Сбои и отказоустойчивость
В повседневной речи мы не придерживаемся строгой терминологии, когда говорим о причинах сбоев систем. Ошибка, неполадка, дефект — эти термины часто используются как синонимы. Однако специалисты центра обработки данных не должны путать эти слова и использовать одно вместо другого. Ниже приведено точное определение каждого из этих терминов в контексте отказоустойчивости.
Ошибка в программе — это изъян в системе, из-за которого ее поведение постоянно отличается от требуемого или ожидаемого. Однако такое поведение нельзя назвать сбоем, ведь система работает именно так, как была спроектирована, хотя должна работать иначе. Ключевое слово здесь — постоянно. Ошибочное поведение можно воспроизвести во всех экземплярах системы. Отладка — это процесс перепроектирования системы с целью устранить ошибки.
Сбой — это изъян в системе, из-за которого система работает не так, как заложено в программе, или перестает работать совсем. В этом случае в проекте системы может не быть изъянов, но одна из ее реализаций или один из ее экземпляров может работать неправильно. Сбой не может быть гарантированно воспроизведен в другом экземпляре системы. Процесс устранения сбоя называется исправлением. Сбой системы может проявляться одним из трех способов:
Постоянный сбой — это нарушение работы системы, причину которого невозможно устранить без полной замены ответственного за сбой компонента.
Временный сбой — это временное и обычно не повторяющееся нарушение работы системы, причину которого можно исправить на месте или которое может пропасть само по себе.
Периодический сбой — это временное и обычно повторяющееся нарушение работы системы, которое часто вызывается снижением работоспособности компонента или ошибками при его проектировании и которое может привести к постоянному сбою, если его не устранить.
Отказ — это полное прекращение работы всей системы или ее части, часто вызываемое неустраненным сбоем. В этом случае сбой является причиной, а отказ — результатом. Отказоустойчивая система — это такая система, которая работает правильно или в соответствии с соглашением об уровне обслуживания в неблагоприятных обстоятельствах и поэтому не подвержена отказам в случае сбоев.
Дефект — это изъян при производстве аппаратного компонента или создании экземпляра программного компонента, который приводит к сбою в работе и, скорее всего, к отказу системы, содержащей этот компонент. Такой изъян можно устранить только путем замены.
Ошибка — это исход операции, которая приводит к нежелательному или неверному результату. В вычислительном устройстве ошибка может быть признаком изъяна при проектировании или сбоя при реализации, а также указывать на приближающийся отказ.
ИТ-специалист, администратор или оператор, проводящий обслуживание отказоустойчивой системы, должен разбираться в этих понятиях и понимать различия между ними. Платформа облачных вычислений является отказоустойчивой системой по определению. Она проектируется и разрабатывается с учетом возможных сбоев, и в ней предусмотрены механизмы по предотвращению отказа. С точки зрения инженера, сам термин "облако" как раз и означает устойчивость. Когда инженеры телефонной связи начали использовать фигуру в виде облака на своих схемах, она представляла компонент сети, который не требовалось принимать во внимание — он был достаточно надежен, так что его можно было не указывать на схеме и заместить облаком.
Когда информационная система, например информационная сеть предприятия, обращается к платформе общедоступного облака, эта платформа должна вести себя как отказоустойчивая система. Однако она не может сделать взаимодействующую с ней систему более отказоустойчивой, чем она уже есть. Отказоустойчивость не наделяет неуязвимостью и не гарантирует отсутствие ошибок в системе. Иначе говоря, отказоустойчивая система не обязательно должна быть безупречной. Отказоустойчивость — это, скорее, способность системы обеспечивать ожидаемые уровни обслуживания при наличии ошибок.
Любая информационная система предназначена для автоматизации задач, связанных с использованием информации. Саму отказоустойчивость можно автоматизировать лишь до некоторой степени. Так, отказоустойчивость была одним из основополагающих принципов при разработке сети ARPANET, прародителя Интернета. В случае аварии цифровые коммуникации могли перенаправляться в обход системы, адрес которой стал недоступен. Однако Интернет, как и любая другая информационная система, не является самоподдерживающимся механизмом.
Для достижения целевых показателей обслуживания любая информационная система постоянно требует человеческого вмешательства. Однако чем лучше спроектирована система, тем быстрее и проще ее обслуживать.
Отказоустойчивость облачных платформ
Ранние платформы облачных служб были, мягко говоря, не такими отказоустойчивыми, как планировали их архитекторы. Так, возможность избыточной подготовки ресурсов для служб, например нескольких экземпляров базы данных или дублирующихся кэшей памяти, оказалась неэффективной в условиях недостаточно надежного мониторинга, из-за чего в аварийных ситуациях резервные копии или реплики иногда становились недоступны. Кроме того, избыточная подготовка противоречит одному из основных принципов облачной бизнес-модели: оплате только за необходимые ресурсы. Организации не удастся сократить эксплуатационные расходы, если ей придется арендовать дополнительные экземпляры виртуальных машин на случай выхода основной виртуальной машины из строя.
