Службы аварийного восстановления
Восстановление резервных копий данных по очевидным причинам является стандартной функцией служб резервного копирования. Однако аварии не ограничиваются потерей данных. Простой, делающий недоступными серверы организации, будь то физические или виртуальные, локальные или облачные, негативно, а иногда даже катастрофически, сказывается на работе организации. Целью службы аварийного восстановления является предоставление резервной копии не только данных и отдельных ресурсов, но систем в целом, чтобы при их отключении можно было возобновить обслуживание, перенаправив трафик в реплики, которые находятся в состоянии готовности к принятию нагрузки.
Именно в возможностях аварийного восстановления заключается истинное назначение общедоступного облака. Это не просто огромный ленточный накопитель. Так как облачные ресурсы являются виртуальными, реплики можно моментально подключать взамен ресурсов, которые внезапно стали недоступны. Более того, реплики и исходные системы могут размещаться в разных регионах мира на случай масштабных сбоев. Сравните это с затратами на поддержание физических реплик информационных систем в географически удаленных расположениях, и преимущества облака в плане обеспечения непрерывности работы таких систем станут очевидными.
Ведущие поставщики облачных служб предлагают решения типа "аварийное восстановление как услуга" (DRaaS), но их необходимо тщательно планировать и настраивать, чтобы удовлетворить потребности клиентов в отношении отработки отказа. Поэтому мы начнем с рассмотрения целевых показателей и метрик, которые должны учитываться при таком планировании.
Целевые показатели и метрики
Во время аварии организация и ее клиенты могут утратить доступ сразу к нескольким типам цифровых ресурсов, наиболее важными из которых являются следующие:
базы данных и хранилища данных, в которых, помимо записи важных сведений о клиентах, товарах и услугах, отражается активное состояние бизнес-транзакций и процессов в масштабе всей организации;
массовые данные, которые включают в себя документы, мультимедийные файлы и другие сохраненные записи, создаваемые в результате работы пользователей с приложениями;
взаимодействие и связь с людьми и бизнес-службами — эти процессы составляют суть любой бизнес-деятельности;
приложения, которые являются "витриной" организации для клиентов, а также для внутренних заинтересованных лиц.
Хотя для клиентов аварийное восстановление представляется как единая служба, процесс восстановления для каждого из этих типов ресурсов особый. В эпоху клиент-серверной модели многие организации осуществляли повседневную деятельность на персональных компьютерах. Если компьютер выходил из строя, но в его локальном хранилище имелся резервный образ, теоретически его можно было восстановить на новом компьютере и продолжить работу. С появлением локальных сетей, в которых компьютеры соединялись кабелями Ethernet, стало возможным восстанавливать любой компьютер в сети из резервного образа, а затем возобновлять работу сети.
С облаком ситуация иная. Даже виртуальная машина, которая выступает в качестве сервера для приложений организации, не инкапсулирует в себе все свои рабочие операции и данные. Службы резервного копирования обеспечивают "страховочную сеть" для массовых данных и в некоторой степени для транзакционных данных и баз данных. Однако каждая из этих сущностей является отдельным компонентом, поэтому для возобновления бизнес-функций после аварии требуется восстановление работоспособности большинства, если не всех этих компонентов из безопасного и надежного расположения.
Таким образом, чтобы организация могла снова заработать в полном объеме, необходима координация между всеми процедурами, выполняемыми в процессе аварийного восстановления. Более того, сам факт аварии делает бизнес-операции в этот период особенно важными. Происшествие, которое смогло вывести из строя критически важную инфраструктуру, вероятно, повлияло и на другие функциональные аспекты компании — складское хранение, транспортировку, производство и доставку. Скорее всего, нельзя будет просто продолжить бизнес-операции из того состояния, которое существовало до аварии.
Эти процедуры объединяет в одно целое наличие стандартных, четко определенных целей уровня обслуживания. В службах аварийного восстановления от AWS и Azure, а также в сторонних службах на основе Google Cloud приняты следующие цели:
Целевая точка восстановления (RPO) — минимальный допустимый объем данных, который должен возвращаться клиентам после восстановления из ресурсов, подлежащих резервному копированию. И наоборот, эту величину можно считать максимально допустимой потерей данных, выраженной в виде процентного значения, вычтенного из 100.
