Руководство по архитектуре журнала транзакций SQL Server и управлению
Применимо:![]() SQL Server
SQL Server![]() База данных SQL Azure Управляемый экземпляр SQL Azure
База данных SQL Azure Управляемый экземпляр SQL Azure ![]()
![]() базе данных SQL Azure Synapse Analytics Analytics
базе данных SQL Azure Synapse Analytics Analytics ![]() Platform System (PDW)
Platform System (PDW) ![]() в Microsoft Fabric
в Microsoft Fabric
Каждая база данных SQL Server содержит журнал транзакций, который записывает все транзакции и изменения базы данных, внесенные каждой транзакцией. Журнал транзакций является критически важным компонентом базы данных и, если возникает системный сбой, журнал транзакций может потребоваться для возврата базы данных в согласованное состояние. В этом руководстве приводятся сведения о физической и логической архитектуре журнала транзакций. Понимание архитектуры может помочь в повышении эффективности работы с журналами транзакций.
Логическая архитектура журнала транзакций
Журнал транзакций SQL Server работает логически, как если бы журнал транзакций был строкой записей журналов. Каждая запись журнала определяется порядковым номером журнала (LSN). Каждая новая запись добавляется в логический конец журнала с номером LSN, который больше номера LSN предыдущей записи. Записи журналов хранятся в последовательной последовательности при их создании, например, если LSN2 больше LSN1, изменение, описанное записью журнала, на которую ссылается LSN2, произошло после изменения, описанного записью журнала LSN1. Каждая запись журнала содержит идентификатор транзакции, к которой она относится. Все записи журнала, связанные с определенной транзакцией, с помощью обратных указателей связаны в цепочку, которая предназначена для ускорения отката транзакции.
Базовая структура LSN — [VLF ID:Log Block ID:Log Record ID]это . Дополнительные сведения см. в разделах блока VLF и журналов .
Ниже приведен пример LSN: 00000031:00000da0:0001где 0x31 идентификатор VLF, 0xda0 является идентификатором блока журнала и 0x1 является первой записью журнала в этом блоке журнала. Примеры LSN, просмотрите выходные данные sys.dm_db_log_info dmV и проверьте vlf_create_lsn столбец.
Записи журнала для изменений данных записывают либо выполненную логическую операцию, либо записывают их до и после изображений измененных данных. Перед выполнением операции изображение является копией данных; после выполнения операции изображение является копией данных после выполнения операции.
Действия, которые необходимо выполнить для восстановления операции, зависят от типа журнальной записи:
Зарегистрирована логическая операция.
- Чтобы выполнить перекат логической операции, операция выполняется снова.
- Чтобы откатить логическую операцию, выполняется обратная логическая операция.
Зарегистрированы исходный и результирующий образы записи.
- Для переката операции применяется образ после применения.
- Чтобы откатить операцию, перед применением образа.
В журнал транзакций записываются различные типы операций, например:
начало и конец каждой транзакции;
любые изменения данных (вставка, обновление или удаление), Изменения включают изменения системных хранимых процедур или инструкций языка определения данных (DDL) в любую таблицу, включая системные таблицы.
любое выделение и освобождение страниц и экстентов;
создание и удаление таблиц и индексов.
Кроме того, регистрируются операции отката. Каждая транзакция резервирует пространство в журнале транзакций, чтобы убедиться, что достаточно места журнала существует для поддержки отката, вызванного явным оператором отката или при возникновении ошибки. Объем зарезервированного пространства зависит от операций, выполняемых в транзакции, но обычно это равно количеству пространства, используемого для регистрации каждой операции. Все это пространство после завершения транзакции освобождается.
Раздел файла журнала из первой записи, который должен присутствовать для успешного отката всей базы данных к последней зарегистрированной записи называется активной частью журнала, активным журналом или заключительным фрагментом журнала. Этот раздел журнала необходим для полного восстановления базы данных. Ни одна часть активного журнала не может быть усечена. Регистрационный номер транзакции в журнале (LSN) этой первой записи журнала называется минимальным номером LSN восстановления (MinLSN). Дополнительные сведения об операциях, поддерживаемых журналом транзакций, см. в журнале транзакций.
