Общие сведения о Анализ текста
Прежде чем изучать возможности анализа текста службы языка ИИ Azure, давайте рассмотрим некоторые общие принципы и распространенные методы, используемые для анализа текста и других задач обработки естественного языка (NLP).
Некоторые из самых ранних методов, используемых для анализа текста с помощью компьютеров, включают статистический анализ текста ( корпус) для вывода какого-то семантического значения. Проще говоря, если вы можете определить наиболее часто используемые слова в данном документе, вы часто можете получить хорошее представление о том, о чем речь идет.
Выделение лексем
Первый шаг в анализе корпуса заключается в том, чтобы разбить его на маркеры. Для простоты можно рассматривать каждое отдельное слово в обучаемом тексте как маркер, хотя на самом деле маркеры можно создавать для частичных слов или сочетаний слов и препинания.
Например, рассмотрим эту фразу из знаменитой президентской речи США: "Мы решили пойти на луну". Фраза может быть разбита на следующие маркеры с числовыми идентификаторами:
- we
- choose
- до
- GO
- мыши
- moon
Обратите внимание, что "to" (номер токена 3) используется дважды в корпусе. Фраза "мы решили пойти на луну" может быть представлена токенами [1,2,3,4,3,5,6].
Примечание.
Мы использовали простой пример, в котором маркеры определяются для каждого отдельного слова в тексте. Однако рассмотрим следующие понятия, которые могут применяться к токенизации в зависимости от конкретной проблемы NLP, которую вы пытаетесь решить:
- Нормализация текста: перед созданием маркеров можно нормализовать текст, удалив знаки препинания и изменив все слова на нижний регистр. Для анализа, который использует исключительно частоту слов, этот подход повышает общую производительность. Однако некоторые семантические значения могут быть потеряны - например, рассмотрим предложение "г-н Бэнкс работал во многих банках". Вы можете захотеть ваш анализ различать человека г-н Бэнкс и банки , в которых он работал. Вы также можете рассмотреть "банки" в качестве отдельного токена для "банков", потому что включение периода предоставляет информацию о том, что слово приходит в конце предложения.
- Остановите удаление слов. Стоп-слова — это слова, которые следует исключить из анализа. Например, "the", "a" или "it" упрощают чтение текста, но добавляют мало семантического значения. Исключив эти слова, решение анализа текста может лучше определить важные слова.
- n-граммы являются многосрочные фразы, такие как "У меня есть" или "он ходил". Одна фраза слова — это юниграмма, двухсловная фраза — двуграмма, три слова — три-грамма и т. д. Учитывая слова как группы, модель машинного обучения может лучше понять текст.
- Стебливание — это метод, в котором алгоритмы применяются к консолидации слов перед подсчетом их, поэтому слова с тем же корнем, как "power", "powered" и "мощный", интерпретируются как один и тот же маркер.
Анализ частоты
После маркеризации слов можно выполнить некоторый анализ, чтобы подсчитать количество вхождения каждого маркера. Наиболее часто используемые слова (кроме стоп-слов , таких как "a", "the" и т. д.), часто могут дать подсказку о главном предмете текстового корпуса. Например, наиболее распространенные слова во всем тексте речи "перейти на луну", которые мы рассмотрели ранее, включают "new", "go", "space" и "луна". Если бы мы были маркеризировать текст как двуграммы (пары слов), наиболее распространенная двуграмма в речи — "луна". Из этой информации мы можем легко предположить, что текст в первую очередь связан с космическим путешествием и переходом на луну.
Совет
Простой анализ частоты, в котором вы просто подсчитываете количество вхождения каждого маркера, может быть эффективным способом анализа одного документа, но при необходимости различать несколько документов в одном корпусе, вам потребуется способ определить, какие маркеры наиболее важны в каждом документе. Частота терминов — обратная частота документа (TF-IDF) — это распространенный способ вычисления оценки на основе частоты отображения слова или термина в одном документе по сравнению со своей более общей частотой во всей коллекции документов. С помощью этого метода предполагается высокая степень релевантности для слов, которые часто появляются в определенном документе, но относительно редко в широком диапазоне других документов.
Машинное обучение для классификации текста
Другой полезный метод анализа текста заключается в использовании алгоритма классификации, например логистической регрессии, для обучения модели машинного обучения, которая классифицирует текст на основе известного набора классификаций. Распространенное применение этого метода заключается в обучении модели, которая классифицирует текст как положительный или отрицательный для выполнения анализа тональности или интеллектуального анализа мнений.
