Создание кластера HDInsight
Создать кластер HDInsight можно несколькими способами. Это может быть как удобный пользовательский интерфейс на портале Azure, так и скрипт установки, автоматизирующий развертывание. В приведенной ниже таблице представлены различные способы настройки кластера HDInsight.
| Метод создания кластеров | Веб-браузер | Командная строка | REST API | SDK |
|---|---|---|---|---|
| Портал Azure | ✔ | |||
| Azure Data Factory | ✔ | ✔ | ✔ | ✔ |
| Azure CLI | ✔ | |||
| Azure PowerShell | ✔ | |||
| cURL | ✔ | ✔ | ||
| Пакет SDK для .NET | ✔ | |||
| Шаблон Azure Resource Manager | ✔ |
Для любого способа установки HDInsight требуются указанные ниже основные сведения.
Вкладка "Основные сведения"
Сведения о проекте
Подписка
Определяет подписку Azure для выставления счетов за использование HDInsight и управления.
Имя группы ресурсов
Группа ресурсов — это логический набор технологий и служб Azure, которые обычно относятся к одному приложению или жизненному циклу приложения. Объединение служб в группу ресурсов упрощает обслуживание.
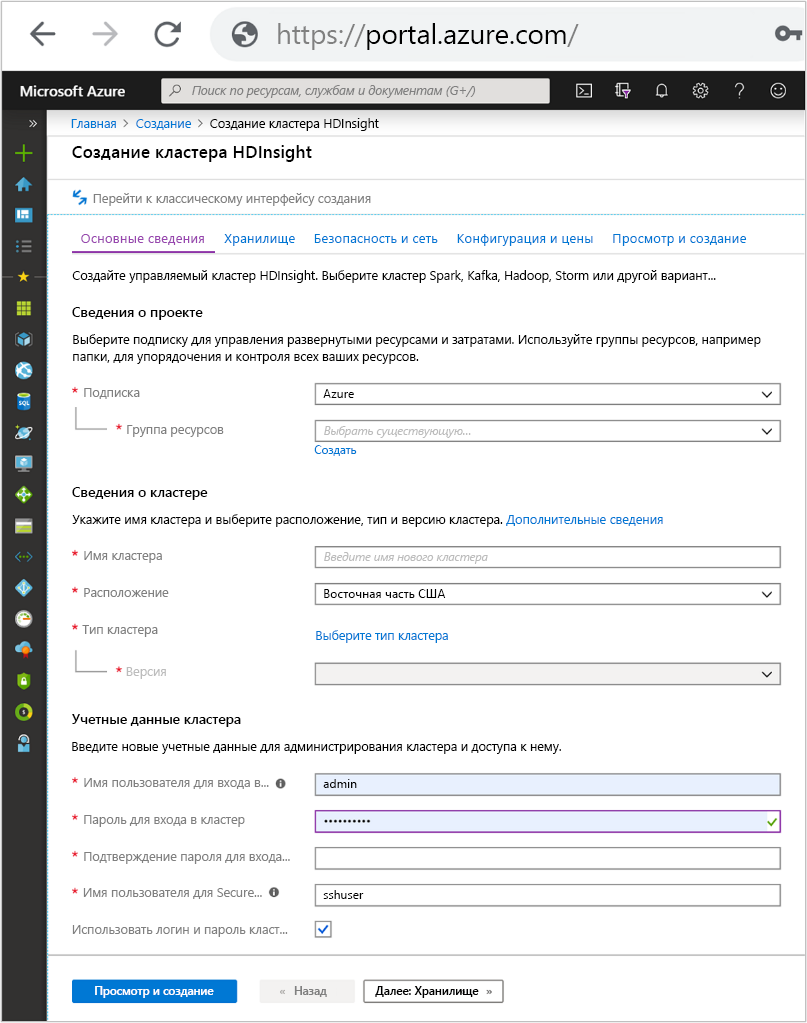
Сведения о кластере
Имя кластера
На имена кластеров HDInsight налагаются указанные ниже ограничения.
- Допустимые символы: a–z, 0–9, A–Z
- Максимальная длина: 59 символов
- Зарезервированные имена: apps
- Имена кластеров должны быть уникальными в рамках всех подписок Azure. То есть имя кластера должно быть уникальным по всему миру.
- Первые шесть символов должны быть уникальными в пределах виртуальной сети.