Разностные резервные копии и резервные копии журналов продвигают восстанавливаемую базу данных к более позднему моменту, которому соответствует больший регистрационный номер транзакции в журнале.
Физическая архитектура журнала транзакций
Журнал транзакций базы данных сопоставляется с одним или несколькими физическими файлами. По сути, файл журнала представляет собой строку записей журнала. Физически последовательность записей журнала эффективно хранится в наборе физических файлов, которые образуют журнал транзакций. Для каждой базы данных должен существовать хотя бы один файл журнала.
Виртуальные файлы журнала (VLF)
SQL Server ядро СУБД делит каждый физический файл журнала на несколько виртуальных файлов журналов (VLFs). Виртуальные файлы журнала не имеют фиксированного размера, и для физического файла журнала не установлено фиксированное количество файлов виртуальных журналов. Ядро СУБД динамически выбирает размер файлов виртуальных журналов при создании или расширении файлов журналов. Ядро СУБД пытается сохранить несколько виртуальных файлов. После расширения файла журнала размер виртуальных файлов определяется как сумма размера существующего журнала и размера нового приращения файла. Размер или количество виртуальных файлов журналов не может быть настроено или задано администраторами.
Создание файла виртуального журнала
Для создания виртуального файла журнала (VLF) используется следующий метод.
- В SQL Server 2014 (12.x) и более поздних версиях, если следующий рост меньше 1/8 текущего физического размера журнала, создайте 1 VLF, охватывающий размер роста.
- Если следующий рост превышает 1/8 текущего размера журнала, используйте метод до 2014 года, а именно:
- Если рост меньше 64 МБ, создайте 4 VLFs, охватывающие размер роста (например, для роста в 1 МБ, создайте 4 VLFs размером 256 КБ).
- В База данных SQL Azure и начиная с SQL Server 2022 (16.x) (все выпуски), логика немного отличается. Если рост меньше или равен 64 МБ, ядро СУБД создает только один VLF для покрытия размера роста.
- Если рост составляет от 64 МБ до 1 ГБ, создайте 8 VLFs, охватывающие размер роста (например, для роста в 512 МБ, создайте 8 VLFs размером 64 МБ).
- Если рост превышает 1 ГБ, создайте 16 VLFs, которые охватывают размер роста, например для роста в 8 ГБ, создайте 16 VLFs размером 512 МБ).
- Если рост меньше 64 МБ, создайте 4 VLFs, охватывающие размер роста (например, для роста в 1 МБ, создайте 4 VLFs размером 256 КБ).
Если файлы журналов увеличиваются до большого размера во многих небольших добавках, они в конечном итоге получают множество виртуальных файлов журналов. Это может замедлить запуск базы данных, операции резервного копирования журналов и восстановления, а также вызвать задержку повтора транзакций или CDC и Always On. И наоборот, если файлы журнала имеют большой размер с несколькими или одним шагом, они содержат несколько очень больших виртуальных файлов журнала. Дополнительные сведения о правильном оценке требуемого размера и параметра автоматического увеличения журнала транзакций см. в разделе "Рекомендации" раздела "Управление размером файла журнала транзакций".
Рекомендуется создать файлы журнала близко к окончательному размеру, используя приращения, необходимые для достижения оптимального распределения VLF, и иметь относительно большое значение growth_increment .
Ознакомьтесь со следующими советами, чтобы определить оптимальное распределение VLF для текущего размера журнала транзакций:
- Значение размера, заданное
SIZEаргументомALTER DATABASE, является начальным размером файла журнала. - Значение growth_increment (также известное как значение автоматического увеличения), которое
FILEGROWTHаргумент наборовALTER DATABASE, является объемом пространства, добавленного в файл каждый раз, когда требуется новое пространство.
Дополнительные сведения и аргументы см. в FILEGROWTH SIZE разделе ALTER DATABASE (Transact-SQL) File and Filegroup Options.ALTER DATABASE
Совет
Чтобы определить оптимальное распределение VLF для текущего размера журнала транзакций всех баз данных в данном экземпляре, а также необходимый рост для достижения требуемого размера, см. этот скрипт Fixing-VLFs на GitHub.