Например, рассмотрим следующие отзывы о ресторане, которые уже помечены как 0 (отрицательные) или 1 (положительные):
- Еда и обслуживание были оба велики: 1
- Действительно ужасный опыт: 0
- Ммм! вкусная еда и веселая вибе: 1
- Медленная служба и нестандартная еда: 0
С достаточной меткой проверки можно обучить модель классификации с помощью маркеризованного текста в качестве признаков и тональности (0 или 1) метки. Модель будет инкапсулировать связь между токенами и тональностью - например, отзывы с маркерами для таких слов, как "большой", "вкусный", или "весело", скорее всего, возвращают тональность 1 (положительный), а отзывы с такими словами, как "ужасный", "медленный" и "нестандартный", скорее всего, возвращают 0 (отрицательные).
Семантические языковые модели
Поскольку состояние искусства для NLP продвинулось, возможность обучения моделей, которые инкапсулируют семантическую связь между маркерами, привели к возникновению мощных языковых моделей. В основе этих моделей лежит кодировка маркеров языка в виде векторов (многозначных массивов чисел), известных как внедрение.
Можно подумать об элементах в векторе внедрения маркера как координаты в многомерном пространстве, чтобы каждый токен занимал определенное "расположение". Чем ближе маркеры друг к другу вдоль определенного измерения, тем более семантически связаны они. Другими словами, связанные слова группируются ближе друг к другу. В качестве простого примера предположим, что внедрение для наших маркеров состоит из векторов с тремя элементами, например:
- 4 ("собака"): [10.3.2]
- 5 ("барк"): [10,2,2]
- 8 ("cat"): [10,3,1]
- 9 ("meow"): [10,2,1]
- 10 ("скейтборд"): [3,3,1]
Мы можем построить расположение маркеров на основе этих векторов в трехмерном пространстве, как показано ниже.
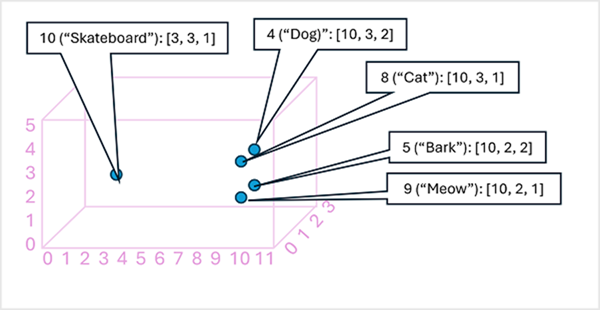
Расположение лексем в векторных представлениях содержит информацию о том, насколько тесно лексемы связаны друг с другом. Например, маркер для "собака" близок к "коту", а также к "лаю". Маркеры для "cat" и "лай" близки к "мяу". Маркер для скейтборда находится дальше от других маркеров.
Языковые модели, используемые в отрасли, основаны на этих принципах, но имеют большую сложность. Например, векторы, используемые обычно, имеют гораздо больше измерений. Существует также несколько способов вычисления соответствующих внедрений для заданного набора маркеров. Различные методы приводят к различным прогнозированиям от моделей обработки естественного языка.
Обобщенное представление большинства современных решений обработки естественного языка показано на следующей схеме. Большой корпус необработанного текста и используется для обучения языковых моделей, которые могут поддерживать множество различных типов задачи обработки естественного языка.
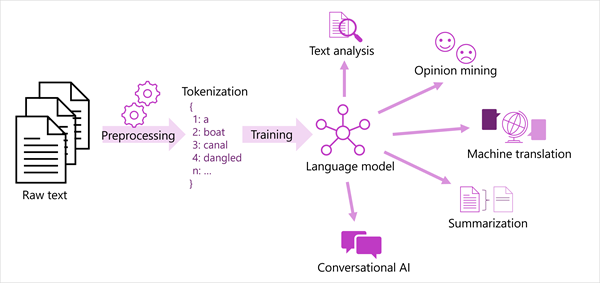
К общим задачам NLP, поддерживаемым языковыми моделями, относятся:
- Анализ текста, например извлечение ключевых терминов или определение именованных сущностей в тексте.
- Анализ тональности и интеллектуальный анализ мнений, чтобы классифицировать текст как положительный или отрицательный.
- Машинный перевод, в котором текст автоматически преобразуется с одного языка на другой.
- Сводка, в которой суммируются основные моменты большого текста.
- Решения искусственного интеллекта для общения, такие как боты или цифровые помощник, в которых языковая модель может интерпретировать входные данные естественного языка и возвращать соответствующий ответ.
Эти возможности и многое другое поддерживаются моделями в службе языка искусственного интеллекта Azure, которую мы рассмотрим далее.