Местонахождение
Указывает расположение, в котором хранится тип кластера. Если расположение не определено, то кластер размещается в том же расположении, что и хранилище по умолчанию. Для сокращения задержки расположение должно быть как можно ближе к пользователям.
Типы кластеров
Определяет стек технологий, подготавливаемый в кластере ресурсов. При выборе типа кластера руководствуйтесь типом данных и требуемыми способами их обработки. Доступные типы кластеров представлены в таблице ниже.
| Тип кластера | Описание |
|---|---|
| Apache Hadoop | Платформа, в которой используется HDFS и простая модель программирования MapReduce для обработки и анализа пакетных данных. |
| Apache Spark | Платформа параллельной обработки с открытым кодом, которая поддерживает обработку в памяти, чтобы повысить производительность приложений для анализа больших данных. |
| HBase | База данных NoSQL, созданная на основе Hadoop и обеспечивающая прямой доступ и строгую согласованность для больших объемов неструктурированных и частично структурированных данных (с потенциальным размером таблиц в миллиарды строк и миллионы столбцов). |
| Интерактивный запрос Apache | Кэширование в памяти для обеспечения интерактивных и ускоренных запросов Hive. |
| Apache Kafka | Платформа с открытым исходным кодом, которая используется для создания конвейеров и приложений потоковой передачи данных. Kafka также предоставляет функциональные возможности очереди сообщений, с помощью которых можно публиковать потоки данных и подписываться на них. |
