Реализация устойчивости при проектировании и определении политик
В связи с термином "аварийное восстановление" можно часто услышать термин "непрерывность бизнес-процессов". Слово "непрерывность" имеет положительный смысл. Оно означает, что в идеале масштаб аварии или менее серьезного происшествия должен ограничиваться стенами центра обработки данных.
Однако "непрерывность" не является инженерным термином, несмотря на все попытки сделать его таковым. Не существует единой формулы, методологии или рецепта для обеспечения непрерывности бизнес-процессов. В каждой организации может быть уникальный набор рекомендаций, зависящих от рода ее деятельности и способа ее осуществления. Непрерывность — это результат успешного применения таких рекомендаций.
Значение устойчивости
У инженеров есть понятие устойчивости. Когда система хорошо работает в различных условиях, она считается устойчивой. Менеджер по рискам считает, что организация хорошо подготовлена, если в ней реализованы средства резервирования, меры безопасности и процедуры на случай аварии, позволяющие реагировать на любые неблагоприятные обстоятельства. Инженер не может рассматривать среду, в которой работает система, в таких категоричных терминах, как "нормальная работа" и "под угрозой", "безопасность" и "авария". Он считает, что система, поддерживающая бизнес-процессы, находится в порядке, если она непрерывно обеспечивает предсказуемые уровни обслуживания при неблагоприятных обстоятельствах.
В 2011 году, когда облачные вычисления начали набирать популярность в центрах обработки данных, Европейское агентство по сетевой и информационной безопасности (ENISA, орган Европейского союза) опубликовало составленный по поручению правительства ЕС отчет, в котором анализировалась устойчивость систем, используемых правительством для сбора информации. В отчете прямо заявлялось, что у специалистов по ИКТ (в Европе ИКТ — это синоним термина ИТ и означает информационно-коммуникационные технологии) до сих пор нет единого мнения в отношении того, что на самом деле означает "устойчивость" и как ее измерять.
В результате агентство ENISA обратило внимание на проект, проводимый командой исследователей из Канзасского университета под руководством профессора Джеймса П. Г. Штербенца (James P. G. Sterbenz) и предназначенный для развертывания в Министерстве обороны США. Он называется Resilient and Survivable Networking Initiative (ResiliNets)1 и представляет собой метод визуализации постоянно меняющегося состояния устойчивости в информационных системах в различных обстоятельствах. ResiliNets является прототипом для согласованной модели политики устойчивости в организациях.
Модель Канзасского университета включает в себя ряд знакомых, легко объяснимых метрик, некоторые из которых уже были рассмотрены в этой главе. К ним относятся:
Отказоустойчивость — как уже говорилось, это способность системы обеспечивать ожидаемые уровни обслуживания при наличии ошибок.
Устойчивость к перебоям — способность той же системы обеспечивать ожидаемые уровни обслуживания в непредсказуемых и часто экстремальных условиях работы, которые создаются не самой системой. Это может быть, например, отключение электроэнергии, нехватка пропускной способности Интернета и резкие скачки трафика.
Устойчивость к условиям — оценка способности системы обеспечивать разумные, пусть и не всегда номинальные, уровни производительности во всех возможных обстоятельствах, включая стихийные бедствия.
Одно из основных теоретических положений, лежащих в основе проекта ResiliNets, заключается в том, что устойчивость информационных систем в количественном выражении зависит как от качества системного проектирования, так и от действий операторов. Благодаря тому, что делают люди, а точнее, что они продолжают делать в рамках повседневной деятельности, системы становятся надежнее.
Принимая подсказку от того, как солдаты, моряки и морские пехотинцы в активном театре операций учатся и помнят принципы тактического развертывания, команда KU предложила спину салфетки mnemonic для запоминания жизненного цикла практики ResiliNets: D2R2 + DR. Как показано на рисунке 9, буквы здесь означают следующие этапы:**
защита (Defend) системы от угроз для нормальной работы;
обнаружение (Detect) неблагоприятного воздействия, вызванного возможными ошибками или внешними обстоятельствами;
противодействие (Remediate) этому воздействию на систему, даже если его последствия еще не проявились;
восстановление (Recover) нормальных уровней обслуживания;
диагностика (Diagnose) основных причин происшествия;
корректировка (Refine) будущего поведения по мере необходимости с целью лучше подготовиться к повторным происшествиям.
