Масштабирование с KEDA
Автомасштабирование на основе событий Kubernetes
Автомасштабирование на основе событий Kubernetes (KEDA) — это единый и упрощенный компонент, упрощающий автомасштабирование приложений. Вы можете добавить KEDA в любой кластер Kubernetes и использовать его вместе со стандартными компонентами Kubernetes, такими как горизонтальное автомасштабирование Pod (HPA) или Автомасштабирование кластера, чтобы расширить их функциональные возможности. С помощью KEDA можно использовать определенные приложения, которые вы хотите использовать масштабирование на основе событий и разрешить другим приложениям использовать различные методы масштабирования. KEDA — это гибкий и безопасный вариант для запуска вместе с любым количеством приложений или платформ Kubernetes.
Ключевые возможности и функции
- Создание устойчивых и экономичных приложений с помощью возможностей масштабирования до нуля
- Масштабирование рабочих нагрузок приложений для удовлетворения спроса с помощью масштабировщиков KEDA
- Автомасштабирование приложений с помощью
ScaledObjects - Задания автомасштабирования с помощью
ScaledJobs - Использование безопасности рабочего уровня путем отмены автомасштабирования и проверки подлинности от рабочих нагрузок
- Создание собственного внешнего масштабировщика для использования специализированных конфигураций автомасштабирования
Архитектура
KEDA предоставляет два основных компонента:
- Оператор KEDA: позволяет конечным пользователям масштабировать рабочие нагрузки с нуля до N экземпляров с поддержкой развертываний Kubernetes, заданий, statefulSets или любого ресурса клиента, определяющего
/scaleподресурс. - Сервер метрик: предоставляет внешние метрики для HPA, например сообщений в разделе Kafka или событиях в Центры событий Azure, для управления действиями автомасштабирования. Из-за ограничений вышестоящего потока сервер метрик KEDA должен быть единственным установленным адаптером метрик в кластере.
На следующей схеме показано, как KEDA интегрируется с Kubernetes HPA, внешними источниками событий и сервером API Kubernetes для предоставления функций автомасштабирования:
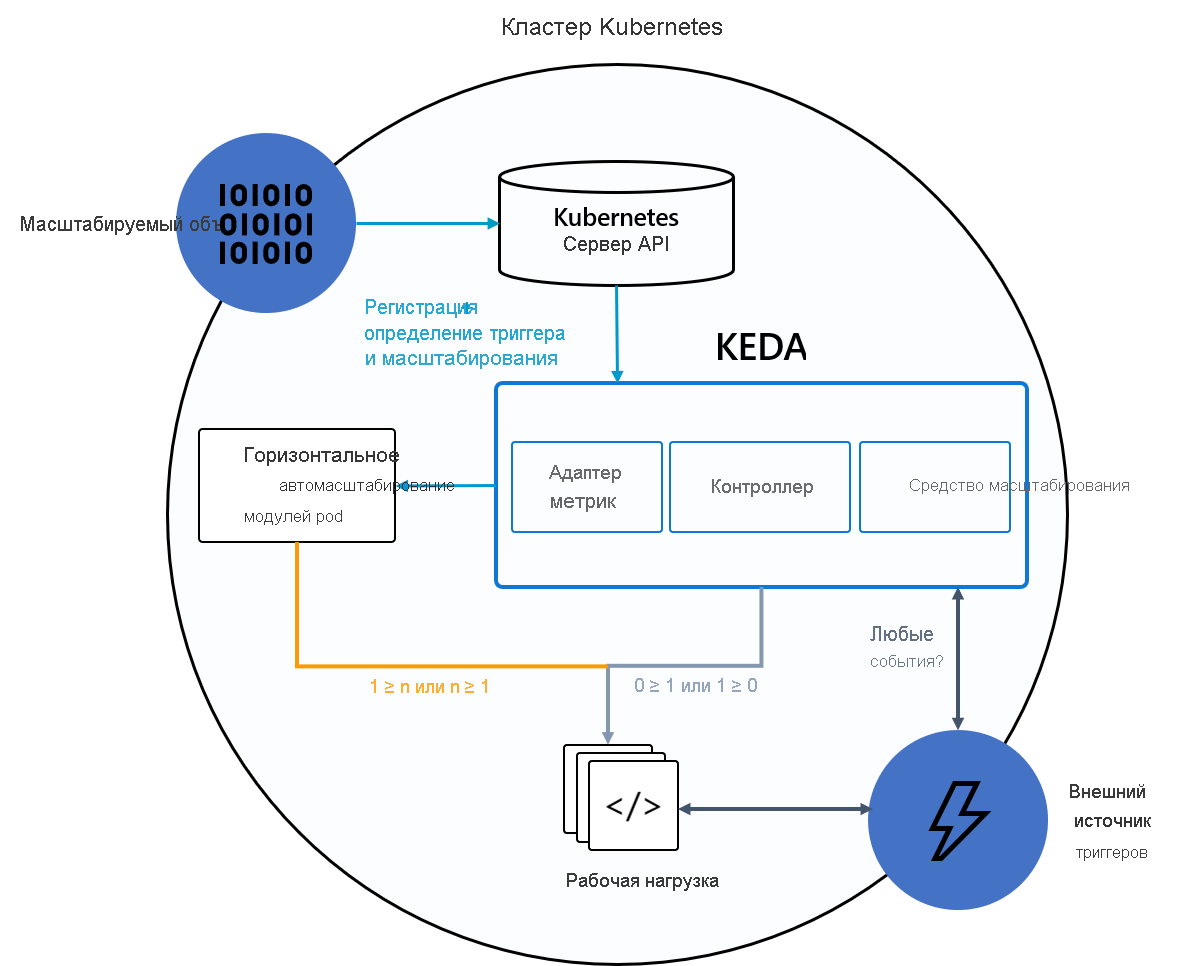
Совет
Дополнительные сведения см. в официальной документации KEDA.
