Упражнение. Выполнение запросов к кластеру HDInsight Spark
В этом упражнении вы узнаете, как создать кадр данных из CSV-файла и отправлять интерактивные запросы SQL Spark к кластеру Apache Spark в Azure HDInsight. В Spark кадр данных — это распределенная коллекция данных, упорядоченных в именованных столбцах. Она эквивалентна таблице в реляционной базе данных или кадру данных в R или Python.
В этом руководстве описано следующее:
- Создание кадра данных из CSV-файла
- Выполнение запросов к кадру данных
Создание кадра данных из CSV-файла
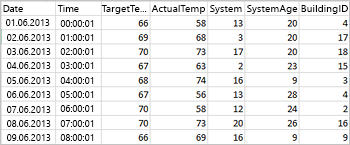
Приведенный ниже пример CSV-файла содержит сведения о температуре в здании и хранится в файловой системе кластера Spark.
Вставьте приведенный ниже код в пустую ячейку записной книжки Jupyter Notebook и нажмите SHIFT+ВВОД для выполнения кода. Код импортирует типы, необходимые для этого сценария.
from pyspark.sql import * from pyspark.sql. types import *При запуске интерактивного запроса в Jupyter в заголовке окна веб-браузера или вкладки будет отображаться состояние (Busy) (Занято), а также название записной книжки. Кроме того, рядом с надписью PySpark в верхнем правом углу окна будет показан закрашенный кружок. После завершения задания он изменится на кружок без заливки.
Выполните следующий код, чтобы создать кадр данных и временную таблицу hvac.
# Create a dataframe and table from sample data csvFile = spark.read.csv ('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write. saveAsTable("hvac")
Выполнение запросов к кадру данных
Когда таблица будет готова, выполните интерактивный запрос к данным.
В пустой ячейке приложения выполните следующий код:
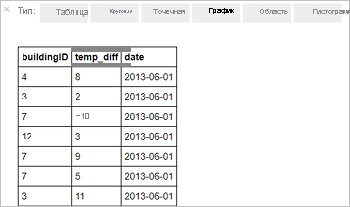
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"Отобразятся следующие табличные данные.
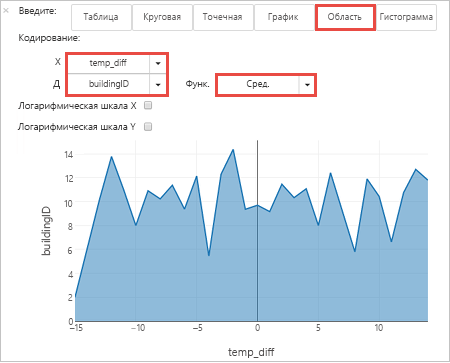
Результаты также можно просмотреть и в других визуализациях. Чтобы увидеть результат в виде диаграммы с областями, выберите Область и укажите другие значения, как показано ниже.
В строке меню записной книжки выберите Файл > Сохранить и создать контрольную точку.
Завершите работу записной книжки, чтобы освободить ресурсы кластера. В строке меню записной книжки выберите Файл > Закрыть и остановить.