Навык классификации пользовательского текста
Пользовательская классификация текста позволяет сопоставить фрагмент текста с разными пользовательскими классами. Например, можно обучить модель на основе синопсиса, опубликованного на задней обложке книг, для автоматического определения жанра книг. Затем вы будете использовать этот определенный жанр для обогащения поисковой системы интернет-магазина с помощью аспекта "жанр".
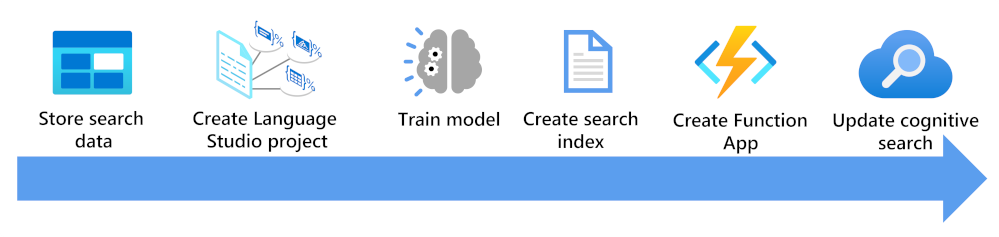
Здесь вы увидите, что необходимо учитывать для обогащения индекса поиска с помощью пользовательской модели классификации текста:
- Сохраните свои документы, чтобы они могли получить доступ к ним с помощью языковых студий и индексаторов поиска Azure ИИ.
- создание пользовательского проекта классификации текстов;
- Обучение и тестирование модели.
- Создайте индекс поиска на основе сохраненных документов.
- Создайте приложение-функцию, использующее развернутую обученную модель.
- Обновите решение поиска, индексатор, индексатор и настраиваемый набор навыков.
Хранение данных
Доступ к хранилищу BLOB-объектов Azure можно получить как из Language Studio, так и из служб ИИ Azure. Контейнер должен быть доступным, поэтому самым простым вариантом является выбор контейнера, но кроме того можно использовать частные контейнеры с определенной дополнительной конфигурацией.
Наряду с данными также требуется способ назначения классификаций для каждого документа. Language Studio предоставляет графический инструмент, который можно использовать для классификации каждого отдельного документа вручную.
Вы можете выбрать один из двух различных типов проекта. Если документ сопоставляется с одним классом, используйте проект классификации одной метки. Если вы хотите сопоставить документ с несколькими классами, используйте проект классификации нескольких меток.
Если вы не хотите вручную классифицировать каждый документ, перед созданием проекта языка искусственного интеллекта Azure можно пометить все документы. Этот процесс включает в себя создание документа JSON с метками в следующем формате:
{
"projectFileVersion": "2022-05-01",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectKind": "CustomMultiLabelClassification",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectName": "{PROJECT-NAME}",
"multilingual": false,
"description": "Project-description",
"language": "en-us"
},
"assets": {
"projectKind": "CustomMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
}
]
}
Вы добавляете в массив classes столько классов, сколько у вас есть. Вы добавляете запись для каждого документа в массиве documents, включая классы, которым соответствует документ.
Создание проекта языка ИИ Azure
Существует два способа создания проекта языка искусственного интеллекта Azure. Если вы начинаете использовать Language Studio без первого создания языковой службы в портал Azure, Language Studio предложит создать его для вас.
Самый гибкий способ создания проекта языка ИИ Azure — сначала создать языковую службу с помощью портал Azure. При выборе этого параметра вы получаете возможность добавить пользовательские функции.
