Сбор, запрос и визуализация состояний работоспособности
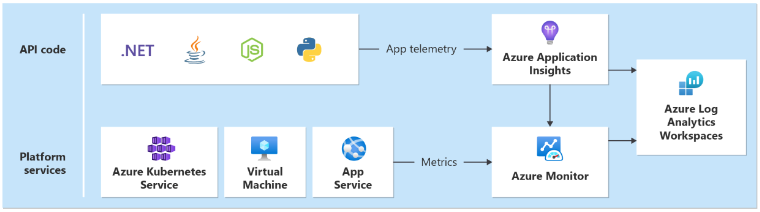
Чтобы точно представить модель работоспособности, необходимо собрать различные наборы данных из системы. Наборы данных включают журналы и метрики производительности из компонентов приложений и базовых ресурсов Azure. Важно сопоставить данные между наборами данных для создания многоуровневого представления работоспособности системы.
Инструментирование кода и инфраструктуры
Единый приемник данных необходим, чтобы все операционные данные хранились и доступны в одном расположении, где собираются все данные телеметрии. Например, когда сотрудник создает комментарий в веб-браузере, вы можете отслеживать эту операцию и видеть, что запрос прошел через API каталога для Центры событий Azure. Оттуда фоновый процессор взял комментарий и сохраняет его в Azure Cosmos DB.
Azure Monitor Log Analytics служит основным единым приемником данных Azure для хранения и анализа операционных данных:
Application Insights — это рекомендуемое средство Монитор производительности приложений (APM) для сбора журналов приложений, метрик и трассировок. Application Insights развертывается в конфигурации на основе рабочей области в каждом регионе.
В примере приложения Функции Azure используется в Microsoft .NET 6 для внутренних служб для собственной интеграции. Так как внутренние приложения уже существуют, Contoso Shoes создает только новый ресурс Application Insights в Azure и настраивает
APPLICATIONINSIGHTS_CONNECTION_STRINGпараметр для обоих приложений-функций. Среда выполнения Функции Azure автоматически регистрирует поставщика ведения журнала Application Insights, поэтому данные телеметрии отображаются в Azure без дополнительных усилий. Для более настраиваемогоILoggerведения журнала можно использовать интерфейс.Централизованный набор данных — это антипаттерн для критически важных рабочих нагрузок. Каждый регион должен иметь свою выделенную рабочую область Log Analytics и экземпляр Application Insights. Для глобальных ресурсов рекомендуется использовать отдельные экземпляры. Сведения о базовом шаблоне архитектуры см. в статье "Архитектура" для критически важных рабочих нагрузок в Azure.
Каждый слой должен отправлять данные в одну рабочую область Log Analytics, чтобы упростить анализ и вычисления работоспособности.
Запросы мониторинга работоспособности
Log Analytics, Application Insights и Azure Data Explorer используют язык запросов Kusto (KQL) для своих запросов. С помощью KQL можно создавать запросы и использовать функции для получения метрик и вычисления показателей работоспособности.
Сведения о отдельных службах, которые вычисляют состояние работоспособности, см. в следующих примерах запросов.
