Понимание и тестирование модели
Мы создали модель машинного обучения! Давайте теперь ее протестируем и посмотрим, насколько хорошо она работает.
Эффективность модели
При тестировании модели Пользовательское визуальное распознавание отображает три метрики. Метрики — это индикаторы, которые помогают понять, как работает модель. Эти индикаторы не указывают, насколько модель точна или соответствует реальности. Индикаторы сообщают только о том, как модель работает с предоставленными данными. Зная, насколько хорошо модель работает с известными данными, вы получите представление о том, что будет происходить с новыми данными.
Следующие метрики предоставляются для всей модели и для каждого класса:
| Метрическая | Description |
|---|---|
precision |
Если модель прогнозирует тег, эта метрика указывает вероятность того, что спрогнозирован правильный тег. |
recall |
Эта метрика указывает процент тегов, правильно спрогнозированных моделью, среди тегов, которые должны быть правильно спрогнозированы. |
average precision |
Эта метрика измеряет производительность модели, вычисляя точность и полноту при разных пороговых значениях. |
При тестировании модели Пользовательского визуального распознавания мы будем видеть числа для каждой из этих метрик в результатах теста итерации.
Распространенные ошибки
Прежде чем протестировать модель, давайте рассмотрим некоторые из ошибок новичков, о которых следует знать, если вы впервые создаете модели машинного обучения.
Использование несбалансированных данных
Это предупреждение может появиться при развертывании модели:
Unbalanced data detected. The distribution of images per tag should be uniform to ensure model performance.
Это предупреждение означает, что у вас нет четного числа выборок для каждого класса данных. Хотя в этом сценарии есть несколько вариантов, распространенным способом решения проблемы с несбалансированными данными является использование метода избыточной выборки синтетического меньшинства (SMOTE). Метод SMOTE копирует примеры обучения из существующего пула обучения.
Примечание.
В нашей модели это предупреждение может не отображаться, особенно если вы загрузили часть набора данных. Поднабор данных о краснохвостом ястребе (темной морфы) для модели содержит менее 60 фотографий. Это существенно меньше, чем в поднаборах для других моделей, содержащих более 100 фотографий. Использование несбалансированных данных следует отслеживать в любой модели машинного обучения.
Переобучение модели
Если у вас недостаточно данных или данные недостаточно разнообразны, модель может переобучиться. При этом модель хорошо распознает предоставленный набор данных и переобучается, учитывая закономерности в этих конкретных данных. В таком случае модель будет хорошо работать с обучающими данными, но не с новыми данными, которые раньше не использовались. По этой причине мы всегда будем использовать новые данные для тестирования модели!
Использование обучающих данных для тестирования
Как и в случае с переобучением, при тестировании модели с использованием тех же данных, что использовались для обучения, модель будет работать правильно. Но при развертывании модели в рабочей среде она, скорее всего, будет работать плохо.
Использование некачественных данных
Другой распространенной ошибкой является использование некачественных данных для обучения модели. Некоторые данные могут на самом деле снизить точность модели, например данные с шумами. В таких наборах данных содержится слишком много нерелевантных сведений, которые запутывают модель. Повышение объема данных хорошо только в том случае, если используемые моделью данные являются качественными. Для повышения точности модели может потребоваться очистить данные или удалить признаки.
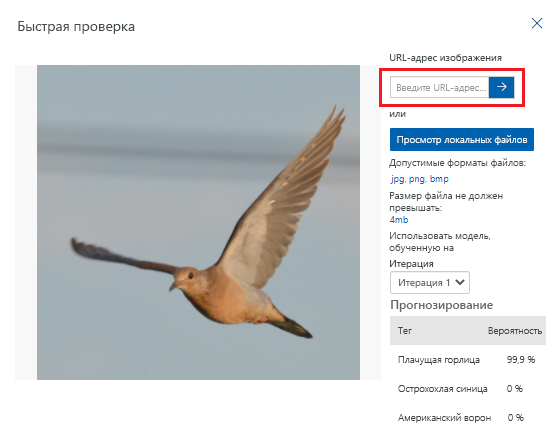
Тестирование модели
В соответствии с метриками, предоставляемыми Пользовательским визуальным распознаванием, наша модель работает удовлетворительно. Протестируем нашу модель и посмотрим, как она работает с данными, которых не видела ранее. Мы будем использовать изображение птицы, найденное в Интернете.
В веб-браузере найдите изображение птицы одного из видов, которые модель была обучена распознавать. Скопируйте URL-адрес изображения.
На портале Пользовательского визуального распознавания выберите проект Классификация птиц.
В строке меню вверху выберите Быстрый тест.
В области Быстрый тест вставьте URL-адрес в поле URL-адрес изображения, а затем нажмите клавишу ВВОД, чтобы проверить точность модели. Прогноз отображается в окне.
Пользовательское визуальное распознавание проанализирует изображение для проверки точности модели и отобразит результаты:
На следующем шаге мы выполним развертывание модели. После развертывания модели можно выполнить дополнительное тестирование с помощью созданной нами конечной точки.