Отказоустойчивая система обеспечивает избыточность, но делает это динамично и целесообразно, настраивая пределы доступных ресурсов с учетом потребностей на текущий момент времени. В эпоху клиент-серверной модели периодически выполнялось резервное копирование серверов целиком, включая локальное хранилище данных и подключенные сетевые тома. Девиз "Архивировать все" стал принципом корпоративной культуры. Когда общедоступные облачные службы стали доступными по цене и удобными в использовании, организации начали использовать их для резервного копирования всех имеющихся данных. Со временем, однако, они поняли, что облако позволяет отказаться от сложившихся методов работы и достичь большего. Отказоустойчивость может быть заложена в сами облачные платформы, так что ее не нужно реализовывать при развертывании системы.
Реактивные методы
Как бы грамотно ни была продумана система, ее отказоустойчивость в первую очередь зависит от того, насколько хорошо она и управляющие ею пользователи реагируют на первые признаки сбоя. Ниже приведены некоторые из реактивных методов, которые организации используют для устранения возникших ошибок.
Миграция заданий без вытеснения
Метод миграции заданий без вытеснения гарантирует, что узел рабочей нагрузки, который, по всей видимости, испытал сбой, не будет снова назначен для размещения той же рабочей нагрузки. Это позволяет защитить "задание", хотя и может затруднить сбор повторных экземпляров ошибки, которые было бы проще отслеживать при детальной регистрации пути.
Репликация задачи
Во многих распределенных информационных системах одновременно выполняется несколько экземпляров задачи (в случае с оркестрацией Kubernetes они называются репликами). Системы управления на основе политик могут предполагать репликацию задачи, если возникает очевидный или вероятный сбой системы.
Контрольные точки и точки восстановления
В простейшей форме контрольные точки и точки восстановления предполагают создание моментальных снимков системы в разные моменты времени и позволяют администраторам выполнять "откат" к указанному моменту времени, если требуется восстановление. Эта стратегия усложняется в случае с транзакциями, например, когда приложение выполняет два или несколько действий в базе данных, которые должны завершаться успешно или неудачно вместе. Типичным примером может служить приложение, которое списывает деньги с одного счета и зачисляет их на другой. Эти операции должны завершаться успешно или неудачно вместе во избежание ошибочного увеличения или уменьшения средств на счете.
В системе восстановления транзакций по контрольным точкам извлекаемые записи транзакций хранятся в памяти в дереве процессов. На определенных этапах транзакции используемые ею ресурсы памяти реплицируются и сохраняются в пуле восстановления. Если анализ журнала выявляет возможный сбой программного обеспечения, дерево процессов разветвляется, состояние транзакции откатывается к более ранней точке и производится попытка выполнить новую транзакцию. Если новая транзакция выполняется успешнее, чем ошибочная (например, если тест на исправление ошибки оказывается пройденным), старая ветвь процесса урезается и выполнение продолжается по новой ветви с этой точки. У инженеров это называется переключением контекста1.
Более сложная версия этой методики предусматривает реализацию системы трассировки в дереве процессов, которая при повторном возникновении ошибки может обработать процесс в обратном направлении и отследить причину ошибки. После этого можно выбрать подходящую точку восстановления или "контрольную точку" до возникновения ошибки[2].
Еще одна реализация под названием SGuard была создана исследователями из Вашингтонского университета и Microsoft Research для отказоустойчивой обработки больших потоков данных. SGuard использует распределенную файловую систему Hadoop (HDFS) для планирования одновременной записи нескольких моментальных снимков потоков данных во время обработки. Эти моментальные снимки по мере необходимости делятся на меньшие части, что, в свою очередь, приводит к разделению обработки потоков на меньшие сегменты. Контрольные точки хранятся в HDFS. Преимущество такой системы заключается в регистрации потоковых транзакций данных, а также наличии нескольких актуальных реплик потоковых данных в распределенных расположениях. Хотя для реализации метода SGuard требуется значительный объем подготовительной работы, он все же считается реактивным методом обеспечения отказоустойчивости, так как основная часть работы выполняется в ответ на событие сбоя3.
Проактивные методы
Проактивный метод обеспечения отказоустойчивости выполняется еще до того, как будет обнаружен какой-либо сбой. Он имеет упреждающее действие, которое в современных реализациях все больше строится на строгих правилах, а не на догадках. Ниже приведены некоторые методы, которые используются современными облачными платформами.