Целевое время восстановления (RTO) — это максимальная допустимая продолжительность процесса восстановления, которую также можно рассматривать как меру приемлемого простоя для организации.
Период хранения — это максимально допустимая длительность хранения резервного набора данных, по истечении которой он должен обновляться и заменяться.
Показатели RTO и RPO уравновешивают друг друга. Клиент может выбрать более длительное время восстановления для получения более высокой точки восстановления. Если время восстановления представляет проблему из-за доступной пропускной способности или риска простоя, то клиенту, возможно, не удастся достичь высокого значения RPO.
Опытный консультант по рискам или непрерывности бизнес-процессов, скорее всего, будет настаивать на использовании этих трех переменных при составлении политики аварийного восстановления. В большинстве отчетов по анализу последствий для деятельности показатели RTO и RPO находятся на первом плане. Они являются критически важными при оценке потенциальных убытков вследствие аварий. Некоторые консультанты используют сводную переменную, которая называется целью уровня обслуживания (SLO), хотя единой формулы для ее вычисления еще не выведено. Когда у поставщика облачных решений есть возможность указывать уровни обслуживания в терминах, признаваемых и одобряемых консультантами по рискам, взаимодействие двух сторон упрощается, что часто влияет на окончательный выбор организацией поставщика услуг аварийного восстановления.
Методологии и процедуры
На предыдущем уроке была рассмотрена самая базовая форма восстановления информационной системы, предполагающая резервное копирование соответствующих файлов, томов хранилища и образов виртуальных машин. Хотя такой вариант аварийного восстановления по-прежнему предлагается, на практике он применяется во все меньшем числе организаций, в основном потому, что он не позволяет обеспечивать надлежащие показатели RTO.
Профессиональные службы аварийного восстановления поддерживают различные методологии развертывания и управления, некоторые из которых предполагают проведение обслуживания до аварии. Ниже приводится сводка этих методологий. Все они основаны на разновидностях способов резервного копирования, рассмотренных на предыдущем уроке, и одинаково применимы ко всем поставщикам услуг. Клиент, желающий реализовать один из этих режимов восстановления, должен выбрать наиболее подходящие для него типы репликации, географического размещения и хранения.
Режим запала
При такой методологии (рис. 5) выделяется пространство для полного резервного центра обработки данных. В отказоустойчивом кластере поддерживаются некоторые базовые службы и приложения (вместе с необходимыми им данными), которые можно легко запустить, как только возникнет авария, причем часто это происходит автоматически. В то же время виртуальные серверы развертываются лишь с базовой функциональностью, необходимой для поддержания их в активном состоянии на случай, если они когда-либо потребуются. Такие серверы с ограниченными возможностями могут оснащаться функциями электронной почтой и веб-функциями для взаимодействия с клиентами и пользователями организации. Для реализации режима "горелки" может требоваться непрерывная синхронизация хранилищ непостоянных данных, таких как транзакционные базы данных и тома электронной почты.