Что происходит, когда у вас слишком много VLFs?
На начальных этапах процесса восстановления базы данных SQL Server обнаруживает все VLFs во всех файлах журнала транзакций и создает список этих VLFs. Этот процесс может занять много времени в зависимости от количества VLFS, присутствующих в конкретной базе данных. Чем больше VLFs, тем дольше процесс. База данных может в конечном итоге с большим количеством VLFs, если частый рост журнала транзакций или ручного роста обнаружен в небольших добавках. Когда число VLFs достигает диапазона в несколько сотен тысяч, вы можете столкнуться с некоторыми или большинством следующих симптомов:
- Одно или несколько баз данных занимает очень много времени, чтобы завершить восстановление во время запуска SQL Server.
- Восстановление базы данных занимает очень много времени.
- Попытки присоединения базы данных занять очень много времени.
- При попытке настроить зеркальное отображение базы данных возникают сообщения об ошибках 1413, 1443 и 1479, указывающие время ожидания.
- При попытке восстановить базу данных возникают ошибки, связанные с памятью, такие как 701.
- Репликация транзакций или запись измененных данных могут столкнуться с значительной задержкой.
При проверке журнала ошибок SQL Server вы можете заметить, что до этапа анализа процесса восстановления базы данных может потребоваться значительное время. Например:
2022-05-08 14:42:38.65 spid22s Starting up database 'lot_of_vlfs'.
2022-05-08 14:46:04.76 spid22s Analysis of database 'lot_of_vlfs' (16) is 0% complete (approximately 0 seconds remain). Phase 1 of 3. This is an informational message only. No user action is required.
Кроме того, SQL Server может регистрировать ошибку MSSQLSERVER_9017 при восстановлении базы данных с большим количеством VLFs:
Database %ls has more than %d virtual log files which is excessive. Too many virtual log files can cause long startup and backup times. Consider shrinking the log and using a different growth increment to reduce the number of virtual log files.
Дополнительные сведения см. в MSSQLSERVER_9017.
Исправление баз данных с большим количеством VLFs
Чтобы сохранить общее количество VLFs в разумной сумме, например не более нескольких тысяч, можно сбросить файл журнала транзакций, чтобы содержать меньшее количество VLFs, выполнив следующие действия:
Сжатие файлов журнала транзакций вручную.
Выращивайте файлы до требуемого размера вручную на одном шаге с помощью следующего скрипта T-SQL:
ALTER DATABASE <database name> MODIFY FILE (NAME='Logical file name of transaction log', SIZE = <required size>);Примечание.
Этот шаг также можно выполнить в SQL Server Management Studio с помощью страницы свойств базы данных.
После установки нового макета файла журнала транзакций с меньшим количеством VLFS просмотрите и внесите необходимые изменения в параметры автоматического увеличения журнала транзакций. Эта проверка параметров гарантирует, что файл журнала не сталкивается с той же проблемой в будущем.
Перед выполнением любой из этих операций убедитесь, что у вас есть действительная резервная копия, которую можно восстановить, если возникли проблемы позже.
Чтобы определить оптимальное распределение VLF для текущего размера журнала транзакций всех баз данных в данном экземпляре, а также необходимый рост для достижения требуемого размера, можно использовать следующий сценарий GitHub для исправления VLFs.
Блоки журналов
Каждый VLF содержит один или несколько блоков журнала. Каждый блок журнала состоит из записей журнала (выровненных по границе 4-байтов). Блок журнала является переменной в размере и всегда является целым числом в 512 байтах (минимальный размер SQL Server поддерживает) с максимальным размером 60 КБ. Блок журнала — это базовая единица ввода-вывода для ведения журнала транзакций.
В итоге блок журнала — это контейнер записей журнала, используемых в качестве основной единицы ведения журнала транзакций при записи записей журнала на диск.
Каждый блок журнала в VLF однозначно решается с помощью смещения блока. Первый блок всегда имеет смещение блока, которое указывает на первое 8 КБ в VLF.