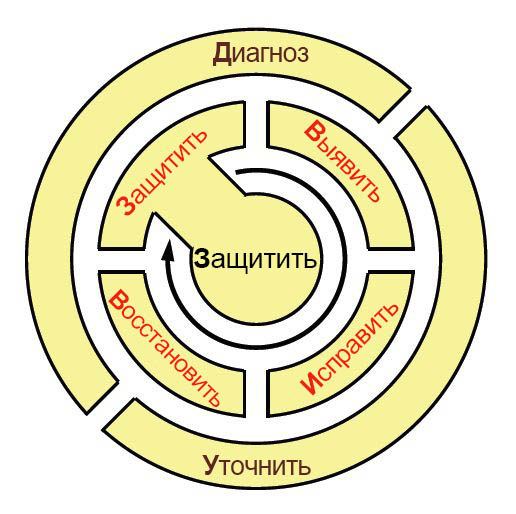
Рис. 9. Жизненный цикл действий в среде, используюющей ResiliNets.
На каждом из этих этапов получается ряд метрик производительности и операционных метрик, связанных как с людьми, так и с системами. Сочетание этих метрик образует точки, которые можно построить на графике в евклидовой плоскости, как показано на рисунке 9.10. Каждая метрика может быть сокращена до двух одномерных значений: одна, которая отражает параметры уровня обслуживания P и другую, представляющую рабочее состояние N. Так как все шесть этапов цикла ResiliNets реализуются и повторяются, состояние службы S отображается на диаграмме по координатам (N, P).
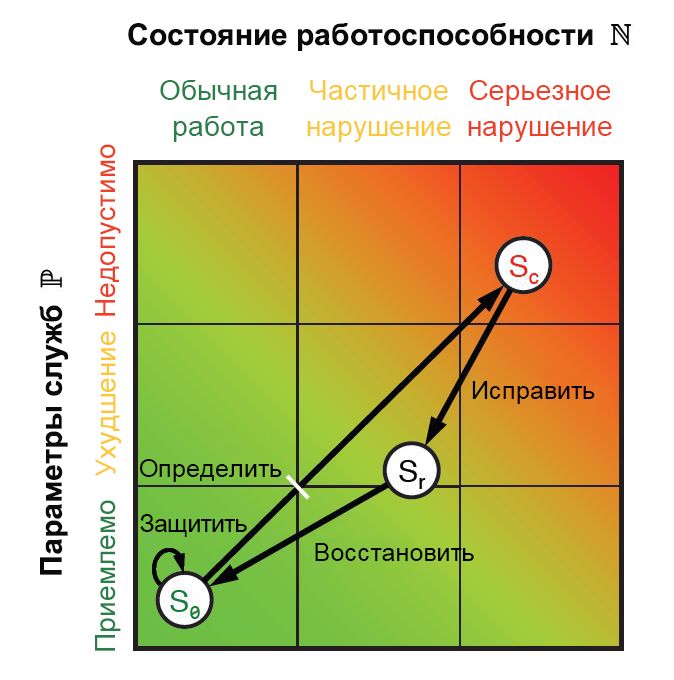
Рис. 10. Пространство состояния ResiliNets и внутренний цикл стратегии.
Если цели обслуживания в организации выполняются, ее состояние S будет находиться недалеко от левого нижнего угла графика. Желательно, чтобы оно не отдалялось сильно от этого положения в течение всего периода времени, который называется внутренним циклом. Когда происходит отклонение от целей обслуживания, состояние начинает двигаться по нежелательному вектору в направлении правого верхнего угла.
Хотя модель ResiliNets не стала универсальным представлением устойчивости ИТ-инфраструктуры на предприятии, ее принятие некоторыми крупными организациями, особенно в государственном секторе, инициировало ряд перемен, которые послужили катализатором для облачной революции.