Источники событий и средства масштабирования
Масштабировщики KEDA могут определить, следует ли активировать или деактивировать развертывание, а также передавать пользовательские метрики для определенного источника событий. Развертывания и наборы с отслеживанием состояния — это наиболее распространенный способ масштабирования рабочих нагрузок с помощью KEDA. Вы также можете масштабировать пользовательские ресурсы, реализующие /scale подресурс. Вы можете определить развертывание Kubernetes или StatefulSet, которое требуется масштабировать KEDA на основе триггера масштабирования. KEDA отслеживает эти службы и автоматически масштабирует их на основе событий, происходящих.
За кулисами KEDA отслеживает источник событий и передает данные в Kubernetes и HPA для быстрого масштабирования ресурсов. Каждая реплика ресурса активно извлекает элементы из источника событий. С помощью KEDA и Deployments/StatefulSetsвы можете масштабироваться на основе событий, сохраняя широкие семантики подключения и обработки с помощью источника событий (например, обработку в порядке, повторные попытки, взаимозавершение или контрольную точку).
Спецификация масштабируемого объекта
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: {scaled-object-name}
spec:
scaleTargetRef:
apiVersion: {api-version-of-target-resource} # Optional. Default: apps/v1
kind: {kind-of-target-resource} # Optional. Default: Deployment
name: {name-of-target-resource} # Mandatory. Must be in the same namespace as the ScaledObject
envSourceContainerName: {container-name} # Optional. Default: .spec.template.spec.containers[0]
pollingInterval: 30 # Optional. Default: 30 seconds
cooldownPeriod: 300 # Optional. Default: 300 seconds
minReplicaCount: 0 # Optional. Default: 0
maxReplicaCount: 100 # Optional. Default: 100
advanced: # Optional. Section to specify advanced options
restoreToOriginalReplicaCount: true/false # Optional. Default: false
horizontalPodAutoscalerConfig: # Optional. Section to specify HPA related options
behavior: # Optional. Use to modify HPA's scaling behavior
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
triggers:
# {list of triggers to activate scaling of the target resource}
Спецификация масштабируемого задания
В качестве альтернативы масштабированию управляемого событиями кода в качестве развертываний можно также запускать и масштабировать код как задание Kubernetes. Основная причина, по которой следует рассмотреть этот параметр, заключается в том, если необходимо обработать длительные выполнения. Вместо обработки нескольких событий в развертывании каждое обнаруженное событие планирует собственное задание Kubernetes. Этот подход позволяет обрабатывать каждое событие в изоляции и масштабировать число одновременных выполнений на основе количества событий в очереди.
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: {scaled-job-name}
spec:
jobTargetRef:
parallelism: 1 # [max number of desired pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
completions: 1 # [desired number of successfully finished pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
activeDeadlineSeconds: 600 # Specifies the duration in seconds relative to the startTime that the job may be active before the system tries to terminate it; value must be positive integer
backoffLimit: 6 # Specifies the number of retries before marking this job failed. Defaults to 6
template:
# describes the [job template](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/)
pollingInterval: 30 # Optional. Default: 30 seconds
successfulJobsHistoryLimit: 5 # Optional. Default: 100. How many completed jobs should be kept.
failedJobsHistoryLimit: 5 # Optional. Default: 100. How many failed jobs should be kept.
envSourceContainerName: {container-name} # Optional. Default: .spec.JobTargetRef.template.spec.containers[0]
maxReplicaCount: 100 # Optional. Default: 100
scalingStrategy:
strategy: "custom" # Optional. Default: default. Which Scaling Strategy to use.
customScalingQueueLengthDeduction: 1 # Optional. A parameter to optimize custom ScalingStrategy.
customScalingRunningJobPercentage: "0.5" # Optional. A parameter to optimize custom ScalingStrategy.
triggers:
# {list of triggers to create jobs}