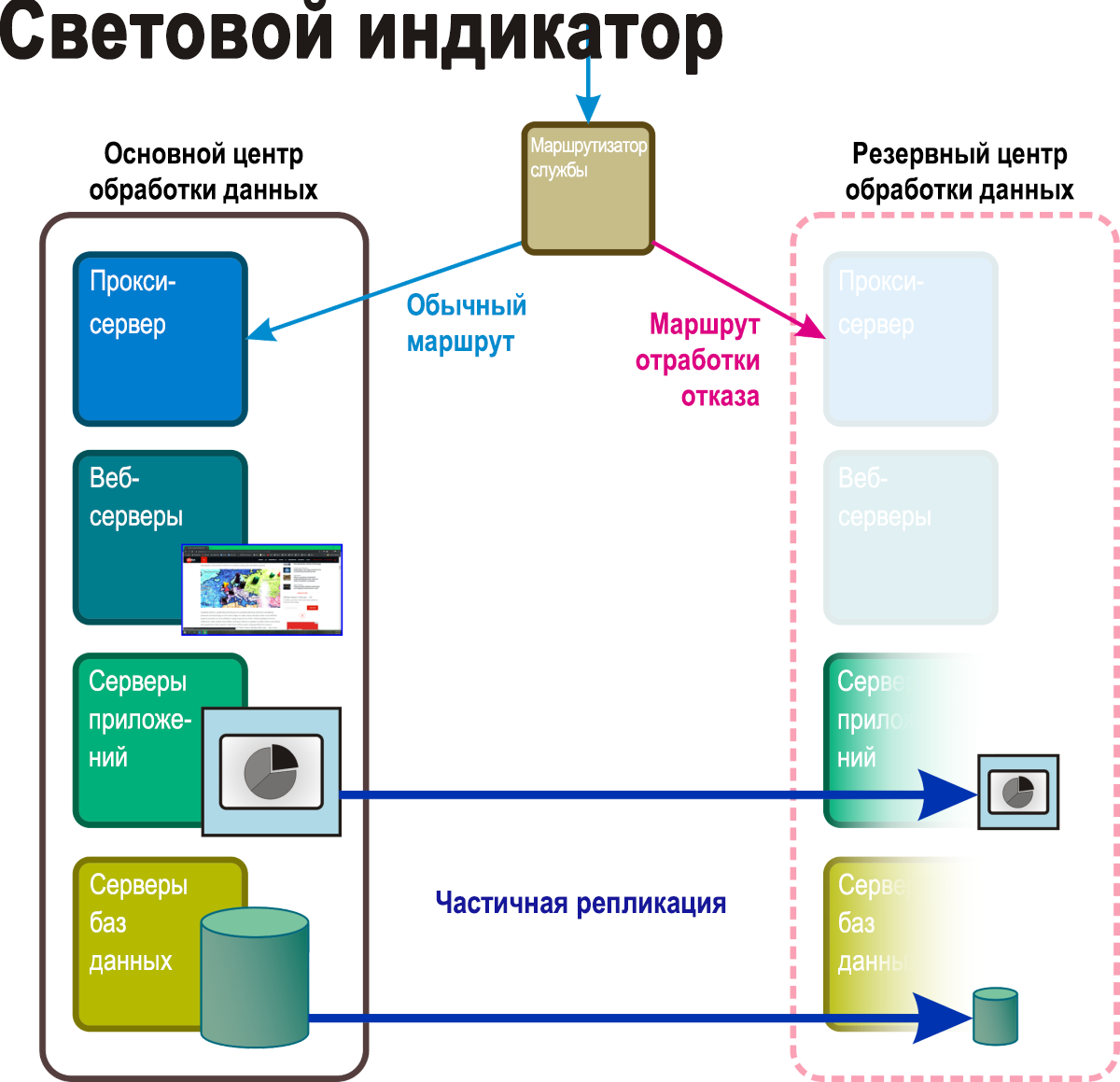
Рис. 5. Активные и пассивные компоненты сценария восстановления Пилотного света.
"Горячее" резервирование
В этом режиме восстановления, показанном на рис. 6, непрерывно работающие реплики всех системных служб и приложений, а также все критически важные бизнес-данные находятся по крайней мере в одном отдельном географическом расположении. Активный маршрутизатор закрывает доступ к этой полной реплике до тех пор, пока в результате аварии не сработает правило, заменяющее адрес активной сети адресом в маршруте обхода.