Визуализация производительности. Чтобы описать текущее состояние устойчивости соответствующим заинтересованным лицам, не обязательно использовать сложную терминологию и формулировки. На самом деле, его можно продемонстрировать без слов. Современные платформы управления производительностью, получающие метрики из облака, имеют встроенные панели мониторинга и аналогичные средства, которые позволяют эффективно доносить информацию.
Для реализации мер и процедур восстановления не нужно ждать, когда наступит авария. Тщательно и грамотно спроектированная информационная система, обслуживаемая бдительными инженерами и операторами, предполагает повседневное выполнение процедур обслуживания, которые мало чем отличаются от процедур реагирования во время кризисной ситуации. Например, в среде с аварийным восстановлением методом горячей замены устранение проблемы с уровнем обслуживания может быть фактически автоматическим — главный маршрутизатор просто перенаправляет трафик от затронутых компонентов. Иначе говоря, подготовка к сбою — это не то же самое, что ожидание сбоя.
Главная составляющая информационных систем — люди. Автоматизация может повысить эффективность работы людей и результативность. Но она не может заменить людей в системе, которая должна реагировать на непредвиденные изменения обстоятельств и условий.
Вычисления, ориентированные на восстановление
ResiliNets — это лишь одна из реализаций концепции, которую корпорация Майкрософт выработала в самом начале нового столетия и которая называется вычисления, ориентированные на восстановление (ROC)2. Ее главный принцип заключается в том, что ошибки и неисправности — это неизменная часть любой вычислительной среды. Вместо того чтобы тратить массу времени на очистку среду от них, может быть выгоднее внедрить рациональные меры по повышению "иммунитета" среды. Это аналогично тому радикально новому представлению, распространившемуся непосредственно перед началом XX века, что руки нужно мыть несколько раз в день.
Устойчивость в общедоступном облаке
Все поставщики общедоступных облачных служб придерживаются принципов и методологий обеспечения устойчивости, даже если они называют это иначе. Однако облачная платформа не повышает устойчивость центра обработки данных организации, если на нее перенесены не все информационные ресурсы организации. Устойчивость гибридного облака напрямую зависит от бдительности ее администраторов. Если принять за данность, что администраторы поставщика облачных решений строго соблюдают требования к устойчивости (в противном случае они нарушали бы условия соглашения об уровне обслуживания), задача обеспечения устойчивости всей системы ложится на плечи клиента.
Стандарты устойчивости Azure
Международным стандартом в отношении стратегии обеспечения непрерывности бизнес-процессов является ISO 22301. Как и другие стандарты Международной организации по стандартизации (ISO), он устанавливает рекомендуемые методы и операции, соответствие которым позволяет организации пройти профессиональную сертификацию.
В этом стандарте ISO, на самом деле, не определяется понятие непрерывности бизнес-процессов или устойчивости. Вместо этого в нем формулируется, что означает непрерывность в собственном контексте организации. В руководящем документе говорится: "Организация идентифицирует и выбирает стратегии обеспечения непрерывности бизнес-процессов исходя из результатов анализа последствий для деятельности и оценки рисков. Стратегии непрерывности бизнес-процессов должны быть составлены из одного или нескольких решений". Он не переходит к перечислению того, что эти решения могут быть или должны быть.3
На рисунке 11 представлена многоэтапная реализация требований ISO 22301 в Azure. Обратите внимание на включение целевых показателей времени бесперебойной работы в соглашение об уровне обслуживания. Для клиентов, которые выбрали этот уровень устойчивости, Azure реплицирует виртуальные центры обработки данных в локальных зонах доступности, а затем подготавливает отдельные реплики, географически удаленные друг от друга на сотни километров. Однако по юридическим соображениям (особенно в целях выполнения законов Европейского союза о конфиденциальности) такая географическая избыточность обычно ограничивается "местом расположения данных", например Северной Америкой или Европой.
