Упражнение. Анализ данных с использованием Seaborn
Одна из замечательных особенностей записных книжек Azure и Python в целом — это наличие тысяч библиотек с открытым кодом, которые можно использовать для выполнения сложных задач без написания большого объема кода. В этом модуле вы будете использовать Seaborn, библиотеку для статистической визуализации, чтобы построить второй из двух наборов данных, который вы загрузили, охватывающий период с 1882 по 2014 год. Seaborn может создать линию регрессии с проекцией, показывающей, где должны размещаться точки данных на основе регрессии, с одним простым вызовом функции.
Поместите курсор в пустую ячейку внизу записной книжки. Измените тип ячейки на Markdown и введите "Выполнить линейную регрессию с Seaborn" как текст.
Добавьте ячейку для кода и вставьте следующий код.
plt.scatter(years, mean) plt.title('scatter plot of mean temp difference vs year') plt.xlabel('years', fontsize=12) plt.ylabel('mean temp difference', fontsize=12) sns.regplot(yearsBase, meanBase) plt.show()Запустите ячейку кода, чтобы создать точечную диаграмму с линией регрессии и визуальным представлением диапазона, в который должны попадать точки данных.
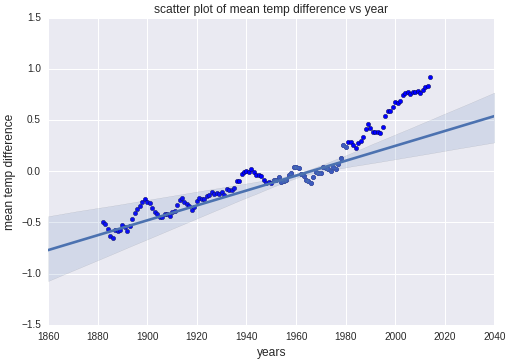
Сравнение фактических и прогнозных значений, созданных с помощью Seaborn
Обратите внимание, что точки данных за первые 100 лет соответствуют прогнозируемым значениям, а примерно с 1980 года — нет. Именно на таких моделях ученые строят предположения об ускорении изменения климата.