновите существующие строки или вставьте новые строки и при необходимости создайте суррогатные значения ключей.
- Загрузите таблицы фактов из данных фактов в промежуточных таблицах, найдите соответствующие суррогатные ключи для связанных измерений.
- Выполните оптимизацию после загрузки, обновив индексы и статистику распределения таблиц.
Если у вас есть таблицы в lakehouse, и вы хотите иметь возможность запрашивать их в хранилище , но не вносить изменения в хранилище данных Fabric, вам не нужно копировать данные из lakehouse в хранилище данных. Данные в lakehouse можно запрашивать непосредственно из хранилища данных с помощью запросов между базами данных.
Внимание
Работа с таблицами в хранилище данных Fabric в настоящее время имеет некоторые ограничения. Дополнительные сведения см . в таблицах в хранилище данных в Microsoft Fabric .