Версия
Определяет версию HDInsight для этого кластера. HDInsight 4.0 — это последняя версия, которая содержит новейшие платформы для кластеров.
Учетные данные кластера
Во время создания кластера HDInsight можно настроить две учетные записи пользователя.
Пароль для входа в кластер
Имя пользователя по умолчанию — администратор. Он использует базовую конфигурацию в портал Azure. Иногда его называют "пользователем кластера".
SSH username and password (Имя пользователя SSH и пароль)
это имя пользователя используется для подключения к кластеру через SSH.
Примечание.
Пакет безопасности предприятия позволяет интегрировать HDInsight с Active Directory и Apache Ranger. При помощи пакета безопасности корпоративного уровня можно создать нескольких пользователей.
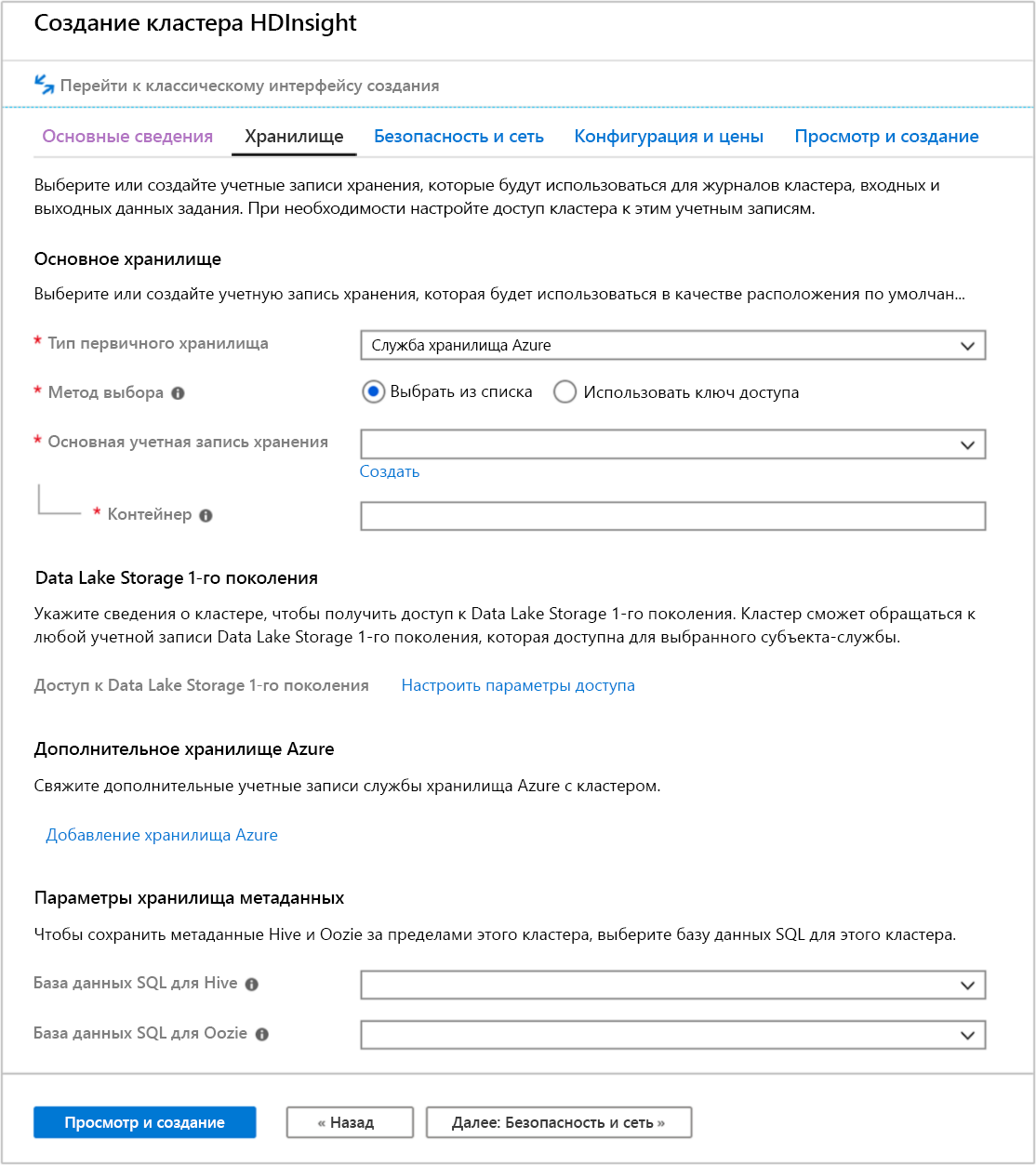
Вкладка хранилища
В кластерах HDInsight могут использоваться следующие варианты хранилища:
- Azure Data Lake Storage 2-го поколения
- Хранилище Azure Data Lake Storage 1-го поколения
- Служба хранилища Azure общего назначения версии 2
- Служба хранилища Azure общего назначения версии 1
- Служба хранилища Azure для блочных BLOB-объектов (поддерживается только в качестве дополнительного хранилища)