Как правило, VLF всегда заполняется блоками журналов. Возможно, что последний блок журнала в VLF пуст (например, не содержит записей журнала). Это происходит, когда записываемая запись журнала не помещается в текущий блок журнала, а также когда свободное место в VLF недостаточно для хранения этой записи журнала. В этом случае создается пустой блок журнала, который заполняет VLF. Запись журнала вставляется в первый блок на следующем VLF.
Циклическая природа журнала транзакций
Журнал транзакций является оборачиваемым файлом. Рассмотрим пример. Пусть база данных имеет один физический файл журнала, разделенный на четыре виртуальных файла журнала. При создании базы данных логический файл журнала начинается в начале физического файла журнала. Новые записи журнала добавляются в конце логического журнала и приближаются к концу физического файла журнала. Усечение журнала освобождает любые виртуальные журналы, все записи которых находятся перед минимальным регистрационным номером восстановления в журнале транзакций (MinLSN). MinLSN — это регистрационный номер транзакции самой старой записи в журнале, которая необходима для успешного отката на уровне всей базы данных. Журнал транзакций в примере базы данных будет выглядеть примерно так, как на следующей схеме.
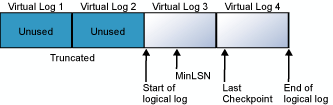
Когда конец логического журнала достигнет конца физического файла журнала, новые записи журнала будут размещаться в начале физического файла журнала.
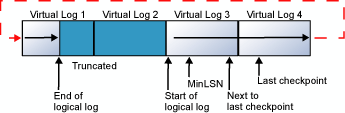
Этот цикл повторяется бесконечно, пока конец логического журнала не совмещается с началом этого логического журнала. Если старые записи журнала усекаются достаточно часто, так что при этом всегда остается место для новых записей журнала, созданных с новой контрольной точки, журнал постоянно остается незаполненным. Однако, если конец логического журнала совмещается с началом этого логического журнала, происходит одно из двух событий, перечисленных ниже.
FILEGROWTHЕсли параметр включен для журнала и пространства доступен на диске, файл расширяется по количеству, указанному в параметре growth_increment, а новые записи журнала добавляются в расширение. Дополнительные сведения о параметреFILEGROWTHсм. в разделе ALTER DATABASE (Transact-SQL) File и Filegroup Options.FILEGROWTHЕсли параметр не включен или диск, содержащий файл журнала, имеет меньше свободного места, чем сумма, указанная в growth_increment, создается ошибка 9002. Дополнительные сведения см. в разделе "Устранение неполадок с полным журналом транзакций( ошибка SQL Server 9002)".
Если журнал содержит несколько физических файлов журналов, логический журнал перемещается по всем физическим файлам журнала, прежде чем он будет возвращен к началу первого физического файла журнала.
Внимание
Дополнительные сведения об управлении размером журнала транзакций см. в разделе "Управление размером файла журнала транзакций".
Усечение журнала
Усечение журнала необходимо для предотвращения переполнения журнала. Усечение журнала удаляет неактивные файлы виртуального журнала из логического журнала транзакций базы данных SQL Server, освобождая место в логическом журнале для повторного использования физическим журналом транзакций. Если журнал транзакций никогда не усечен, он в конечном итоге заполняет все дисковое пространство, выделенное для его физических файлов журнала. Однако перед усечением журнала должна быть выполнена операция создания контрольной точки. Контрольная точка записывает текущие измененные страницы в памяти (известные как грязные страницы) и данные журнала транзакций из памяти на диск. При создании контрольной точки неактивная часть журнала транзакций помечается как неиспользуемая, После этого усечение журнала может освободить неактивную часть. Дополнительные сведения о контрольных точках см. в разделе "Контрольные точки базы данных" (SQL Server).
