Знакомство с конвейерами приема данных
Теперь, когда вы имеете некоторое представление об архитектуре крупномасштабного решения для хранения данных и некоторых технологиях распределенной обработки, которые можно использовать для обработки больших объемов данных, пришло время изучить прием данных в хранилище аналитических данных из одного или нескольких источников.
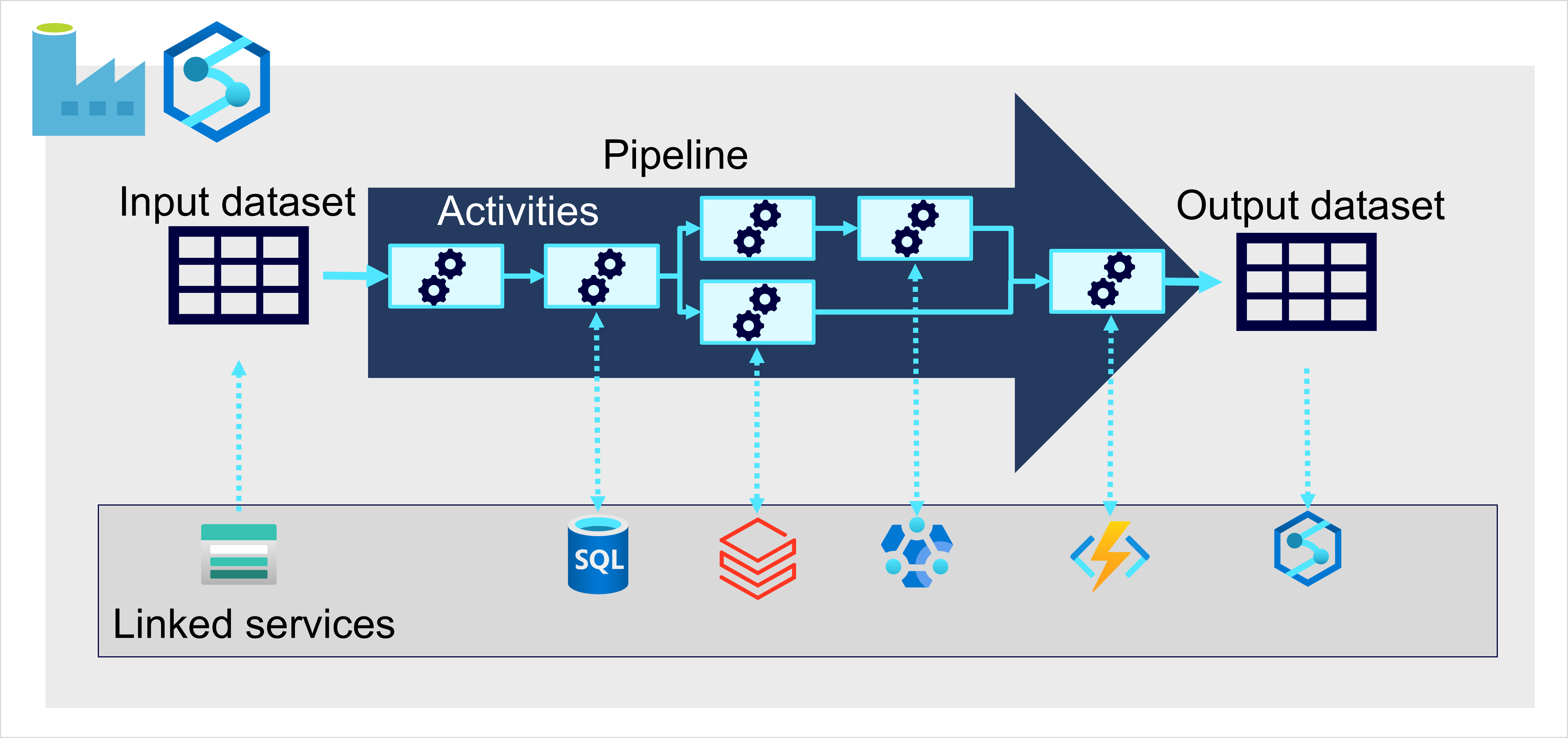
В Azure прием больших объемов данных наилучшим образом реализуется путем создания конвейеров, координирующих процессы ETL. Вы можете создавать и запускать конвейеры с помощью Фабрика данных Azure или использовать возможности конвейера в Microsoft Fabric, если вы хотите управлять всеми компонентами решения хранения данных в единой рабочей области.
В любом случае конвейеры состоят из одного или нескольких действий, которые работают с данными. Набор входных данных предоставляет исходные данные, а действия можно определить как поток данных, который постепенно обрабатывает данные до тех пор, пока не будет создан набор выходных данных. Конвейеры используют связанные службы для загрузки и обработки данных — это позволяет использовать правильную технологию для каждого этапа рабочего процесса. Например, можно использовать связанную службу Хранилища BLOB-объектов Azure для приема входного набора данных, а затем использовать службы, такие как База данных SQL Azure для выполнения хранимой процедуры, которая ищет связанные значения данных, перед выполнением задачи обработки данных в Azure Databricks или применение пользовательской логики с помощью функции Azure. Наконец, можно сохранить выходной набор данных в связанной службе, например Microsoft Fabric. Конвейеры также могут содержать некоторые встроенные действия, для которых не требуется связанная служба.