На экране хранилища можно определить основную учетную запись хранения и контейнер по умолчанию. Кроме того, с кластером можно связать дополнительную службу хранилища Azure. Параметры хранилища метаданных позволяют определить внешнюю базу данных SQL для хранения таблиц Hive после удаления кластера и повысить производительность Oozie за счет хранения метаданных во внешнем хранилище.
Безопасность + сеть
Для кластеров типа Hadoop, Spark, HBase, Kafka и Interactive Query вы можете включить Корпоративный пакет безопасности. Этот пакет предоставляет возможность более безопасной настройки кластера с помощью Apache Ranger и интеграции с идентификатором Microsoft Entra.
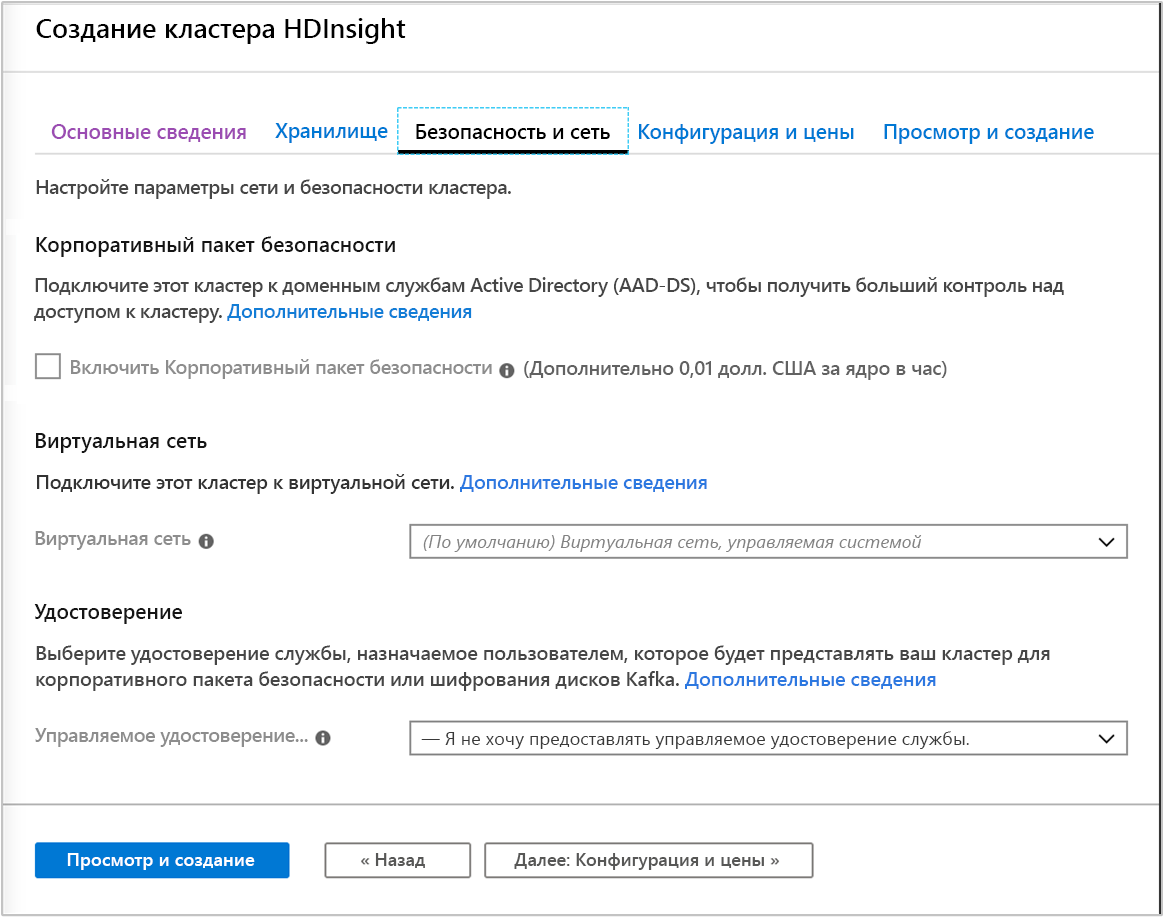
Кроме того, рекомендуется всегда развертывать кластеры HDInsight в виртуальной сети, которую можно определить и назначить на этом экране. Если для решения нужны технологии, распределенные по нескольким типам кластеров HDInsight, виртуальная сеть Azure может объединять необходимые типы кластеров. Благодаря такой конфигурации кластеры и любой развернутый в них код могут взаимодействовать друг с другом напрямую.
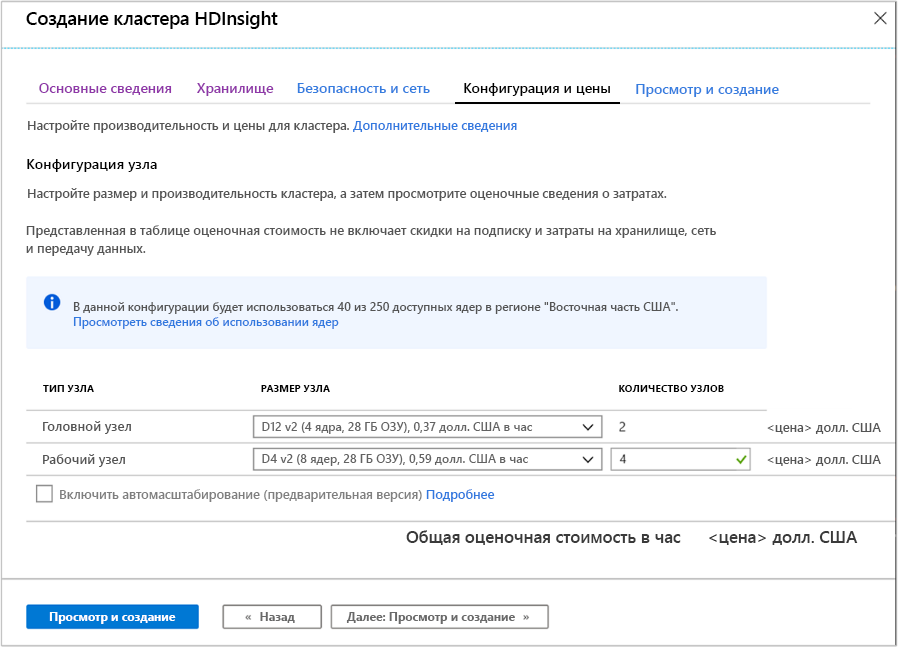
Конфигурация и цены
На этой странице можно настроить размер и производительность кластера, а затем просмотреть оценочные сведения о затратах. Вы также можете определить виртуальные машины, которые будут использоваться для головных (главных) и рабочих узлов.