![Рис. 11. Azure Resiliency Framework, которая защищает активные компоненты на нескольких уровнях в соответствии со стандартом ISO 22301. [Предоставлено Microsoft]](../../cmu-cloud-admin/cmu-disaster-recovery-backup/media/fig9-11.jpg)
Рис. 11. Платформа устойчивости Azure, которая защищает активные компоненты на нескольких уровнях в соответствии с ISO 22301. [Предоставлено Майкрософт]
Хотя стандарт ISO 22301 связан с устойчивостью и часто описывается как набор рекомендаций по устойчивости, уровни устойчивости, на которых была протестирована платформа Azure, применимы только к ней, но не к размещаемым на ней ресурсам клиентов. Клиент по-прежнему несет ответственность за управление процессами, их обслуживание и регулярную оптимизацию, включая репликацию ресурсов в облаке Azure и на других платформах.
Google Container Engine
До недавних пор программное обеспечение воспринималось как состояние компьютера, то есть как нечто, функционально идентичное оборудованию, но существующее в цифровой форме. С такой точки зрения программное обеспечение рассматривалось как относительно статичный компонент информационной системы. Протоколы безопасности требовали регулярно обновлять программное обеспечение, и в этом случае "регулярно", как правило, означало несколько раз в год, по мере выпуска обновлений и исправлений ошибок.
Динамичный характер облака сделал возможным, неожиданно для многих ИТ-специалистов, постепенное, но в то же время быстрое усовершенствование программного обеспечения. Непрерывная интеграция и непрерывная поставка (CI/CD) — это новый набор принципов, позволяющих автоматизировать регулярное (зачастую ежедневное) внесение добавочных изменений в программном обеспечении как на стороне сервера, так и на стороне клиента. Пользователи смартфонов регулярно имеют дело с CI/CD, когда их приложения из магазинов приложений обновляются по несколько раз в неделю. Изменение, вносимое посредством CI/CD, может быть незначительным, однако сама возможность быстрого развертывания мелких изменений без каких-либо трудностей имела непредвиденный, но приятный побочный эффект — значительное повышение устойчивости информационных систем.
При использовании моделей развертывания CI/CD полностью избыточные кластеры серверов подготавливаются и обслуживаются, часто в общедоступной облачной инфраструктуре, исключительно в целях тестирования недавно созданных программных компонентов на наличие ошибок и последующего размещения этих компонентов в смоделированной рабочей среде для выявления потенциальных сбоев. Благодаря этому процессы исправления можно выполнять в защищенной среде, не оказывая прямого воздействия на уровни обслуживания клиентов или пользователей, пока исправления не будут применены, протестированы и утверждены к развертыванию.
Google Container Engine (GKE, где буква "K" означает Kubernetes) — это среда Google Cloud Platform для клиентов, развертывающих контейнерные приложения и службы, а не приложения на основе виртуальных машин. Полностью контейнерное развертывание может включать в себя микрослужбы ("μ-службы"), базы данных, которые отделены от рабочих нагрузок и предполагают независимую работу ("наборы данных с отслеживанием состояния"), зависимые библиотеки кода и небольшие операционные системы, применяемые в случае, если коду приложения необходимо использовать собственную файловую систему контейнера. На рисунке 9.12 показано одно такое развертывание в стиле, который компания Google рекомендует клиентам GKE.