На следующих схемах показан журнал транзакций до и после усечения. На первой схеме показан журнал транзакций, который никогда не был усечен. В настоящий момент логический журнал состоит из четырех виртуальных файлов. Логический журнал начинается с первого файла виртуального журнала и заканчивается виртуальным файлом журнала 4. Запись MinLSN находится в виртуальном журнале 3. Виртуальные журналы 1 и 2 содержат только неактивные записи журнала. Эти записи можно усечь. Виртуальный журнал 5 по-прежнему не используется и не является частью текущего логического журнала.
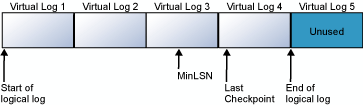
На второй схеме показано, как появляется журнал после усечения. Виртуальные журналы 1 и 2 усечены и могут использоваться повторно. Логический журнал теперь начинается с виртуального журнала 3. Виртуальный журнал 5 по-прежнему не используется, и он не является частью текущего логического журнала.
За исключением тех случаев, когда усечение журнала по каким-то причинам задерживается, оно выполняется автоматически после наступления следующих событий.
- В простой модели восстановления — после достижения контрольной точки.
- В модели полного восстановления или в модели восстановления с неполным протоколированием — после создания резервной копии журналов, при условии, что со времени предыдущей операции резервного копирования была достигнута контрольная точка.
Усечение журнала может быть отложено различными факторами. В случае большой задержки усечения журнала возможно заполнение журнала транзакций. Дополнительные сведения см. в разделе "Факторы, которые могут отложить усечение журнала журналов и устранить неполадки с полным журналом транзакций( ошибка SQL Server 9002)".
Журнал транзакций перед записью
В этом разделе описана роль, которую журнал транзакций с упреждающей записью играет в записи изменений данных на диск. SQL Server использует алгоритм ведения журнала на основе записи (WAL), который гарантирует, что изменения данных не записываются на диск, прежде чем связанная запись журнала записывается на диск. Таким образом обеспечиваются свойства ACID для транзакции.
Дополнительные сведения о WAL см . в основных принципах ввода-вывода SQL Server.
Чтобы понять, как работает ведение журнала операций записи в отношении журнала транзакций, важно знать, как измененные данные записываются на диск. SQL Server поддерживает кэш буфера (также называемый буферным пулом), в который он считывает страницы данных при извлечении данных. При изменении страницы в кэше буфера она не сразу записывается на диск; Вместо этого страница помечена как грязная. На странице данных может быть несколько логических записей, прежде чем они физически записываются на диск. При каждой логической операции записи в кэш журнала, который записывает изменения, добавляется запись журнала транзакций. Записи журнала должны быть перенесены на диск до того, как соответствующая «грязная» страница будет удалена из буферного кэша и записана на диск. Заключается в том, что процесс контрольных точек производит периодический просмотр буферного кэша на наличие буферов со страницами определенной базы данных и запись всех «грязных» страниц на диск. Контрольные точки экономят время во время последующего восстановления при помощи создания точки, в которой все «грязные» страницы гарантированно записываются на диск.
Запись измененной страницы данных из буферного кэша на диск называется сбросом страницы на диск. SQL Server имеет логику, которая предотвращает очистку грязной страницы до записи связанной записи журнала. Содержимое журнала записывается на диск при сбросе буферов журнала. Это происходит при фиксации транзакции или заполнении буферов журнала.
Резервное копирование журналов транзакций
Этот раздел содержит основные понятия о создании резервной копии и восстановлении журналов транзакций. В рамках модели полного восстановления или восстановления с неполным протоколированием для восстановления данных важно регулярно создавать резервные копии журнала транзакций (резервные копии журнала). Можно создать резервную копию журнала во время выполнения полного резервного копирования. Дополнительные сведения о моделях восстановления см. в статье Резервное копирование и восстановление баз данных SQL Server.
Перед созданием первой резервной копии журнала необходимо создать полную резервную копию данных, например резервную копию базы данных или первую в наборе резервную копию файлов. Восстановить базу данных исключительно из резервных копий файлов может оказаться довольно сложно. Поэтому рекомендуется начинать резервирование с создания полной резервной копии базы данных. После этого необходимо регулярное создание резервных копий журнала транзакций. Это не только уменьшит вероятность потери данных, но и даст возможность производить усечение журнала транзакций. Обычно он усекается после каждого обычного резервного копирования журналов,
Внимание
Рекомендуем создавать резервные копии журналов с достаточной периодичностью в соответствии с вашими бизнес-требованиями, в особенности касающимися устойчивости к потере данных, что может произойти из-за повреждения хранилища журналов.
