Изучение и обработка данных с помощью Microsoft Fabric
Данные являются краеугольным камнем обработки и анализа данных, особенно при обучении модели машинного обучения для достижения искусственного интеллекта. Как правило, модели демонстрируют повышенную производительность по мере увеличения размера обучаемого набора данных. В дополнение к количеству данных качество данных имеет одинаково важное значение.
Чтобы гарантировать качество и количество данных, следует использовать надежные механизмы приема и обработки данных Microsoft Fabric. Вы можете выбрать подход с низким кодом или код-первый подход при создании основных конвейеров приема данных, исследования и преобразования.
Прием данных в Microsoft Fabric
Чтобы работать с данными в Microsoft Fabric, сначала необходимо принять данные. Вы можете получать данные из нескольких источников, как локальных, так и облачных источников данных. Например, вы можете получать данные из CSV-файла, хранящегося на локальном компьютере или в azure Data Lake служба хранилища (2-го поколения).
Совет
Узнайте больше о приеме и оркестрации данных из различных источников с помощью Microsoft Fabric.
После подключения к источнику данных можно сохранить данные в Microsoft Fabric lakehouse. Lakehouse можно использовать в качестве центрального расположения для хранения любых структурированных, полуструктурированных и неструктурированных файлов. Затем вы можете легко подключиться к lakehouse, когда вы хотите получить доступ к данным для изучения или преобразования.
Изучение и преобразование данных
Как специалист по обработке и анализу данных, вы можете быть наиболее знакомы с написанием и выполнением кода в записных книжках. Microsoft Fabric предлагает знакомый интерфейс записной книжки, на основе вычислительных ресурсов Spark.
Apache Spark — это платформа параллельной обработки открытый код для крупномасштабной обработки данных и аналитики.
Записные книжки автоматически подключаются к вычислительным ресурсам Spark. При первом запуске ячейки в записной книжке запускается новый сеанс Spark. Сеанс сохраняется при выполнении последующих ячеек. Сеанс Spark автоматически останавливается после некоторого времени бездействия для экономии затрат. Вы также можете остановить сеанс вручную.
При работе с записной книжкой можно выбрать язык, который вы хотите использовать. Для рабочих нагрузок обработки и анализа данных, скорее всего, вы будете работать с PySpark (Python) или SparkR (R).
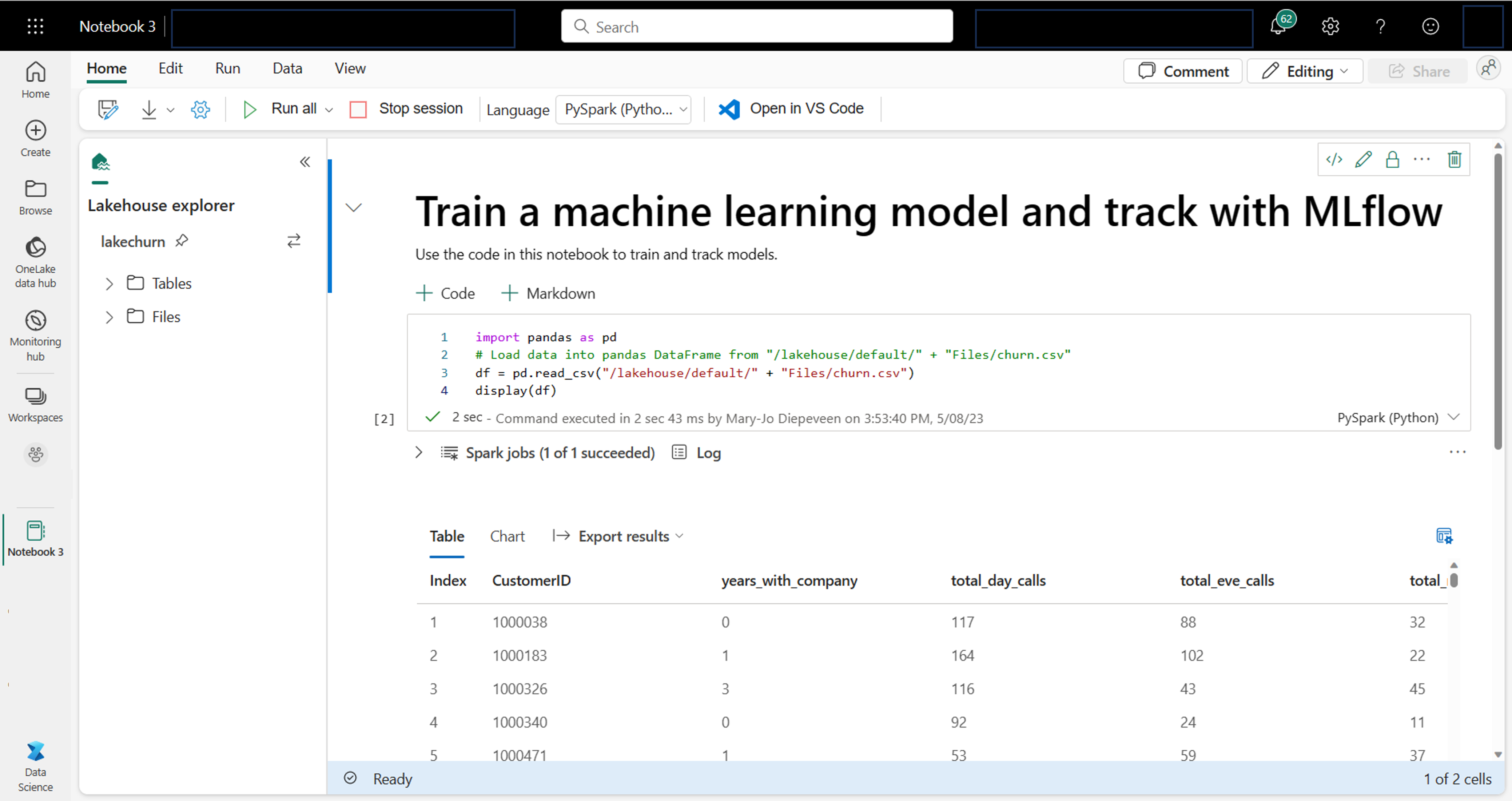
В записной книжке можно просматривать данные с помощью предпочитаемой библиотеки или с любыми встроенными параметрами визуализации. При необходимости можно преобразовать данные и сохранить обработанные данные, написав их обратно в lakehouse.
Подготовка данных с помощью Wrangler
Чтобы быстрее изучить и преобразовать данные, Microsoft Fabric предлагает простой для использования Wrangler.
После запуска Data Wrangler вы получите описательный обзор данных, с которыми вы работаете. Вы можете просмотреть сводную статистику данных, чтобы найти любые проблемы, такие как отсутствующие значения.
Чтобы очистить данные, можно выбрать любые встроенные операции очистки данных. При выборе операции предварительный просмотр результата и связанного кода автоматически создается для вас. При выборе всех необходимых операций вы можете экспортировать преобразования в код и выполнить его в данных.