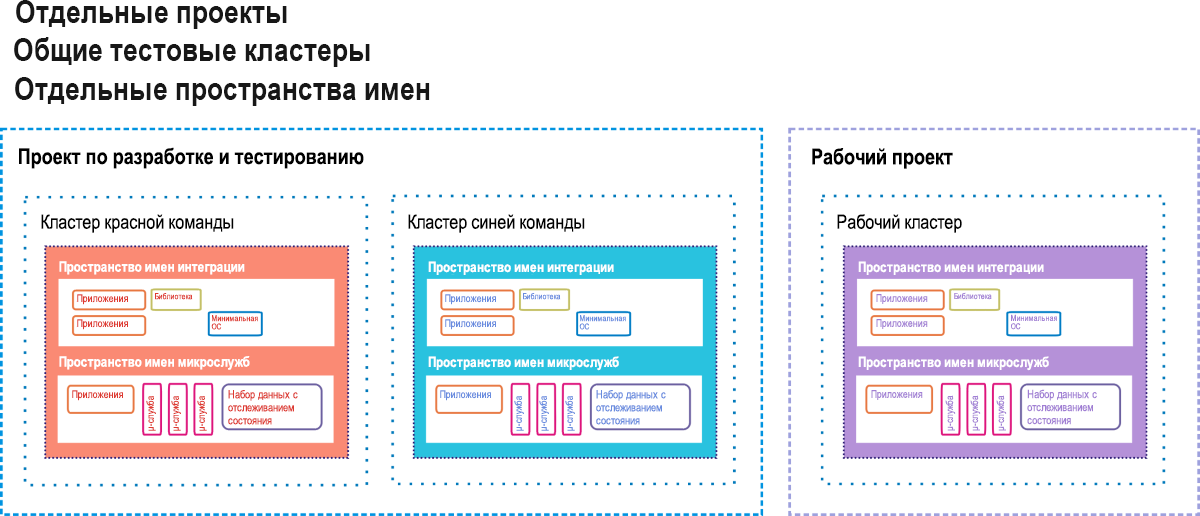
Рис. 12. Горячий резервный параметр в качестве промежуточной среды CI/CD для ядра контейнеров Google.
В GKE проект схож с центром обработки данных в том, что он включает в себя все ресурсы, которые обычно есть в центре обработки данных, только в виртуальной форме. Проекту может быть назначен один или несколько кластеров серверов. Контейнерные компоненты находятся в собственных пространствах имен. Каждое из них состоит из всех доступных для адресации компонентов, к которым разрешен доступ контейнерам-членам, а ко всем компонентам за пределами пространства имен следует обращаться по удаленным IP-адресам. Согласно рекомендациям технических специалистов Google, приложения старого стиля на основе клиент-серверной модели (которые разработчики контейнеров называют "монолитными") могут сосуществовать в одном проекте с контейнерными приложениями при условии, что приложения каждого типа используют собственное пространство имен в целях безопасности.
На представленной схеме развертывания имеются три активных кластера, в каждом из которых два пространства имен: одно для старого программного обеспечения, а другое для нового. Два из этих кластеров выделены для тестирования: один для первоначального тестирования, а другой для окончательного промежуточного размещения. В конвейере CI/CD новые контейнеры кода внедряются в один из тестовых кластеров. В нем контейнер должен пройти ряд автоматических тестов для подтверждения того, что он относительно свободен от ошибок, перед переносом в промежуточную среду. Там новый контейнер ожидает еще один набор тестов. В рабочий кластер, который используется конечными клиентами, можно передавать только код, прошедший все тесты второго уровня в промежуточной среде.
Но и в рабочей среде есть средства безопасности. В сценарии развертывания A/B новый код сосуществует со старым в течение определенного времени. Если новый код не соответствует спецификациям или вносит в систему ошибки, его можно откатить, оставив старый код. Если новый код оказывается исправно работающим, по завершении испытательного срока старый код удаляется.
Этот организованный, частично автоматизированный процесс позволяет избежать внесения в информационные системы ошибок, чреватых сбоями. Однако сама по себе такая конфигурация не является устойчивой к авариям, если только сам рабочий кластер не реплицируется в режиме горячей замены. Безусловно, такая схема репликации потребляет много облачных ресурсов. Тем не менее затраты на нее могут оказаться гораздо ниже, чем те, которые организация понесет в случае отсутствия защиты от отказа системы.
Ссылки
Sterbenz, Джеймс P.G., et al. "ResiliNets: многоуровневая отказоустойчивая и выживаемая сетевая инициатива". https://resilinets.org/main_page.html
Patterson, David, et al. "Recovery Oriented Computing: Motivation, Definition, Principles, and Examples." Microsoft Research, March 2002. https://www.microsoft.com/research/publication/recovery-oriented-computing-motivation-definition-principles-and-examples/.
ISO. "Security and resilience — Business continuity management systems — Requirements" (Безопасность и устойчивость — системы управления непрерывностью бизнес-процессов — требования) https://dri.ca/docs/ISO_DIS_22301_(E).pdf.