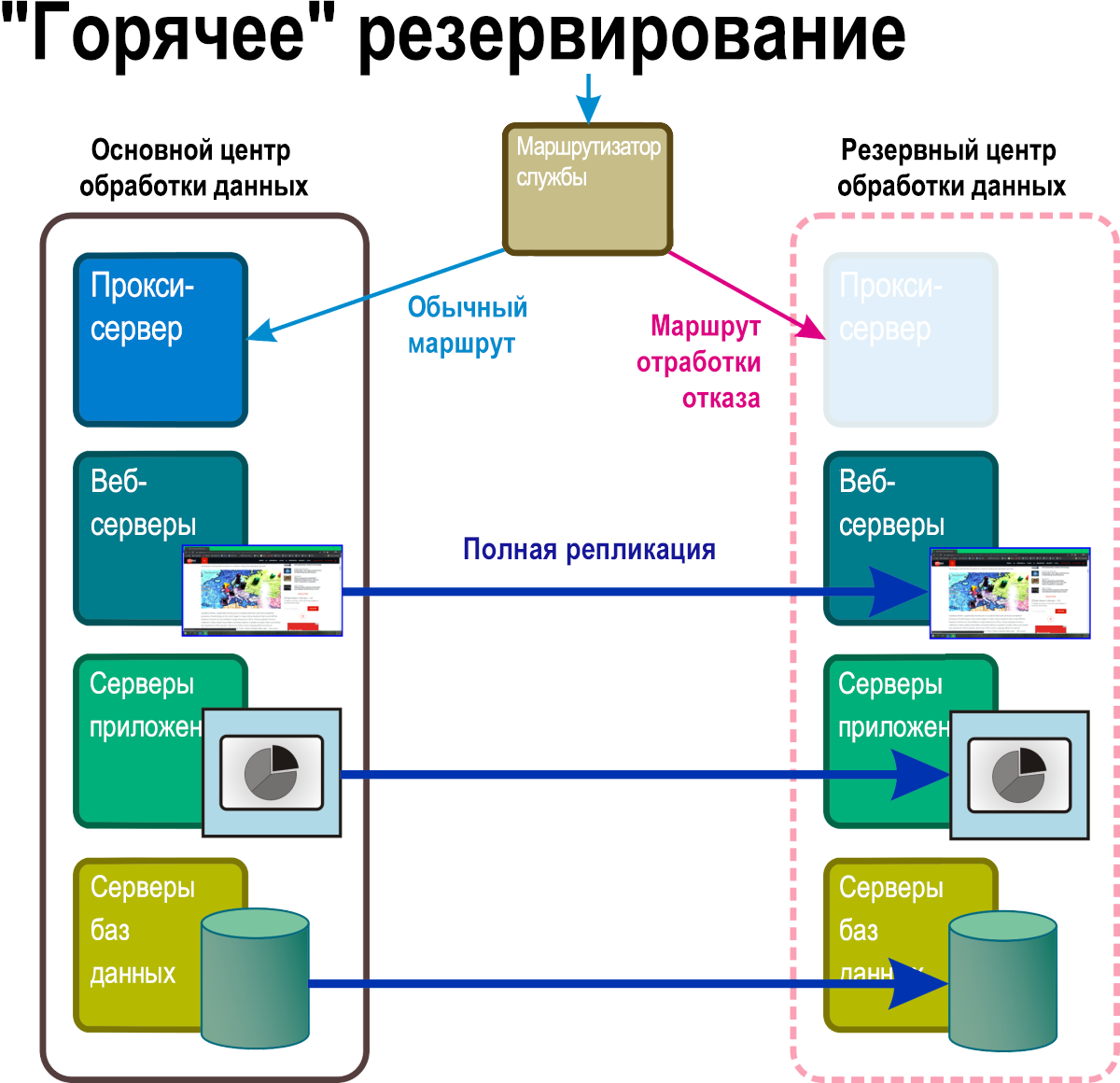
Рис. 6. Сценарий восстановления с теплым резервным режимом с некоторыми компонентами в резервном пространстве имен полностью работает.
Горячая замена
В этом сценарии (рис. 7) постоянно работают по крайней мере две полные реплики всех служб и приложений, данные между которыми синхронизируются полностью и непрерывно. Главный маршрутизатор выступает в качестве общего балансировщика нагрузки, распределяющего запросы ко всем расположениям серверов примерно равномерно. Когда происходит авария, запускается примерно такой же процесс, как и в брандмауэре: адрес затронутой системы удаляется из таблицы маршрутизации.