Репликация ресурсов
Эффективная стратегия репликации ресурсов не может строиться исключительно на принципе "резервного копирования всех имеющихся данных". Системный аналитик должен иметь возможность определить, какие ресурсы в системе (например, ядро СУБД, веб-сервер или маршрутизатор виртуальной сети) могут самостоятельно восстановиться после сбоя, а восстановление каких невозможно. Интеллектуальная репликация может быть первой линией защиты в отказоустойчивой системе.
Существует четыре общие стратегии, используемые для реализации репликации ресурсов. Все они показаны на рисунке 1.
Активная репликация — все реплицированные ресурсы активны одновременно, причем для каждого из них независимо поддерживается собственное состояние — собственные локальные данные, которые делают его работоспособным. Эта особенность означает, что запрос клиента принимают сразу все реплицированные ресурсы одного класса и все они обрабатывают ответ. Однако клиенту доставляется ответ только от ресурса, назначенного основным в классе. В случае сбоя одного из ресурсов, в том числе основного узла, другой узел назначается его последователем. Для такой системы требуется, чтобы обработка между основным узлом и репликами была детерминированной, то есть происходила в определенной последовательности.
Полуактивная репликация похожа на активную. Отличие в том, что узлы-реплики могут обрабатывать запросы не детерминированным образом (не согласованно с основным узлом). Выходные данные дополнительных ресурсов подавляются и сохраняются для переключения на них в случае сбоя основного ресурса.
Пассивная репликация — только основной узел ресурса обрабатывает запросы, а остальные (реплики) поддерживаются в актуальном состоянии и ожидают назначения основным узлом в случае сбоя. Основной ресурс, к которому обращается клиент, передает все изменения состояния во все реплики. Все исходные ресурсы и реплики, относящиеся к одному классу, считаются участниками группы. Участник может исключаться из группы, если есть подозрение на его сбой (сбоя может фактически не быть). Во время сбоя возможны задержки или снижение качества обслуживания (QoS), хотя в обычных условиях пассивная репликация требует меньше ресурсов.
Полупассивная репликации — эта методология работает по той же схеме, что и пассивная репликация, за исключением отсутствия постоянного основного ресурса. Вместо этого каждому ресурсу по очереди назначается роль координатора, причем очередность определяется моделью передачи токена, которая называется парадигмой смены координатора.
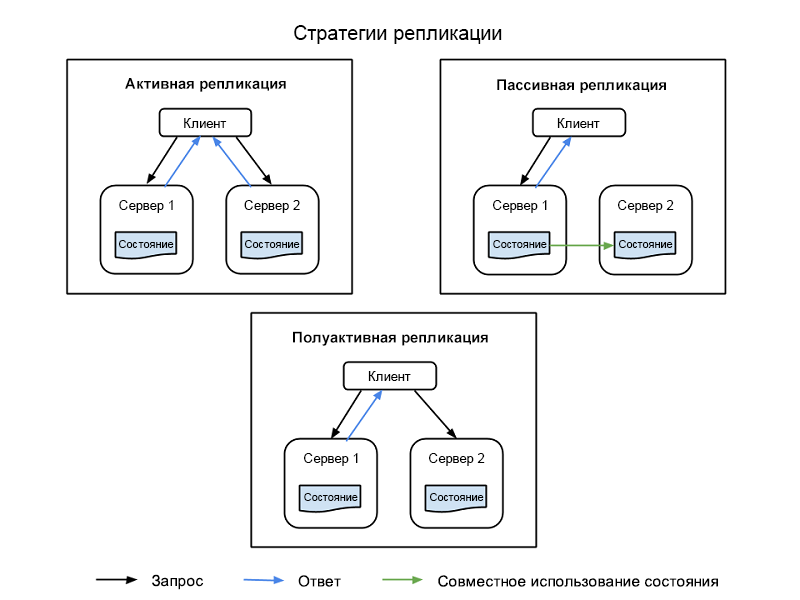
Рис. 1. Клиентские узлы, первичные узлы и реплики узлов в реплицированной информационной системе.
Балансировка нагрузки
Подсистемы балансировки нагрузки распределяют запросы от различных клиентов между несколькими серверами, на которых выполняется одно приложение, таким образом уменьшая нагрузку на отдельные компоненты системы. Положительный побочный эффект от использования подсистем балансировки нагрузки заключается в том, что некоторые из них автоматически перенаправляют трафик от серверов, переставших не отвечать на запросы, таким образом снижая вероятность крупномасштабного сбоя. В более современных системах, предполагающих распределение программного обеспечения по облачной платформе (например, посредством микрослужб), рабочие нагрузки делятся на отдельные функции, которые, в свою очередь, распределяются между процессорами на стороне сервера по возможности равномерно, чтобы процессоры загружались умеренно.