API каталога
В следующем примере демонстрируется запрос API каталога:
let _maxAge = 2d; // Include data only from the last two days
let _timespanStart = ago(_maxAge); // Start time for the time span
let _timespanEnd = now(-2m); // Account for ingestion lag by stripping the last 2m
// For time frame, compare the averages to the following threshold values
let Thresholds=datatable(MetricName: string, YellowThreshold: double, RedThreshold: double) [
"failureCount", 10, 50, // Failed requests, anything non-200, allow a few more than 0 for user-caused errors like 404s
"avgProcessingTime", 150, 500 // Average duration of the request, in ms
];
// Calculate average processing time for each request
let avgProcessingTime = AppRequests
| where AppRoleName startswith "CatalogService"
| where OperationName != "GET /health/liveness" // Liveness requests don't do any processing, including them would skew the results
| make-series Value = avg(DurationMs) default=0 on TimeGenerated from _timespanStart to _timespanEnd step 1m
| mv-expand TimeGenerated, Value
| extend TimeGenerated = todatetime(TimeGenerated), Value=toreal(Value), MetricName= 'avgProcessingTime';
// Calculate failed requests
let failureCount = AppRequests
| where AppRoleName startswith "CatalogService" // Liveness requests don't do any processing, including them would skew the results
| where OperationName != "GET /health/liveness"
| make-series Value=countif(Success != true) default=0 on TimeGenerated from _timespanStart to _timespanEnd step 1m
| mv-expand TimeGenerated, Value
| extend TimeGenerated = todatetime(TimeGenerated), Value=toreal(Value), MetricName= 'failureCount';
// Union all together and join with the thresholds
avgProcessingTime
| union failureCount
| lookup kind = inner Thresholds on MetricName
| extend IsYellow = iff(todouble(Value) > YellowThreshold and todouble(Value) < RedThreshold, 1, 0)
| extend IsRed = iff(todouble(Value) > RedThreshold, 1, 0)
| project-reorder TimeGenerated, MetricName, Value, IsYellow, IsRed, YellowThreshold, RedThreshold
| extend ComponentName="CatalogService"
Azure Key Vault
В следующем примере демонстрируется запрос Azure Key Vault:
let _maxAge = 2d; // Include data only from the last two days
let _timespanStart = ago(_maxAge); // Start time for the time span
let _timespanEnd = now(-2m); // Account for ingestion lag by stripping the last 2m
// For time frame, compare the averages to the following threshold values
let Thresholds = datatable(MetricName: string, YellowThreshold: double, RedThreshold: double) [
"failureCount", 3, 10 // Failure count on key vault requests
];
let failureStats = AzureDiagnostics
| where TimeGenerated > _timespanStart
| where ResourceProvider == "MICROSOFT.KEYVAULT"
// Ignore authentication operations that have a 401. This is normal when using Key Vault SDK. First an unauthenticated request is made, then the response is used for authentication
| where Category=="AuditEvent" and not (OperationName == "Authentication" and httpStatusCode_d == 401)
| where OperationName in ('SecretGet','SecretList','VaultGet') or '*' in ('SecretGet','SecretList','VaultGet')
// Exclude Not Found responses because these happen regularly during 'Terraform plan' operations, when Terraform checks for the existence of secrets
| where ResultSignature != "Not Found"
// Create ResultStatus with all the 'success' results bucketed as 'Success'
// Certain operations like StorageAccountAutoSyncKey have no ResultSignature; for now, also set to 'Success'
| extend ResultStatus = case ( ResultSignature == "", "Success",
ResultSignature == "OK", "Success",
ResultSignature == "Accepted", "Success",
ResultSignature);
failureStats
| make-series Value=countif(ResultStatus != "Success") default=0 on TimeGenerated from _timespanStart to _timespanEnd step 1m
| mv-expand TimeGenerated, Value
| extend TimeGenerated = todatetime(TimeGenerated), Value=toreal(Value), MetricName="failureCount", ComponentName="Keyvault"
| lookup kind = inner Thresholds on MetricName
| extend IsYellow = iff(todouble(Value) > YellowThreshold and todouble(Value) < RedThreshold, 1, 0)
| extend IsRed = iff(todouble(Value) > RedThreshold, 1, 0)
Оценка Работоспособность служб каталога
В конечном итоге можно связать различные запросы состояния работоспособности, чтобы вычислить оценку работоспособности компонента. В следующем примере запроса показано, как вычислить оценку Работоспособность служб каталога:
CatalogServiceHealthStatus()
| union AksClusterHealthStatus()
| union KeyvaultHealthStatus()
| union EventHubHealthStatus()
| where TimeGenerated < ago(2m)
| summarize YellowScore = max(IsYellow), RedScore = max(IsRed) by bin(TimeGenerated, 2m)
| extend HealthScore = 1 - (YellowScore * 0.25) - (RedScore * 0.5)
| extend ComponentName = "CatalogService", Dependencies="AKSCluster,Keyvault,EventHub" // These values are added to build the dependency visualization
| order by TimeGenerated desc
Совет
Дополнительные примеры запросов см. в репозитории GitHub Для критически важных задач Azure.
Настройка оповещений на основе запросов
Оповещения вызывают немедленное внимание на проблемы, которые отражают или влияют на состояние работоспособности. Всякий раз, когда в состоянии работоспособности изменяется состояние работоспособности( желтый) или в неработоспособное (красное) состояние, уведомления должны отправляться в подотчетную команду. Задайте оповещения на корневом узле модели работоспособности, чтобы сразу же узнать о любых изменениях уровня бизнеса в состоянии работоспособности решения. Затем можно просмотреть визуализации модели работоспособности, чтобы получить дополнительные сведения и устранить неполадки.
