Типы машинного обучения
Существует несколько типов машинного обучения, и необходимо применить соответствующий тип в зависимости от того, что вы пытаетесь предсказать. Разбивка распространенных типов машинного обучения показана на следующей схеме.
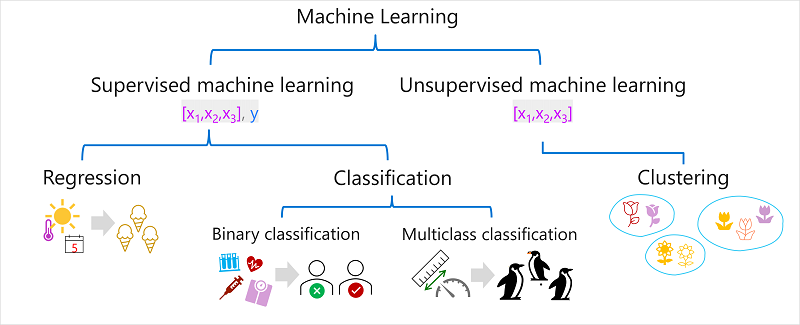
Контролируемое машинное обучение
Контролируемое машинное обучение — это общий термин для алгоритмов машинного обучения, в которых данные обучения включают как значения признаков, так и известные значения меток. Контролируемое машинное обучение используется для обучения моделей путем определения связи между признаками и метками в прошлых наблюдениях, чтобы можно было прогнозировать неизвестные метки для признаков в будущих случаях.
Регрессия
Регрессия — это форма контролируемого машинного обучения, в которой метка, прогнозируемая моделью, представляет собой числовое значение. Например:
- Количество мороженого, проданного в определенный день, в зависимости от температуры, количества осадков и скорости ветра.
- Цена продажи недвижимости, основанная на ее площади в квадратных футах, количестве спален и социально-экономических показателях ее местоположения.
- Топливная экономичность (в милях на галлон) автомобиля в зависимости от объема двигателя, веса, ширины, высоты и длины.
Классификация
Классификация — это форма контролируемого машинного обучения, в которой метка представляет собой категоризацию, или класс. Существует два распространенных сценария классификации.
Двоичная классификация
В двоичной классификации метка определяет, является ли наблюдаемый элемент (или не является) экземпляром определенного класса. Или, говоря другими словами, модели двоичной классификации прогнозируют один из двух взаимоисключающих результатов. Например:
- Находится ли пациент в группе риска возникновения диабета, на основании клинических показателей, таких как вес, возраст, уровень глюкозы в крови и т.д.
- Допустит ли клиент банка невыплату по кредиту на основании доходов, кредитной истории, возраста и других факторов.
- Будет ли клиент рассылки положительно реагировать на маркетинговое предложение, на основании демографических характеристик и прошлых покупок.
Во всех этих примерах модель прогнозирует двоичное значение true/false или положительное или отрицательное прогнозирование для одного возможного класса.
Классификация по нескольким классам
Классификация по нескольким классам расширяет двоичную классификацию для прогнозирования метки, которая представляет один из нескольких возможных классов. Например,
- Вид пингвина (Adelie, Gentoo или Chinstrap) на основе его физических измерений.
- Жанр фильма (комедия, ужас, романтика, приключения или научно-фантастическая фантастика) на основе его литья, режиссера и бюджета.
В большинстве сценариев с известным набором нескольких классов классификация по нескольким классам используется для прогнозирования взаимоисключающих меток. Например, пингвин не может быть одновременно Генту и Адели. Однако есть и некоторые алгоритмы, которые можно использовать для обучения моделей классификации с несколькими метками, в которых для одного наблюдения может существовать более одной допустимой метки. Например, фильм может быть отнесен как к категории научная фантастика, так и к категории комедия.
Неконтролируемое машинное обучение
Неконтролируемое машинное обучение предполагает обучение моделей на данных, состоящих только из значений признаков без каких-либо известных меток. Алгоритмы неконтролируемого машинного обучения определяют связи между признаками наблюдений в данных обучения.
Кластеризация
Наиболее распространенной формой неконтролируемого машинного обучения является кластеризация. Алгоритм кластеризации выявляет сходство между наблюдениями на основе их признаков и объединяет их в дискретные кластеры. Например:
- Группировать похожие цветы на основе их размера, количества листьев и количества лепестков.
- Определять группы похожих клиентов на основе демографических характеристик и покупательского поведения.
В некоторых случаях кластеризация подобна классификации по нескольким классам. В этом случае она категоризирует наблюдения в дискретные группы. Разница заключается в том, что при использовании классификации вы уже знаете классы, к которым относятся наблюдения в данных для обучения. Поэтому алгоритм работает путем определения связи между признаками и известной меткой классификации. В кластеризации нет ранее известной метки кластера, поэтому алгоритм группирует наблюдения данных исключительно на основе сходства признаков.
В некоторых случаях кластеризация используется для определения набора классов перед обучением модели классификации. Например, вы можете использовать кластеризация для сегментирования клиентов в группы, а затем анализировать эти группы для выявления и классификации различных классов клиентов (высокий уровень — низкий объем, частый мелкий покупатель и т. д.). Затем вы можете использовать классификации, чтобы пометить наблюдения в результатах кластеризации и использовать помеченные данные для обучения модели классификации, которая прогнозирует соответствующую категорию для нового клиента.