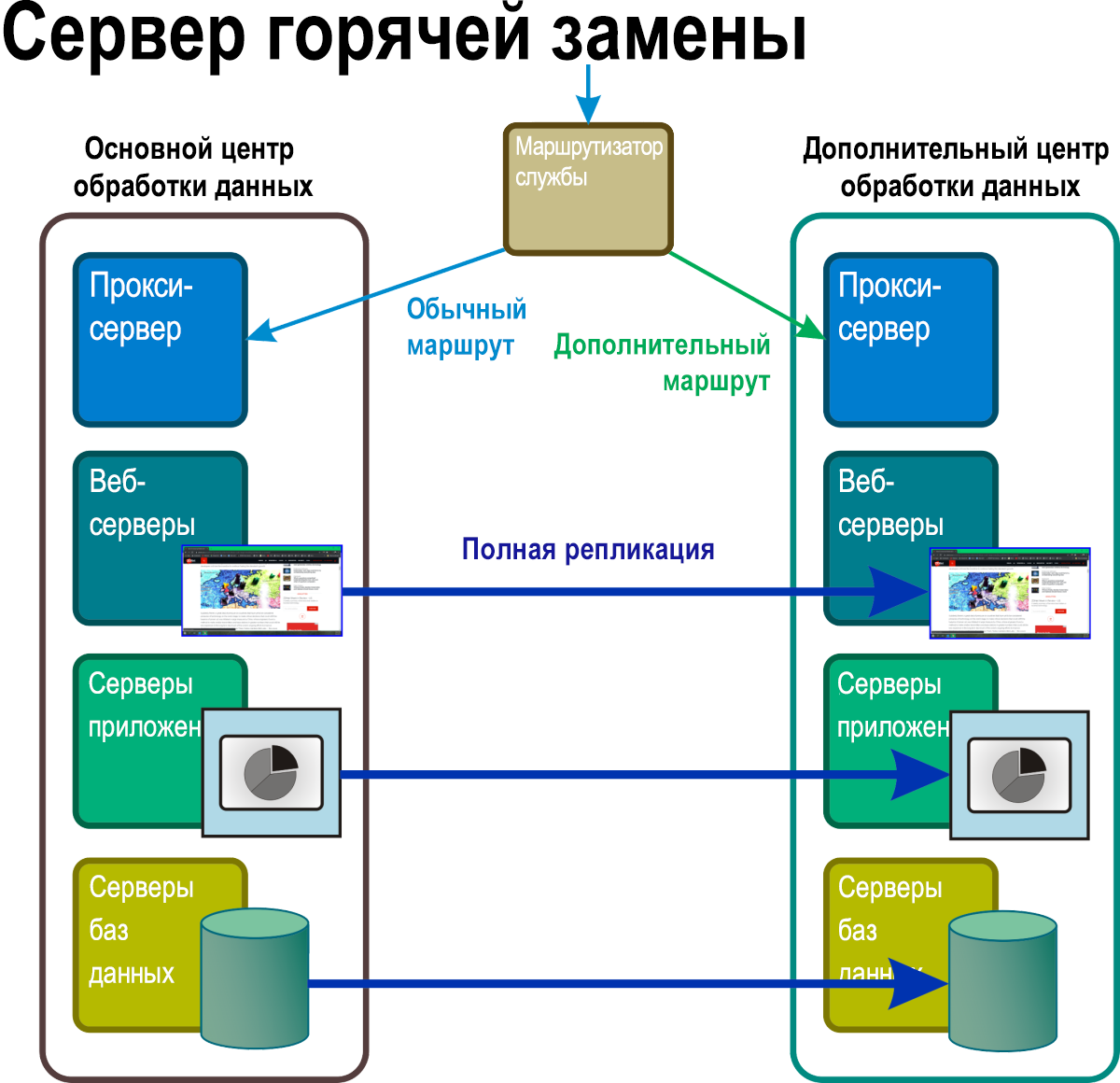
Рис. 7. При горячем резервном режиме все компоненты в пространстве имен, которые обычно были резервом, резервным пространством, являются активными, полностью операционными и обрабатывают реплики первичных данных в режиме реального времени.