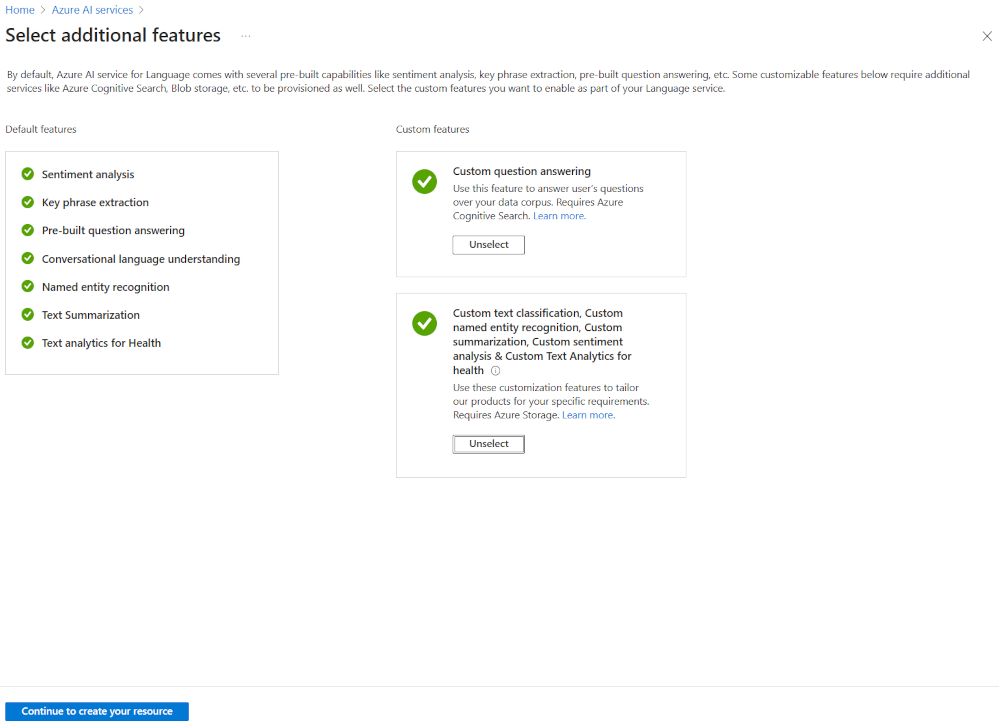
При создании пользовательской классификации текста выберите эту пользовательскую функцию при создании языковой службы. Также необходимо связать языковую службу с учетной записью хранения с помощью этого метода.
После развертывания ресурса можно перейти непосредственно к Language Studio из области обзора языковой службы. Затем можно создать новый проект пользовательской классификации текста.
Примечание.
Если вы создали языковую службу из Языковой студии, вам может потребоваться выполнить следующие действия. Задайте роли для ресурса языка Azure и учетной записи хранения, чтобы подключить контейнер хранилища к проекту пользовательской классификации текста.
Обучение модели классификации
Как и во всех моделях ИИ, необходимо определить данные, которые можно использовать для обучения. Модель должна видеть примеры сопоставления данных с классом и некоторые примеры, которые можно использовать для тестирования модели. Вы можете разрешить модели автоматически разделить данные обучения, по умолчанию она будет использовать 80% документов для обучения модели и 20% для слепого тестирования. Если у вас есть определенные документы, с использованием которых вы хотите протестировать модель, можно пометить документы для тестирования.

В Language Studio в проекте выберите метки данных. Отобразятся все ваши документы. Выберите каждый документ, который требуется добавить в набор тестирования, а затем выберите "Тестирование производительности модели". Сохраните обновленные метки и создайте новое задание обучения.
Создание индекса поиска
Для создания индекса поиска, который будет обогащен пользовательской моделью классификации текста, не требуется специальных действий. Выполните действия, описанные в статье "Создание решения поиска ИИ Azure". После создания приложения-функции вы обновите индекс, индексатор и пользовательский навык.