Частота создания резервных копий журнала зависит от степени толерантности к возможности потери данных и от того, какое количество резервных копий журнала получится хранить и в потенциале восстанавливать, а также каким количеством управлять. Думайте о требуемом целевом времени восстановления (RTO) и целевой точке восстановления (RPO) при реализации стратегии восстановления и, в частности, о времени резервного копирования журналов. Возможно, создания резервных копий журналов один раз в 15-30 минут может оказаться достаточно. Если предприятию необходимо минимизировать вероятность потери данных, следует увеличить частоту создания резервных копий журнала. Более частое создание резервных копий журнала предоставляет преимущество за счет более частого усечения журнала, результатом которого является меньший размер файлов журнала.
Чтобы ограничить количество резервных копий журналов, необходимых для восстановления, необходимо регулярно создавать резервные копии данных. Например, можно запланировать еженедельное создание полной резервной копии базы данных и ежедневное создание разностных резервных копий.
Думайте о требуемом RTO и RPO при реализации стратегии восстановления, а также о полной и разностной частотой резервного копирования базы данных.
Дополнительные сведения о резервных копиях журналов транзакций см. в статье "Резервные копии журналов транзакций" (SQL Server).
Цепочка журналов
Непрерывная последовательность резервных копий журналов называется цепочкой журналов. Цепочка журналов начинается с полной резервной копии базы данных. Обычно новая цепочка журналов запускается только при первом резервном копировании базы данных или после перехода модели восстановления с простого восстановления на полное или массовое восстановление. Существующая цепочка журналов остается без изменений, если не выбрана перезапись существующих наборов резервных копий при создании резервной копии базы данных целиком. Сохраняя неизменность цепочки журналов, базу данных можно восстановить из любой резервной копии полной базы данных в любом наборе носителей и из всех последующих резервных копий журналов до точки восстановления. Точка восстановления может быть концом последней резервной копии журналов или определенной точкой восстановления в любой из резервных копий журналов. Дополнительные сведения см. в статье о резервных копиях журналов транзакций (SQL Server).
Чтобы восстановить базу данных на момент точки сбоя, нужна неповрежденная цепочка журналов. Непрерывная последовательность резервных копий журналов должна следовать до точки сбоя. Где должна начинаться эта последовательность журналов, зависит от типа резервных копий данных, которые вы восстанавливаете: база данных, частичный или файл. В случае резервной копии базы данных или частичной резервной копии последовательность резервных копий журнала должна начинаться от конца резервной копии базы данных или частичной резервной копии. В наборе резервных копий файлов последовательность резервных копий журналов должна следовать от начала полного набора резервных копий файлов. Дополнительные сведения см. в разделе Применение резервных копий журналов транзакций (SQL Server).
Восстановление резервных копий журналов
Восстановление резервного копирования журналов выполняет переадресацию изменений, записанных в журнале транзакций, чтобы воссоздать точное состояние базы данных во время запуска операции резервного копирования журналов. При восстановлении базы данных необходимо восстановить резервные копии журналов, созданные после полной резервной копии базы данных, которую вы восстановите, или с начала первой резервной копии файла, которую вы восстанавливаете. Обычно после восстановления последней резервной копии данных или разностной резервной копии необходимо произвести восстановление серии резервных копий журналов до точки восстановления. Затем производится восстановление базы данных. При этом откатываются все незавершенные на момент восстановления транзакции, и база данных переводится в режим «в сети». После восстановления базы данных больше не удается восстановить резервные копии. Дополнительные сведения см. в разделе Применение резервных копий журналов транзакций (SQL Server).
Контрольные точки и активная часть журнала
При достижении контрольных точек измененные страницы данных записываются из буферного кэша текущей базы данных на диск. Это сводит к минимуму активную часть журнала, которую приходится обрабатывать при полном восстановлении базы данных. Во время полного восстановления базы данных выполняются следующие действия.