Ориентированные на облако приложения
Теоретически организация может выбрать службу аварийного восстановления от одного поставщика в качестве "страховочной сети" для служб, размещенных на платформе другого поставщика. Иными словами, при должных усилиях со стороны ИТ-отдела инфраструктура одного поставщика облачных служб (например, Google) может служить назначением отработки отказа для процедуры "горячего" резервирования, выполняемой из инфраструктуры другого поставщика (например, Azure). Такая конфигурация может потребоваться в целях учета или в случае, если вычислительными ресурсами организации управляют отдельные подразделения в разных частях мира.
Использование контейнерной инфраструктуры как в локальном центре обработки данных, так и в облаке может существенно сказываться на всех перечисленных методологиях аварийного восстановления. Функции так называемого ориентированного на облако приложения, разработанного исключительно для использования на общедоступной облачной платформе или платформе, которая работает аналогичным образом (например, Microsoft Azure Stack), распределяются по нескольким контейнерам реплики, некоторые из которых или все могут работать одновременно. Сделано это в первую очередь не для обеспечения нового сценария аварийного восстановления, а для распределения нагрузки между процессорами.
Еще одной особенностью облачных архитектур является возможность обращения к базам данных, содержимое которых уже реплицируется автоматически, посредством сетевого адреса, схема которого является эксклюзивной для приложения. (Иными словами, хотя он использует интернет-протокол, его адрес не является расположением в более широком общедоступном Интернете.) Таким образом, во время аварии некоторые узлы, подключенные к базе данных, могут быть отключены, многие будут сохраняться, а другие — на месте недоступных узлов. Это пока еще нельзя назвать встроенным аварийным восстановлением, хотя, безусловно, можно описать как устойчивость к авариям.
Аварийное восстановление как услуга (DRaaS)
Для поставщика общедоступных облачных служб аварийное восстановление — это возможность для применения его базовых служб резервного копирования и передачи данных. Каждый из ведущих поставщиков облачных решений реализует особую стратегию по упрощению аварийного восстановления на основе своих служб резервного копирования.
AWS CloudEndure
Под миграцией служб понимается перемещение виртуальных рабочих нагрузок из частной локальной инфраструктуры в общедоступную облачную. Это перемещение необходимо для достижения целевых показателей отработки отказа и восстановления некоторыми службами аварийного восстановления, которые работают в общедоступном облаке, в течение нескольких минут после аварии.
В январе 2019 года компания Amazon приобрела службу миграции частных служб CloudEndure, которая уже использовала AWS в качестве поставщика инфраструктуры. После этого служба CloudEndure была интегрирована в основную линейку служб компании для предоставления бесплатных возможностей миграции служб клиентам Amazon. Теперь в AWS реализован механизм миграции служб для быстрого обеспечения "горячего" резервирования или "горячей" замены. В AWS клиенты не платят за процесс миграции, однако взимается плата за избыточные ресурсы, подготавливаемые для каждого сценария аварийного восстановления. Тем не менее отсутствие дополнительной оплаты сразу выделяет CloudEndure на фоне множества сторонних служб аварийного восстановления.
Azure Site Recovery
Служба аварийного восстановления Майкрософт Azure Site Recovery является управляемым развертыванием метода восстановления "горячим" резервированием для сред на основе виртуальных машин и для физических (локальных) серверов с ОС Linux или Windows. Виртуальные машины активно реплицируются в дополнительный регион (рис. 9.8), отработку отказа в который можно инициировать простым нажатием кнопки. С клиентов взимается ежемесячная плата (в настоящее время 25 долларов) за каждый сервер или виртуальную машину, защищаемую с помощью Azure Site Recovery.