Создание приложения-функции Azure
Вы можете выбрать нужный язык и технологии для приложения-функции. Приложение должно иметь возможность передавать JSON в конечную точку пользовательской классификации текста, например:
{
"displayName": "Extracting custom text classification",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "en-us",
"text": "This film takes place during the events of Get Smart. Bruce and Lloyd have been testing out an invisibility cloak, but during a party, Maraguayan agent Isabelle steals it for El Presidente. Now, Bruce and Lloyd must find the cloak on their own because the only non-compromised agents, Agent 99 and Agent 86 are in Russia"
}
]
},
"tasks": [
{
"kind": "CustomMultiLabelClassification",
"taskName": "Multi Label Classification",
"parameters": {
"project-name": "movie-classifier",
"deployment-name": "test-release"}
}
]
}
Затем обработайте ответ JSON из модели, например:
{
"jobId": "be1419f3-61f8-481d-8235-36b7a9335bb7",
"lastUpdatedDateTime": "2022-06-13T16:24:27Z",
"createdDateTime": "2022-06-13T16:24:26Z",
"expirationDateTime": "2022-06-14T16:24:26Z",
"status": "succeeded",
"errors": [],
"displayName": "Extracting custom text classification",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "CustomMultiLabelClassificationLROResults",
"taskName": "Multi Label Classification",
"lastUpdateDateTime": "2022-06-13T16:24:27.7912131Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "1",
"class": [
{
"category": "Action",
"confidenceScore": 0.99
},
{
"category": "Comedy",
"confidenceScore": 0.96
}
],
"warnings": []
}
],
"errors": [],
"projectName": "movie-classifier",
"deploymentName": "test-release"
}
}
]
}
}
Затем функция возвращает структурированное сообщение JSON обратно в пользовательский набор навыков в поиске ИИ, например:
[{"category": "Action", "confidenceScore": 0.99}, {"category": "Comedy", "confidenceScore": 0.96}]
Есть пять факторов, которые должны быть известны приложению-функции:
- Текст, который необходимо классифицировать.
- Конечная точка для развернутой модели обученной пользовательской классификации текста.
- Первичный ключ для проекта пользовательской классификации текста.
- Имя проекта.
- Имя развертывания.
Текст, который необходимо классифицировать, передается из пользовательского набора навыков в поиске ИИ в функцию в качестве входных данных. Оставшиеся четыре элемента можно найти в Language Studio.

Имя конечной точки и развертывания отображается на панели развертывания модели.

Имя проекта и первичный ключ находятся на панели параметров проекта.
Обновление решения поиска ВИ Azure
В портал Azure необходимо внести три изменения, чтобы дополнить индекс поиска:
- Необходимо добавить в индекс поле для хранения обогащения пользовательской классификации текста.
- Необходимо добавить пользовательский набор навыков для вызова приложения-функции с текстом для классификации.
- Необходимо сопоставить ответ из набора навыков с индексом.
Добавление поля в существующий индекс
В портал Azure перейдите к ресурсу поиска ИИ, выберите индекс и добавьте JSON в этом формате:
{
"name": "classifiedtext",
"type": "Collection(Edm.ComplexType)",
"analyzer": null,
"synonymMaps": [],
"fields": [
{
"name": "category",
"type": "Edm.String",
"facetable": true,
"filterable": true,
"key": false,
"retrievable": true,
"searchable": true,
"sortable": false,
"analyzer": "standard.lucene",
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
},
{
"name": "confidenceScore",
"type": "Edm.Double",
"facetable": true,
"filterable": true,
"retrievable": true,
"sortable": false,
"analyzer": null,
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
}
]
}
Этот код JSON добавляет составное поле в индекс для хранения класса в поле category, доступном для поиска. Второе поле confidenceScore сохраняет процент достоверности в двойном поле.
Изменение пользовательского набора навыков
На портале Azure выберите набор навыков и добавьте JSON в следующем формате:
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "Genre Classification",
"description": "Identify the genre of your movie from its summary",
"context": "/document",
"uri": "https://learn-acs-lang-serives.cognitiveservices.azure.com/language/analyze-text/jobs?api-version=2022-05-01",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 1,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "lang",
"source": "/document/language"
},
{
"name": "text",
"source": "/document/content"
}
],
"outputs": [
{
"name": "text",
"targetName": "class"
}
],
"httpHeaders": {}
}
Это определение навыка WebApiSill указывает, что язык и содержимое документа передаются в качестве входных данных в приложение-функцию. Приложение возвращает текст JSON с именем class.
Сопоставление выходных данных приложения-функции с индексом
Последнее изменение предусматривает сопоставление выходных данных с индексом. На портале Azure выберите индексатор и измените JSON, чтобы создать новое сопоставление выходных данных:
{
"sourceFieldName": "/document/class",
"targetFieldName": "classifiedtext"
}
Теперь индексатор знает, что выходные данные приложения-функции document/class должны храниться в поле classifiedtext. Учитывая, что это поле было определено как составное, приложение-функция должно вернуть массив JSON, содержащий поля category и confidenceScore.
Теперь вы можете выполнять поиск обогащенного индекса поиска для пользовательского классифицированного текста.