- Накат записанных в журнал изменений, не записанных на диск до остановки системы.
- Все изменения, связанные с неполными транзакциями, например транзакции, для которых нет записи журнала COMMIT или ROLLBACK, откатываются.
Операция контрольной точки
Контрольная точка выполняет в базе данных следующее.
Записывает в файл журнала запись, отмечающую начало контрольной точки.
Сохраняет данные, записанные для контрольной точки в цепи записей журнала контрольной точки.
Одним из элементов данных, регистрируемых в записях контрольной точки, является номер LSN первой записи журнала, при отсутствии которой успешный откат в масштабе всей базы данных невозможен. Такой номер LSN называется минимальным номером LSN восстановления (MinLSN). Номер MinLSN является наименьшим значением из:
- номера LSN начала контрольной точки;
- номера LSN начала старейшей активной транзакции;
- LSN начала самой старой транзакции репликации, которая еще не была доставлена в базу данных распространителя.
Записи контрольной точки содержат также список активных транзакций, изменивших базу данных.
Если база данных использует простую модель восстановления, помечает для повторного использования пространство, предшествующее номеру MinLSN.
Записывает все измененные страницы журналов и данных на диск.
Записывает в файл журнала запись, отмечающую конец контрольной точки.
Записывает в страницу загрузки базы данных номер LSN начала соответствующей цепи.
Действия, вызывающие контрольную точку
Контрольные точки срабатывают в следующих ситуациях.
- При явном выполнении инструкции CHECKPOINT. Контрольная точка срабатывает в текущей базе данных соединения.
- При выполнении в базе данных операции с минимальной регистрацией, например при выполнении операции массового копирования для базы данных, на которую распространяется модель восстановления с неполным протоколированием.
- При добавлении или удалении файлов баз данных с использованием инструкции ALTER DATABASE.
- При остановке экземпляра SQL Server инструкцией SHUTDOWN или при остановке службы SQL Server (MSSQLSERVER). И в том, и в другом случае будет создана контрольная точка для каждой базы данных на экземпляре SQL Server.
- Экземпляр SQL Server периодически создает для каждой базы данных автоматические контрольные точки с целью сократить время восстановления базы данных.
- При создании резервной копии базы данных.
- При выполнении действия, требующего отключения базы данных. Это может произойти, когда параметр AUTO_CLOSE включен, а последнее подключение пользователя к базе данных закрыто. Еще одним примером является изменение параметра базы данных, требующее перезапуска базы данных.
Автоматические контрольные точки
Ядро СУБД SQL Server создает автоматические контрольные точки. Интервал между автоматическими контрольными точками определяется на основе использованного места в журнале и времени, прошедшего с момента создания последней контрольной точки. Интервал времени между автоматическими контрольными точками колеблется в широких пределах и может быть довольно длительным, если база данных изменяется редко. При крупномасштабных изменениях данных частота автоматических контрольных точек может быть гораздо выше.
Используйте параметр конфигурации сервера recovery interval , чтобы вычислить интервал между автоматическими контрольными точками для всех баз данных на экземпляре сервера. Значение этого параметра определяет максимальное время, отводимое ядру СУБД на восстановление базы данных при перезапуске системы. Ядро СУБД оценивает число записей журнала, которые оно может обработать за время recovery interval в ходе операции восстановления.
Кроме того, интервал между автоматическими контрольными точками зависит от модели восстановления, как показано ниже.
Если применяется полная модель восстановления или модель восстановления с неполным протоколированием, то автоматическая контрольная точка создается каждый раз, когда число записей в журнале достигает значения, определенного ядром СУБД в качестве предельного количества записей, которое оно может обработать за время, заданное параметром recovery interval.
Если используется простая модель восстановления базы данных, автоматическая контрольная точка создается каждый раз, когда число записей в журнале достигает меньшего из двух предельных условий:
- журнал заполняется на 70 процентов;
- число записей в журнале достигает значения, определенного ядром СУБД в качестве количества записей, которое оно может обработать за время, заданное параметром recovery interval.