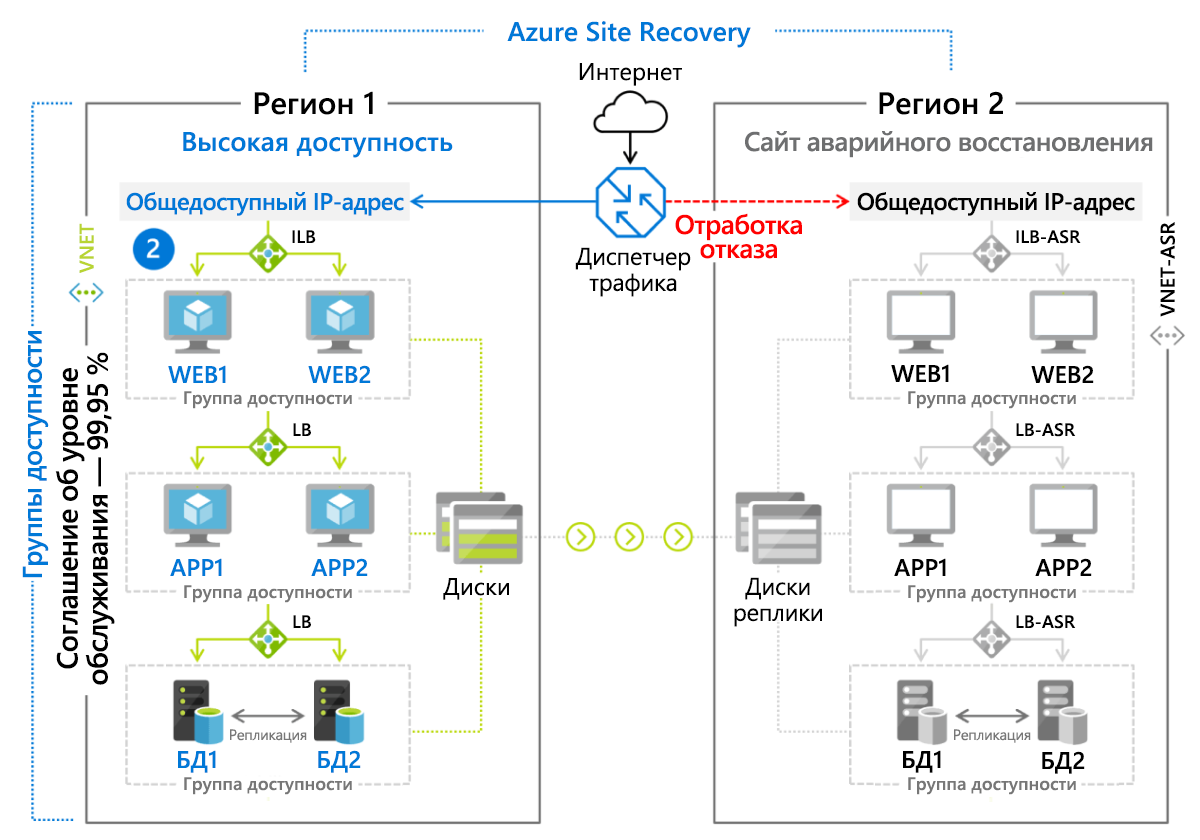
Рис. 8. Сценарий отработки отказа, реализованный с помощью Azure Site Recovery.
Аварийное восстановление в Google Cloud
Как и в случае с резервным копированием, компания Google не предлагает специальную службу для аварийного восстановления. Вместо этого она предоставляет необходимые средства и ресурсы для хранения и передачи данных, а также дает пользователям рекомендации по их оптимальному использованию для различных сценариев аварийного восстановления.
Так как Google предлагает варианты хранилища Coldline и делает на них скидку, платформа GCP применима к широкому спектру сценариев. Coldline является привлекательным вариантом для организаций, которые хранят большой объем массовых данных. Использовать магнитные диски для мультимедийных файлов, средний размер которых достигает десятки гигабайт, становится нецелесообразно. Запоминающие устройства, подключенные к сети (NAS), обеспечивают необходимый уровень доступности и управляемости для организаций, создающих мультимедийные материалы, но только на локальном уровне. Они обладают внутренней избыточностью, но не являются устойчивыми к авариям. А сценарии аварийного восстановления, представленные на трех схемах выше, будут нецелесообразны (или, возможно, даже недопустимо дорогими) для подобных клиентов. Coldline представляет собой по крайней мере одно реальное средство для обеспечения номинального уровня гарантии непрерывности бизнес-процессов в таком сценарии.