В примере используются оповещения Azure Monitor для выполнения автоматических действий в ответ на изменения состояния работоспособности приложения.
Использование панелей мониторинга для визуализации
Важно визуализировать модель работоспособности, чтобы быстро понять влияние сбоя компонента на всю систему. Конечная цель модели здравоохранения заключается в том, чтобы упростить быструю диагностику путем предоставления информированного представления о отклонениях от устойчивого состояния.
Типичным способом визуализации сведений о работоспособности системы является объединение многоуровневого представления модели работоспособности с возможностями детализации телеметрии на панели мониторинга.
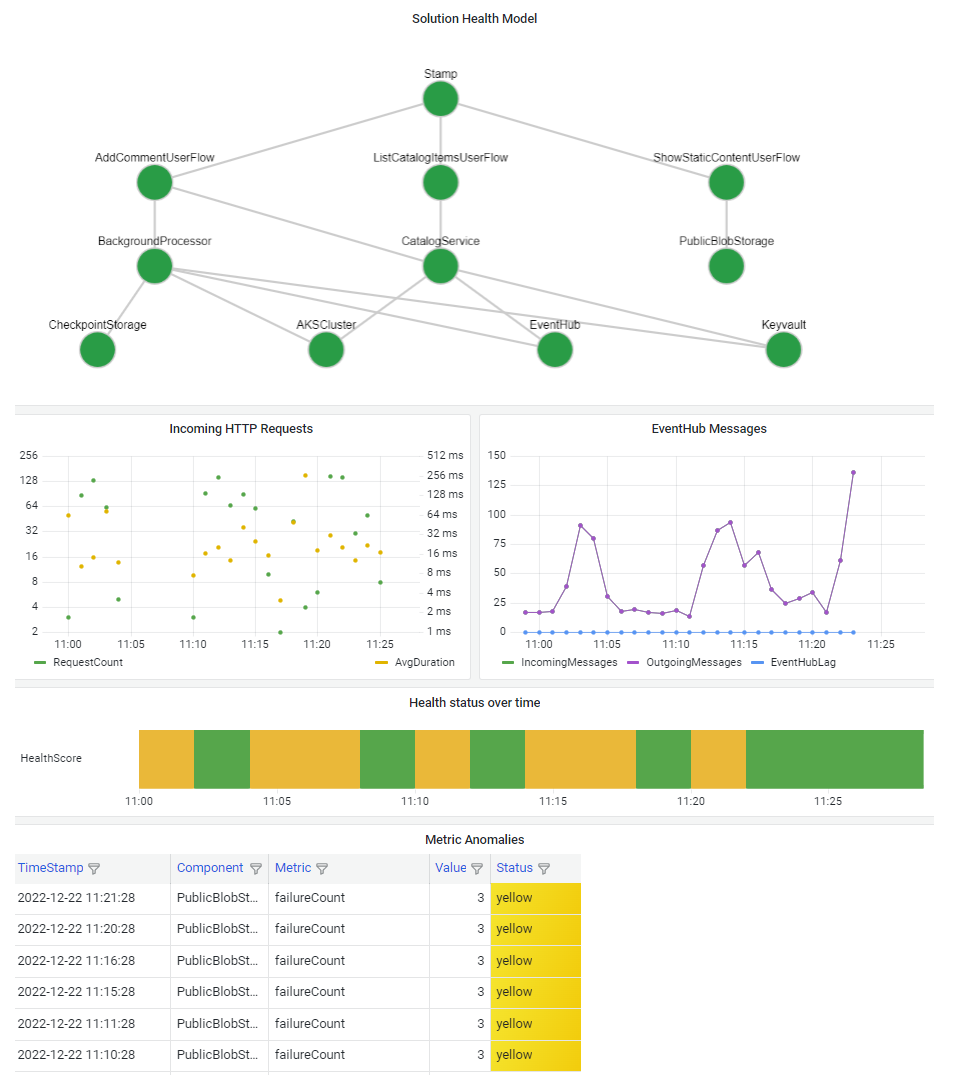
Технология панели мониторинга должна представлять модель работоспособности. Популярные варианты: панели мониторинга Azure, Power BI и Azure Managed Grafana.