Сведения о настройке интервала восстановления см. в разделе Настройка интервала восстановления (min) (параметр конфигурации сервера).
Совет
Параметр -k расширенной настройки SQL Server позволяет администратору базы данных регулировать поведение операций ввода-вывода на основе пропускной способности подсистемы ввода-вывода для некоторых типов контрольных точек. Параметр -k установки применяется к автоматическим контрольным точкам и любым другим неуправляемых контрольных точек.
Если используется простая модель восстановления базы данных, то при срабатывании автоматических контрольных точек неиспользуемая часть журнала транзакций удаляется. Однако если база данных использует полные или массовые модели восстановления, журнал не усечен автоматическими контрольными точками. Дополнительные сведения см. в журнале транзакций.
Инструкция CHECKPOINT теперь поддерживает необязательный аргумент checkpoint_duration, определяющий время (в секундах), отводимое контрольным точкам на завершение. Дополнительные сведения см. в статье CHECKPOINT.
Активный журнал
Часть файла журнала, начинающаяся с номера MinLSN и заканчивающаяся последней зафиксированной записью, называется активной частью журнала или "активным журналом". Этот раздел журнала необходим для выполнения полного восстановления базы данных. Ни одна часть активного журнала не может быть усечена. Все записи журнала до номера MinLSN должны быть удалены из частей журнала.
На следующей схеме показана упрощенная версия журнала транзакций конца транзакции с двумя активными транзакциями. Записи контрольных точек были сжаты в одну запись.

Последней записью в журнале транзакций является запись с номером LSN, равным 148. На момент обработки записанной контрольной точки с номером LSN 147 транзакция 1 уже зафиксирована и единственной активной транзакцией является транзакция 2. В результате первая запись журнала, созданная для транзакции 2, становится старейшей записью активной транзакции на момент последней контрольной точки. Таким образом, номером MinLSN становится номер LSN, равный 142 и соответствующий записи начала транзакции 2.
Продолжительные транзакции
Активный журнал должен включать в себя все элементы всех незафиксированных транзакций. Приложение, которое запускает транзакцию и не фиксирует ее или откат не позволяет ядро СУБД продвигать minLSN. Эта ситуация может привести к двум типам проблем:
- Если система будет выключена после того, как транзакцией было выполнено много незафиксированных изменений, этап восстановления при последующем перезапуске может занять гораздо больше времени, чем задано параметром recovery interval .
- Журнал может увеличиться очень большой, так как журнал не может быть усечен мимо MinLSN. Это происходит даже в том случае, если база данных использует простую модель восстановления, в которой журнал транзакций усечен на каждой автоматической контрольной точке.
Восстановление длительных транзакций и проблем, описанных в этой статье, можно избежать с помощью ускоренного восстановления базы данных, функции, доступной начиная с SQL Server 2019 (15.x) и в База данных SQL Azure.
Транзакции репликации
Агент чтения журнала следит за журналом транзакций всех баз данных, на которых настроена репликация транзакций, и копирует отмеченные для репликации транзакции из журнала транзакций в базу данных распространителя. Активный журнал должен содержать все транзакции, помеченные для репликации, но которые еще не были доставлены в базу данных распространителя. Если эти транзакции не реплицируются своевременно, они могут предотвратить усечение журнала. Дополнительные сведения см. в статье Репликация транзакций.
Связанный контент
- Журнал транзакций
- Управление размером файла журнала транзакций
- Резервные копии журналов транзакций (SQL Server)
- Контрольные точки базы данных (SQL Server)
- Настройка интервала восстановления (мин) (параметр конфигурации сервера)
- Ускоренное восстановление баз данных
- sys.dm_db_log_info (Transact-SQL)
- sys.dm_db_log_space_usage (Transact-SQL)
- Основные сведения о ведении журнала и восстановлении из резервных копий в SQL Server. Автор: Пол Рендел (Paul Randal)
- Управление журналом транзакций SQL Server. Авторы: Тони Дэвис (Tony Davis) и Гейл Шоу (Gail Shaw)