Виртуализация (важнейшая составляющая облачных вычислений) обеспечивает более равномерное распределение рабочих нагрузок между процессорами благодаря возможности их переноса на физические процессоры, которые могут обрабатывать их наиболее эффективно. Контейнеризация делает такой подход еще эффективнее благодаря отделению виртуализированных рабочих нагрузок от виртуальных процессоров. Таким образом, рабочая нагрузка может размещаться в узле сервера, операционная система которого лучше всего подходит для нее. Это важнейший принцип оркестрации рабочих нагрузок, что можно видеть на примере таких систем, как Kubernetes.
Обновление и перенастройка
В информационных системах, в которых экземпляры программного обеспечения работают в течение долгого времени, это ПО может требоваться перезагружать. Хотя в некоторых более ранних облачных платформах делались попытки реализовать периодическую проверку уровней обслуживания, предоставляемых экземплярами ПО, с целью определить момент, когда требуется перезагрузка, в последующем разработчики вернулись к простому способу периодической перезагрузки по расписанию. Во время перезагрузки файлы конфигурации запуска могут автоматически корректироваться с учетом изменившегося состояния системы или для предотвращения потенциального сбоя после запуска.
Миграция с вытеснением
Когда виртуализация начала повсеместно внедряться в центрах обработки данных, миграция с вытеснением была предложена в качестве способа для выравнивания нагрузки на серверное оборудование путем смены рабочих нагрузок, назначенных процессорам, например циклически. Облачные платформы достаточно часто перераспределяют рабочие нагрузки в виртуальной инфраструктуре, так что этот метод практически утратил свое значение. Однако данная тема недавно снова стала активно обсуждаться в связи с основанными на искусственном интеллекте методами прогнозирования нагрузки в разнообразных информационных системах. Такие системы могут вырабатывать собственные правила для переноса более важных рабочих нагрузок с узлов серверов с высокой прогнозируемой вероятностью сбоя.
Самостоятельное восстановление
В широко распределенной информационной системе, такой как сеть доставки содержимого (CDN) или платформа социальной сети, функции отдельных серверов могут распределяться по нескольким адресам, обычно в разных расположениях или центрах обработки данных. Самовосстанавливающаяся сеть регулярно опрашивает различные подключения (так же как платформа управления производительностью) для проверки потока трафика и реагирования на запросы. Если обнаружено отклонение производительности, маршрутизаторы могут перестать направлять запросы в подозрительные компоненты, что в конечном итоге приведет к прекращению передачи трафика через них. После этого компонент может быть протестирован на наличие признаков ошибки. Затем компонент может быть перезапущен для проверки того, изменилось ли его поведение. В активное состояние он возвращается только в том случае, если в результате диагностики вероятность сбоя не выявлена. Такое автоматизированное транзакционное реагирование является современным примером самостоятельного восстановления в высокораспределенных центрах обработки данных4.
Планирование процессов на основе обмена
Облачная платформа (которая включает в себя общедоступные облачные службы, но может также включать и локальную инфраструктуру) обладает уникальной способностью предоставлять информацию о своем состоянии. Когда компания Amazon приступила к реализации переработанной модели SaaS в 2009 году, ее технические специалисты разработали концепцию под названием планирование приоритетных экземпляров. В рамках такой системы автоматический прокси-сервер от лица клиента объявляет требования к ресурсам для определенного задания и выполняет широковещательную рассылку запроса, похожего по своей сути на приглашение к участию в торгах. Этот запрос распространяется от узлов серверов по всей облачной платформе. Каждый узел сообщает о своей возможности удовлетворить объявленные требования в плане времени и расхода ресурсов. Узел, предлагающий наименьшие затраты, выигрывает торги и назначается приоритетным экземпляром для задания. Такой способ планирования в настоящее время предлагается в качестве варианта для Amazon Elastic Compute Cloud5.
Ссылки
Ioana, Cristescu. A Record-and-Replay Fault Tolerant System for Multithreading Applications (Отказоустойчивая система для многопоточных приложений на основе записи и воспроизведения). Technical University of Cluj Napoca. http://scholar.harvard.edu/files/cristescu/files/paper.pdf.
Sidiroglou, Stelios, et al.ASSURE: Automatic Software Self-healing Using Rescue Points. Columbia University, 2009.
Kwon Yong-Chul, et al. Fault-tolerant Stream Processing Using a Distributed, Replicated File System. Association for Computing Machinery, 2008. https://db.cs.washington.edu/projects/moirae/moirae-vldb08.pdf.
Yang, Chen. Checkpoint and Restoration of Micro-service in Docker Containers. School of Information Security Engineering, Shanghai Jiao Tong University, China, 2015. https://download.atlantis-press.com/article/25844460.pdf.
Amazon Web Services, Inc. Spot Instance Requests Amazon, 2020. https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/spot-requests.html.